Dieser Intelligenztest vergleicht Maschinen und Menschen
Der KI-Forscher François Chollet hat das KI-Framework Keras gebaut. Jetzt schließt er sich der Jagd nach der Super-KI an.
François Chollet ist KI-Forscher bei Google und Autor des weit verbreiteten Deep-Learning-Frameworks Keras für die Programmiersprache Python. Keras wird weltweit von Forschern genutzt und ist mittlerweile in Googles TensorFlow integriert.
Chollets neuste Arbeit trägt den Titel "The Measure of Intelligence". Darin entwickelt der Forscher eine Definition und Benchmarks für Intelligenz. Chollet möchte so die Intelligenz zweier Systeme vergleich- und testbar machen, weil er darin eine wesentliche Voraussetzung für die Entwicklung einer generellen Künstlichen Intelligenz sieht.
Aktuell gebe es weder eine vernünftige Definition noch aussagekräftige Tests für Intelligenz, sagt Chollet. Zeitgenössische KI-Forscher setzten Intelligenz immer noch mit gewissen Fähigkeiten gleich, wie das Abschneiden in Brett- oder Videospielen.
Doch allein die Fähigkeit, eine Aufgabe zu lösen, reiche nicht aus, um Intelligenz zu messen. Denn das Können einer Spiele-KI sei stark durch Wissen und Erfahrung bestimmt. Beides könnten KI-Systeme durch ausuferndes Training oder einprogrammiertes Wissen erreichen. Das sage aber nichts über die Fähigkeit des Systems zur Generalisierung aus.
Was kommt nach Schach?
Brettspiele wie Schach oder Videospiele wie Space Invaders eigenen sich daher nicht als Intelligenztest für Maschinen, meint Chollet. Da stimmt der Google-Forscher mit seinen Kollegen Gary Marcus und Tom Dietterich überein.
Für aussagekräftige Intelligenztests brauche es zunächst eine aussagekräftige Definition von Intelligenz. Chollet betont, er habe keinen Anspruch auf Vollständigkeit. Ihm gehe es darum, das Besondere an menschlicher Intelligenz zu definieren. Es gebe viele Formen von Intelligenz, doch auf dem Weg zu einer generellen KI müsse der Mensch das Vorbild sein, sagt Chollet.
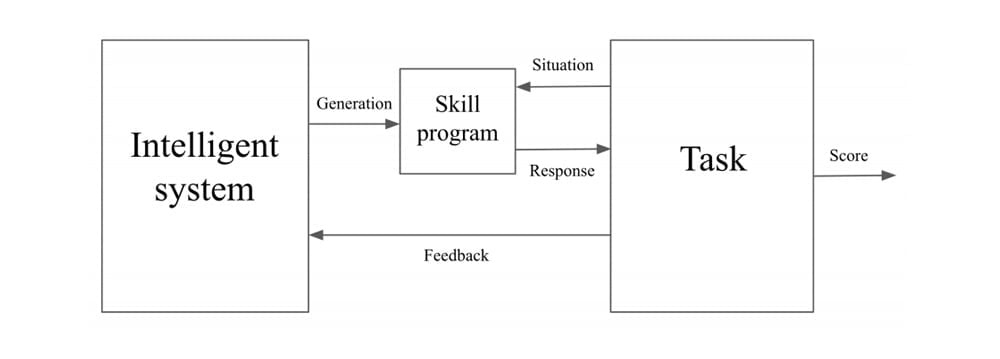
Intelligenz beschreibt Chollet als Effizienz beim Erwerb neuer Fähigkeiten: Je effizienter ein System eine neue Fähigkeit erlerne, desto intelligenter sei es. Beim Lernen helfen Abstraktion und logisches Denken.
Pixeltests für Mensch und KI
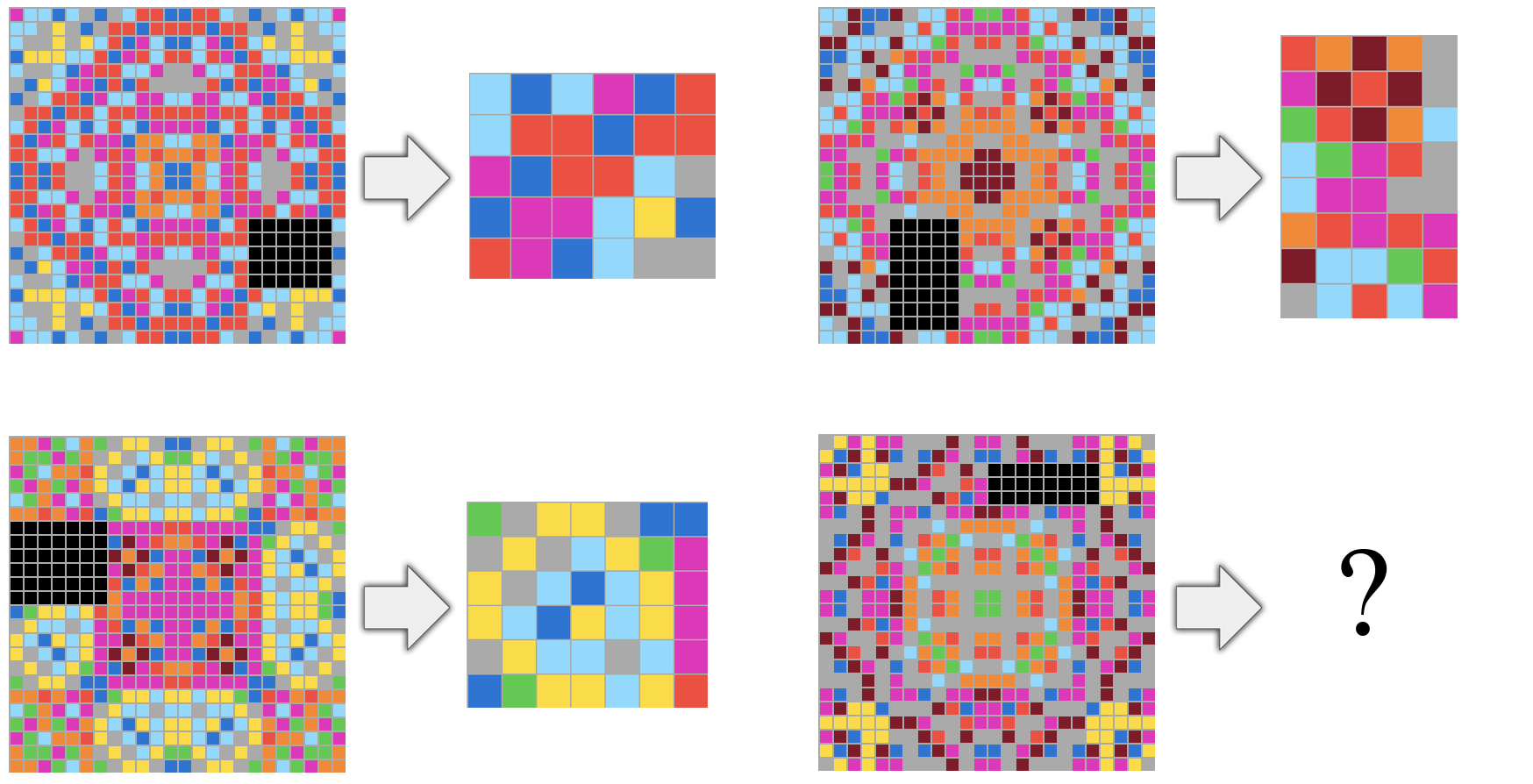
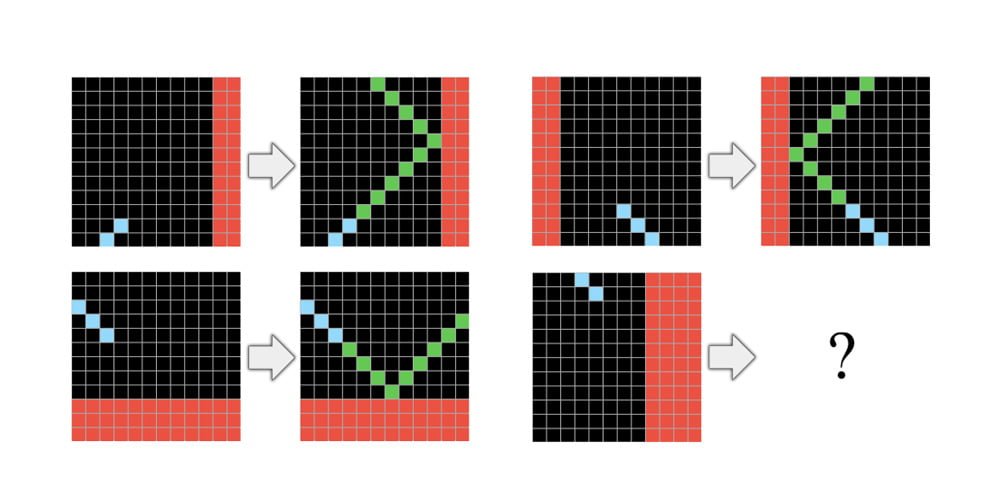
Aus dieser Definition von Intelligenz leitet Chollet eine Reihe von Aufgaben ab, die menschliche und künstliche Intelligenz vergleichbar machen sollen. In den Pixelbildern müssen Farbmuster vollendet, Objekte richtig herum angeordnet, Bilder repariert oder zielorientiertes Verhalten erkannt werden. Jeder Test wurde von mindestens einem Menschen erfolgreich beendet, schreibt Chollet.
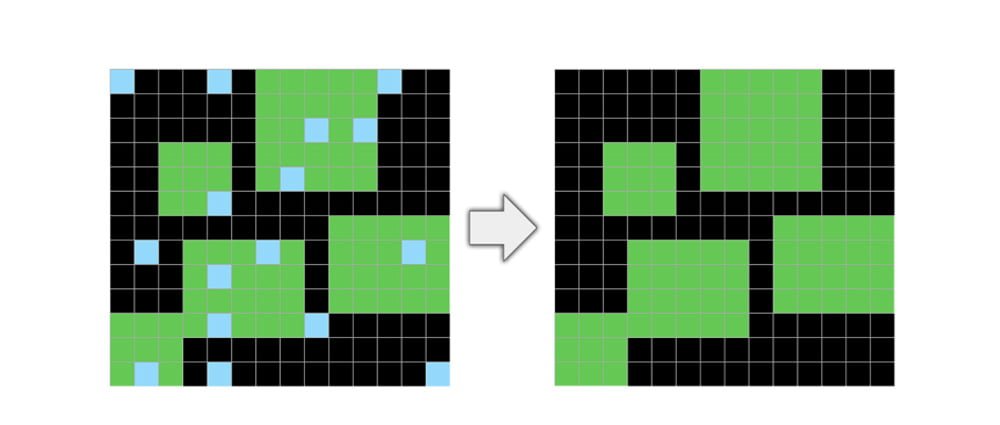
Alle Bestandteile des "Abstraction and Reasoning Corpus" (ARC) genannten Benchmarks sind auf Abstraktion und logisches Denken abgestimmt und vermeiden Sprache, Echtweltobjekte oder gesunden Menschenverstand. Das soll einen hohen Grad der Abstraktion sicherstellen.
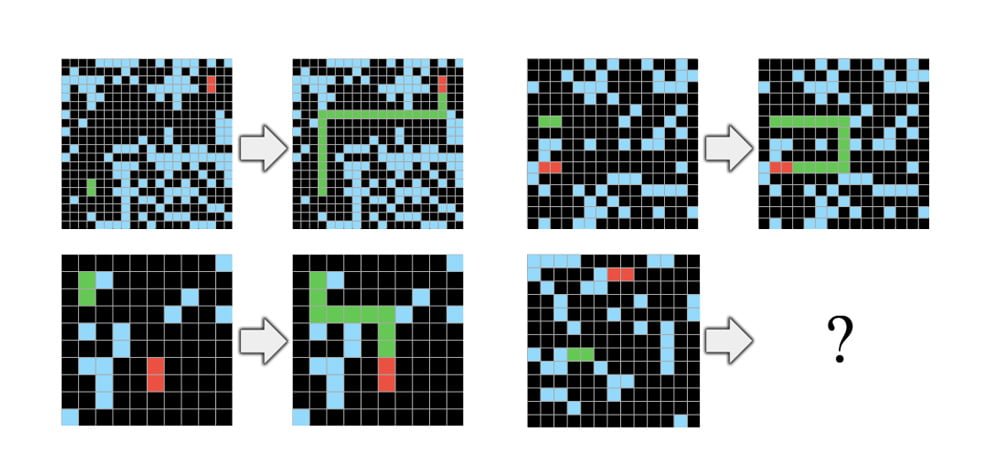
Chollets Test ist Grundlagenforschung: Ob eine KI, die seinen Benchmark löst, tatsächlich zur generellen Künstlichen Intelligenz taugt, ist fraglich. Das meint auch Chollet: Er möchte weiter an seinen Tests feilen. Er selbst arbeite an einer KI, die bereits einige der Tests bestehe, schreibt er bei Twitter.
Er hofft, dass der ARC-Test KI-Forscher, die an genereller KI arbeiten, zum Umdenken bringt: Sie sollen weg vom aktuellen Ansatz, Menschen in einzelnen Aufgaben zu überbieten, und hin zur Entwicklung menschenähnlicher kognitiver Begabung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.