Googles MLE-STAR soll komplexe Machine-Learning-Pipelines automatisieren

MLE-STAR von Google Research kombiniert Websuche, gezieltes Code-Refinement und neue Ensemble-Strategien, um maschinelles Lernen weitgehend zu automatisieren. Erste Ergebnisse zeigen Leistungsgewinne bei minimalem menschlichen Input.
Mit MLE-STAR präsentiert Google Research einen neuen KI-Agenten, der maschinelles Lernen automatisieren und gleichzeitig die Leistung bestehender Ansätze deutlich übertreffen soll. Ziel des Systems ist es, anspruchsvolle ML-Aufgaben in verschiedenen Datenmodalitäten mit minimalem menschlichen Aufwand zu lösen, etwa durch die Generierung ausführbarer Python-Skripte auf Basis einer Aufgabenbeschreibung und bereitgestellter Daten.
Laut Google Research greifen bisherige MLE-Agenten meist auf bekannte Methoden wie scikit-learn zurück und zeigen wenig Flexibilität bei der Erkundung alternativer Modelle oder Pipeline-Komponenten. Zudem ändern sie häufig die gesamte Codebasis auf einmal, was eine gezielte Optimierung einzelner Schritte – etwa beim Feature Engineering – erschwert.
Websuche statt Trial-and-Error
MLE-STAR setzt auf ein mehrstufiges Verfahren: Zunächst nutzt der Agent eine Websuche, um geeignete, aktuelle Modellansätze zu identifizieren. Auf dieser Basis generiert er einen initialen Lösungsvorschlag. Im nächsten Schritt wird analysiert, welcher Codeblock (z. B. Feature Engineering, Modellwahl, Ensemble-Bildung) die größte Auswirkung auf die Modellleistung hat.
Anschließend verfeinert der Agent gezielt diesen Block iterativ, basierend auf Feedback vorangegangener Experimente. Dieser Prozess wiederholt sich, wobei jeweils das verbesserte Skript die Grundlage für die nächste Iteration bildet.
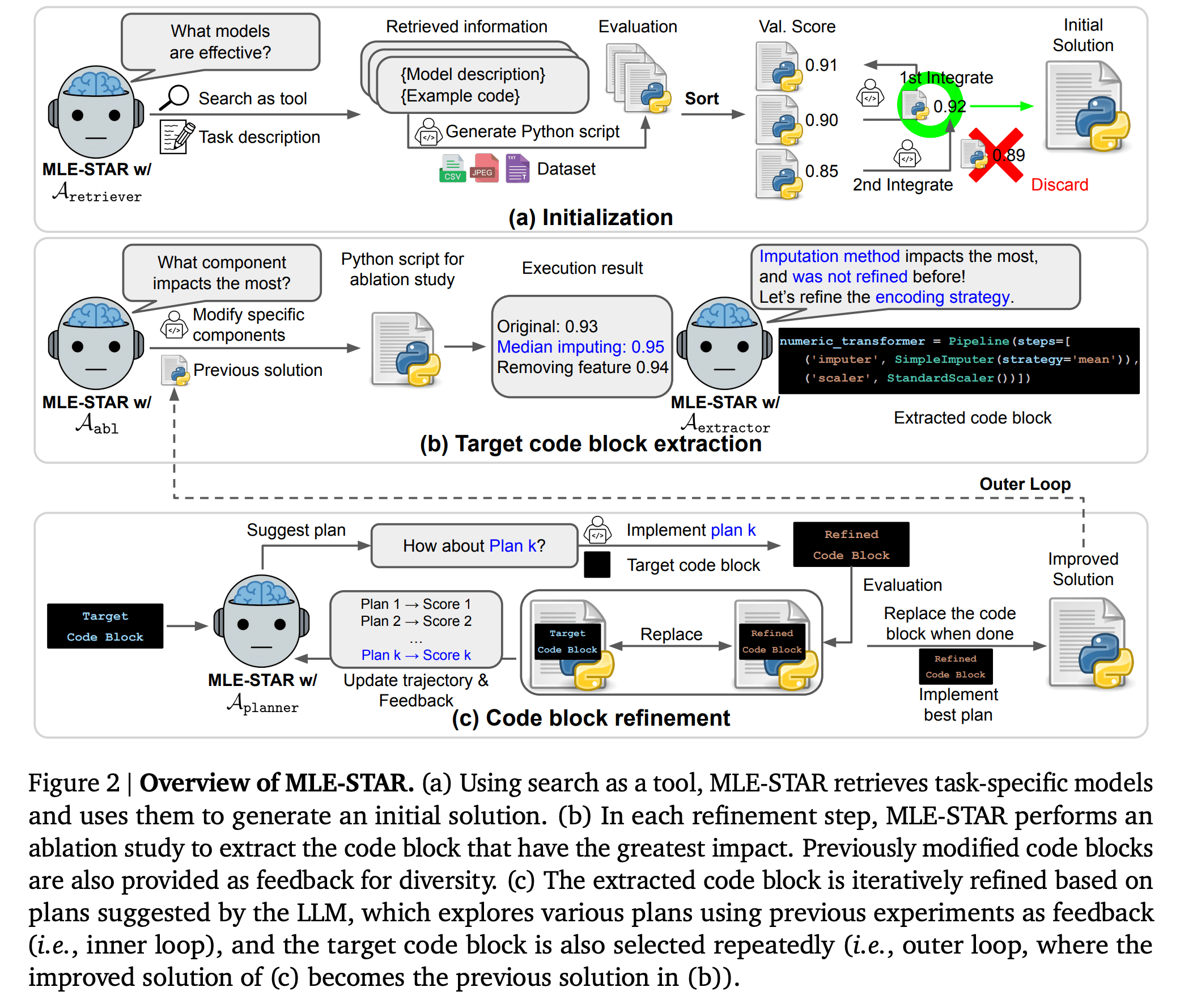
Neue Ensemble-Strategie und zusätzliche Schutzmechanismen
MLE-STAR erstellt dazu mehrere Varianten einer Lösung und entwickelt eine eigene Ensemble-Strategie, anstatt nur auf Durchschnittswerte zu setzen. Diese Strategie wird ebenfalls iterativ verbessert, um die Vorhersagekraft des finalen Modells zu maximieren.
Zur Absicherung der generierten Lösungen enthält MLE-STAR drei zusätzliche Module: Ein Debugging-Agent behebt Laufzeitfehler, ein Datenleck-Prüfer verhindert den unzulässigen Zugriff auf Testdaten während des Trainings und ein Datenverwendungs-Checker stellt sicher, dass alle bereitgestellten Datenquellen berücksichtigt werden – nicht nur einfache CSV-Dateien.
63 Prozent Medaillenerfolg bei Kaggle-Wettbewerben
Getestet wurde MLE-STAR im Rahmen der MLE-Bench-Lite, einer Benchmark-Suite auf Basis realer Kaggle-Wettbewerbe. Dabei erreichte der Agent in 63,6 Prozent der Fälle eine Medaille – ein deutlicher Sprung gegenüber der bisherigen Bestmarke von 25,8 Prozent. 36 Prozent der Erfolge waren Goldmedaillen. Laut Google war dafür lediglich ein kurzer Initialprompt nötig; das System funktionierte weitgehend autonom.
Die Leistungssteigerung wird unter anderem auf den Einsatz moderner Modelle wie EfficientNet oder ViT zurückgeführt, im Gegensatz zu älteren Architekturen wie ResNet, die von Konkurrenzsystemen bevorzugt werden. Darüber hinaus erlaubt MLE-STAR auch manuelle Eingriffe: So konnte etwa das Modell RealMLP erfolgreich integriert werden, indem dessen Beschreibung händisch ergänzt wurde.
Fehlerkorrektur bei LLM-Halluzinationen
Die Entwickler beobachteten, dass die getesteten Sprachmodelle Gemini 2.5 Flash und Pro teilweise fehlerhafte oder unrealistische Codebestandteile erzeugten – etwa durch Verwendung von Testdaten zur Normalisierung. In solchen Fällen greift der Datenleck-Prüfer ein. Auch ignorierte Datensätze wurden in den Tests durch den Datenverwendungs-Checker erkannt und eingebunden.
Google stellt den Code von MLE-STAR als Open Source zur Verfügung. Die Lösung basiert auf dem Agent Development Kit von Google. Nutzer müssen jedoch selbst sicherstellen, dass verwendete Modelle und Inhalte aus der Websuche lizenzrechtlich unbedenklich sind. MLE-STAR ist derzeit nur für Forschungszwecke vorgesehen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.