ARC-AGI-Benchmark: Grok 4 übertrifft GPT-5 bei komplexen Denkaufgaben

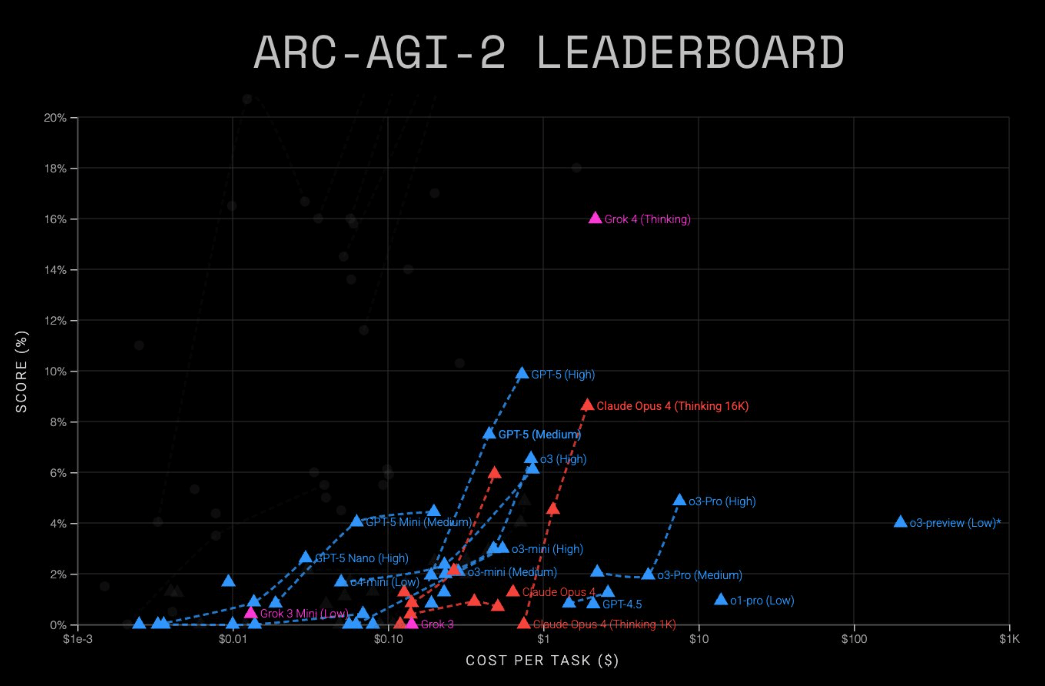
Im anspruchsvollen KI-Test "ARC-AGI-2", mit dem die allgemeine Denkfähigkeit von Sprachmodellen getestet werden soll, erreicht GPT-5 laut Anbieter ARC Prize 9,9 Prozent bei Kosten von 0,73 US-Dollar pro Aufgabe.
Grok 4 (Thinking) schneidet hier mit rund 16 Prozent besser ab, allerdings bei deutlich höheren Kosten zwischen zwei und vier US-Dollar. Der ARC-AGI-Benchmark von ARC Prize ist eine Reihe von Tests, die speziell die deduktiven Fähigkeiten von KI-Systemen bewerten anstatt die Erinnerungsfähigkeiten. In den Ranglisten werden die Modelle anhand ihrer erreichten Punktzahl sowie der Kosten pro gelöster Aufgabe verglichen.
Auch im einfacheren ARC-AGI-1-Test liegt Grok 4 mit etwa 68 Prozent vor GPT-5 mit 65,7 Prozent. Hier liegen die Kosten bei rund einem US-Dollar für Grok 4 gegenüber 0,51 US-Dollar für GPT-5.
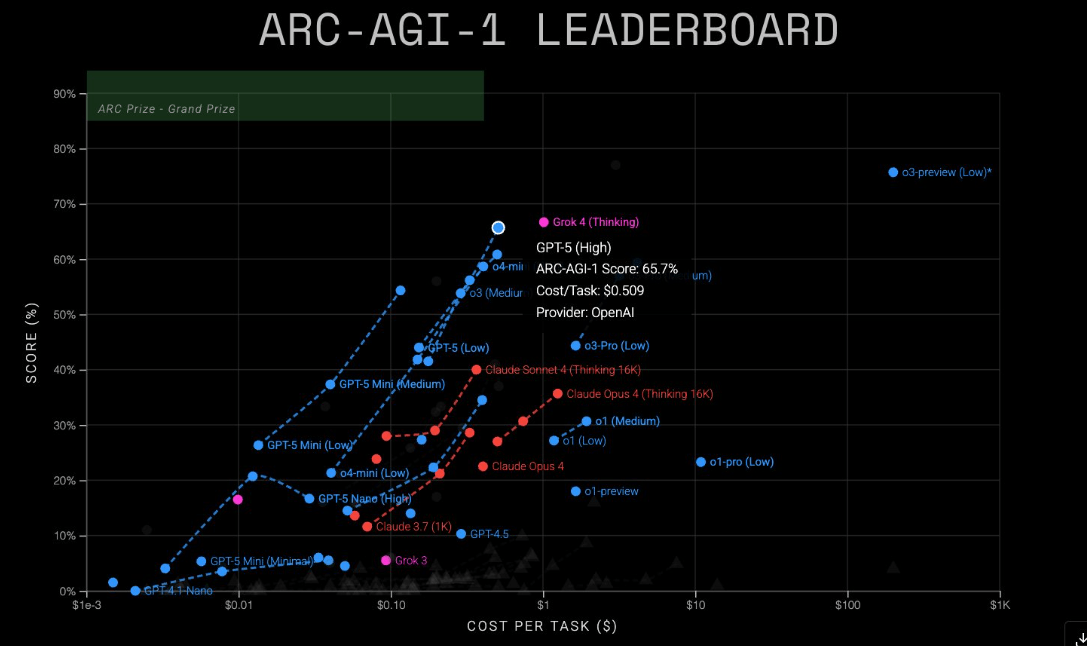
Günstigere, aber schwächere Versionen sind ebenfalls verfügbar: GPT-5 Mini erreicht 54,3 Prozent auf AGI-1 (0,12 $) und 4,4 Prozent auf AGI-2 (0,20 $). GPT-5 Nano kommt auf 16,5 Prozent (0,03 $) bzw. 2,5 Prozent (0,03 $).
Erste, noch inoffizielle Tests laufen laut ARC Prize auch auf dem interaktiven Benchmark ARC-AGI-3, bei dem die KI in einer spielähnlichen Umgebung durch Versuch und Irrtum Aufgaben lösen muss. Menschen kommen mit den Tests problemlos zurecht, die meisten KI-Agenten scheitern an den visuellen Rätselspielen.
Das Geheimnis um o3-preview
Bei der Vorstellung von GPT-5 erwähnte OpenAI den ARC Prize nicht weiter, der bei früheren Modellvorstellungen eine große Rolle einnahm: Auffällig ist, dass beim Test ARC-AGI 1 noch immer das im Dezember 2024 vorgestellte o3-preview-Modell mit fast 80 Prozent mit deutlichem Abstand am besten abschneidet – allerdings auch zu erheblich höheren Kosten als alle anderen Modelle.
OpenAI sah sich angeblich gezwungen, o3-preview für die später veröffentlichte Chat-Version deutlich zu beschneiden, thematisierte dies jedoch bislang nicht. Der ARC Prize bestätigte die schlechteren Ergebnisse für die veröffentlichte o3-Version Ende April.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.