Römische Ziffern und Sekundenzeiger bringen selbst beste KI-Systeme an ihre Grenzen

Während Menschen analoge Uhren mit 89,1 Prozent Genauigkeit lesen, erreicht das beste KI-Modell nur 13,3 Prozent. Die Ergebnisse werfen Fragen zum visuellen Reasoning aktueller Sprachmodelle auf.
Alek Safar hat 11 verschiedene Sprachmodelle von sechs Unternehmen gegen fünf menschliche Teilnehmende antreten lassen. Der neue Benchmark namens ClockBench umfasst 180 speziell erstellte analoge Uhren mit insgesamt 720 Fragen und folgt dem Prinzip "einfach für Menschen, schwer für KI", ähnlich wie ARC-AGI oder SimpleBench.
Um Verzerrungen durch bereits bekannte Trainingsdaten zu vermeiden, erstellte Safar den gesamten Datensatz neu. Die 36 verschiedenen Zifferblatt-Designs kombinieren systematisch Features wie römische oder arabische Ziffern, verschiedene Ausrichtungen, Stundenmarkierungen, gespiegelte Darstellungen und bunte Hintergründe. Pro Design wurden fünf Uhren mit unterschiedlichen Zeiten erstellt.
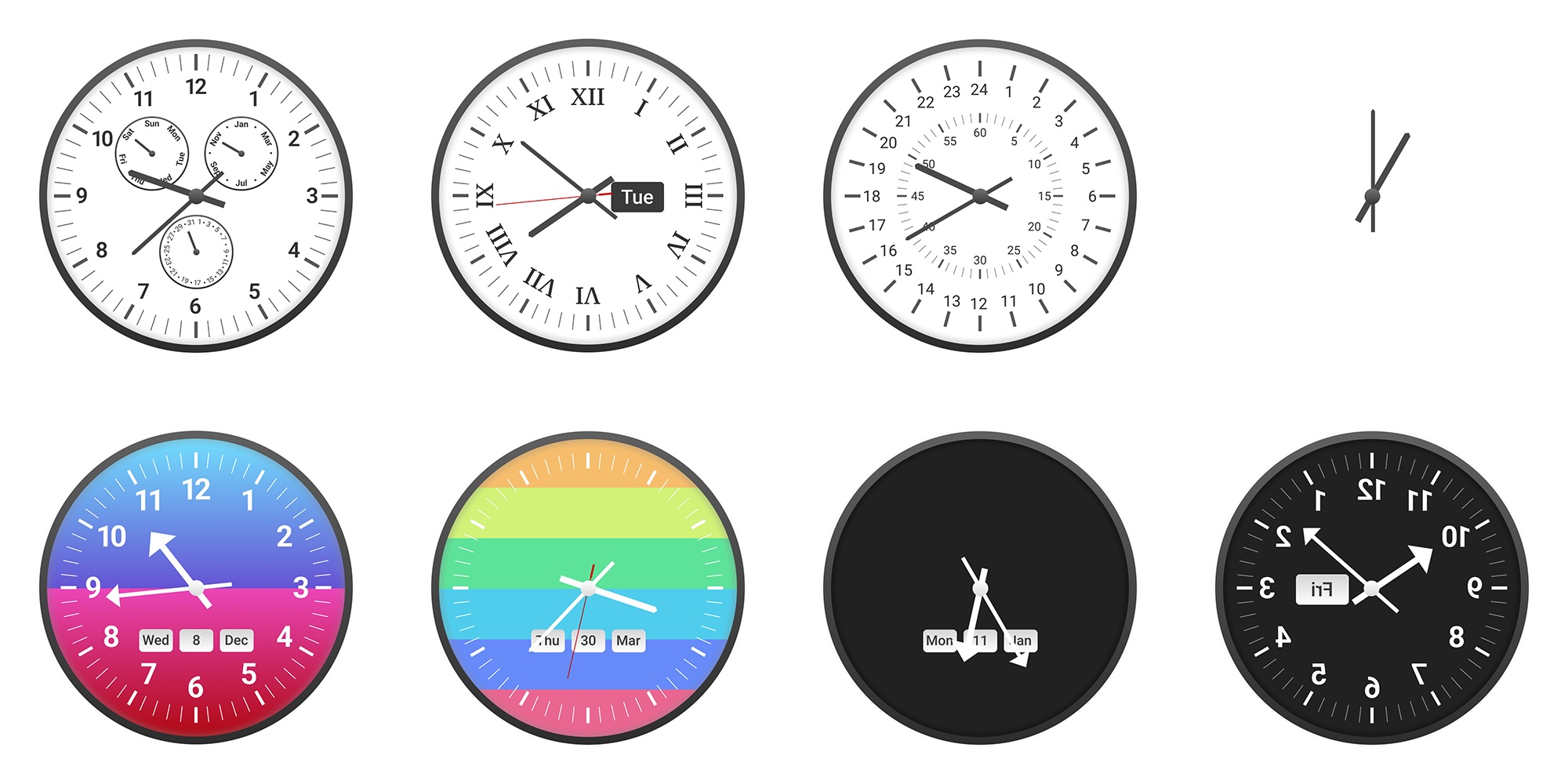
Jede Uhr wurde mit vier Aufgaben getestet: Zeitablesung, Zeitrechnungen, Zeigerverschiebungen um bestimmte Winkel und Zeitzonen-Umrechnungen. Je nach Uhrentyp erlaubte Safar unterschiedliche Genauigkeitsstufen, bei Uhren mit nur Stundenzeiger waren etwa größere Abweichungen akzeptabel als bei präzisen Uhren mit allen drei Zeigern.
ClockBench soll nach Angaben des Forschers schwieriger für Modelle sein als wissensintensive Benchmarks wie "Humanity's Last Exam". Die Studie zeigt eine deutliche Kluft zwischen menschlicher und maschineller Leistung bei einer scheinbar trivialen Aufgabe.
Google-Modelle führen schwaches Feld an
Googles Gemini 2.5 Pro erreichte mit 13,3 Prozent die beste Performance, gefolgt von Gemini 2.5 Flash mit 10,5 Prozent. GPT-5 landete mit 8,4 Prozent auf dem dritten Platz, wobei unterschiedliche Reasoning-Budgets kaum Einfluss auf das Ergebnis hatten.
Überraschend war die schwache Leistung von Grok 4, das mit nur 0,7 Prozent Genauigkeit das Schlusslicht bildete, obwohl es in vielen anderen Benchmarks die Konkurrenz übertrifft. Das Modell markierte 63,3 Prozent aller Uhren als ungültig, obwohl nur 37 von 180 Uhren tatsächlich unmögliche Zeiten zeigten. Ironischerweise führte diese übermäßig konservative Strategie dazu, dass Grok 4 bei den alleinigen richtigen Antworten technisch die höchste Anzahl erreichte, allerdings nur durch zufällige Treffer bei seinem pauschalen Ungültig-Ansatz.
Die Anthropic-Modelle Claude 4 Sonnet (4,2 Prozent) und Claude 4.1 Opus (5,6 Prozent) blieben ebenfalls hinter den Erwartungen zurück. Laut der Studie überlappten sich die korrekten Antworten der Modelle stark: 61,7 Prozent aller Uhren wurden von keinem einzigen Modell richtig gelesen.
Unterschiede bei Fehlergrößen
Noch deutlicher als die Genauigkeitsunterschiede waren die Fehlergrößen bei falschen Antworten. Menschen machten im Median nur 3-Minuten-Fehler, während selbst das beste KI-Modell median eine Stunde daneben lag. Die schwächsten Modelle erreichten Fehlergrößen von etwa drei Stunden, was bei 12-Stunden-Uhren praktisch zufälligen Raten entspricht.
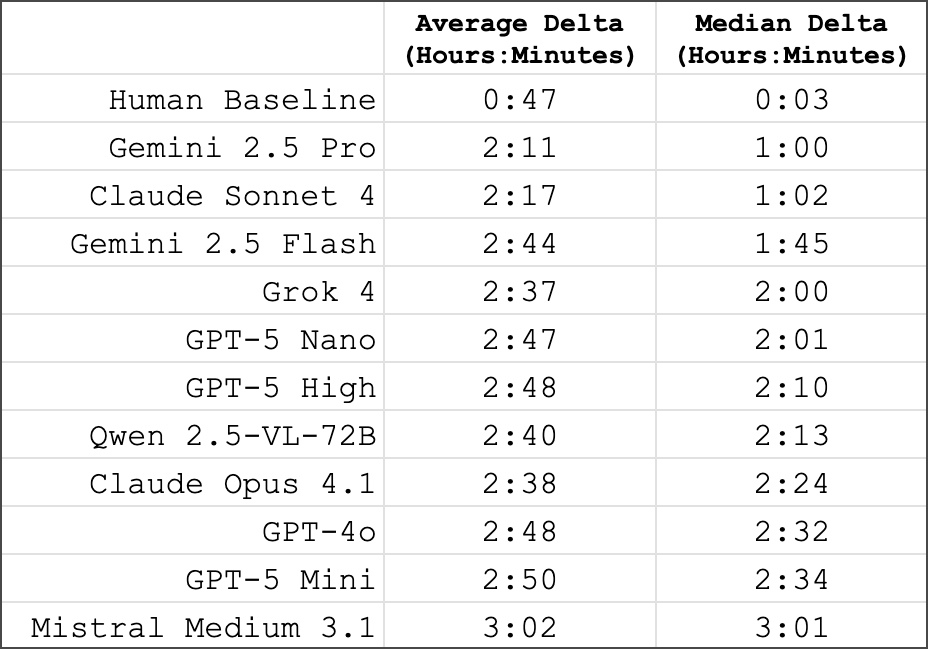
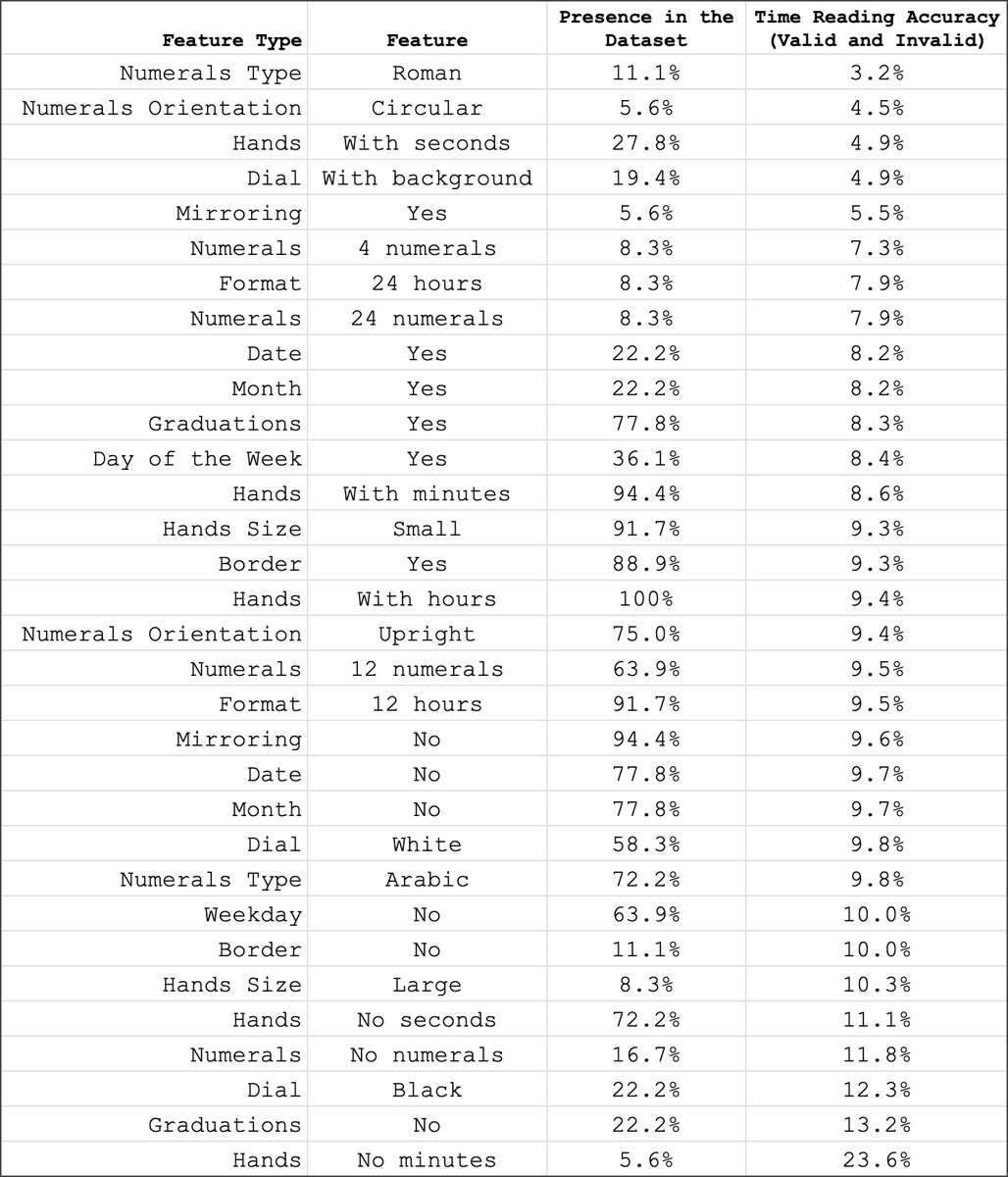
Bestimmte Uhren-Features erwiesen sich als besonders problematisch für die Modelle. Römische Ziffern führten zu nur 3,2 Prozent Genauigkeit, kreisförmig angeordnete Zahlen zu 4,5 Prozent. Auch Sekundenzeiger, bunte Hintergründe und gespiegelte Uhren bereiteten Schwierigkeiten.
Am einfachsten waren Uhren mit nur einem Stundenzeiger (23,6 Prozent Genauigkeit), da hier größere Fehlertoleranzen erlaubt waren. Standarduhren mit arabischen Ziffern und einfachen Zifferblättern schnitten ebenfalls besser ab.
Zeitrechnung funktioniert, Zeitablesung nicht
Ein unerwartetes Ergebnis zeigt sich bei den Follow-up-Fragen: Konnten die Modelle eine Uhrzeit korrekt ablesen, erreichten sie bei Zeitrechnungen, Zeigerverschiebungen oder Zeitzonen-Umrechnungen oft 100 Prozent Genauigkeit. Die Fähigkeit zur Zeitmanipulation ist also vorhanden, nur das initiale Ablesen der visuellen Information scheitert.
Safar spekuliert über mögliche Ursachen: Das Ablesen analoger Uhren könnte eine hohe Messlatte für visuelles Reasoning setzen. Ungewöhnliche Uhren seien möglicherweise nicht ausreichend in den Trainingsdaten repräsentiert, während gleichzeitig die Übersetzung visueller Uhren-Repräsentationen in Textbeschreibungen für weitere Verarbeitung problematisch sein könnte.
Benchmark soll KI-Entwicklung vorantreiben
ClockBench ist als fortlaufender Benchmark konzipiert. Der vollständige Datensatz bleibt privat, um Kontamination von Trainingsmaterial zu vermeiden, während eine kleinere öffentliche Version für Tests verfügbar ist.
Trotz der ernüchternden Ergebnisse sieht Safar optimistische Signale: Die besten Modelle lägen konsistent über dem Zufallsniveau und zeigten grundsätzliche Fähigkeiten zum visuellen Reasoning. Ob diese durch Skalierung bestehender Ansätze oder völlig neue Methoden verbessert werden können, bleibt laut der Studie eine offene Forschungsfrage.
Bereits vor rund einem Jahr hatte eine chinesische Studie multimodalen Sprachmodellen Schwächen beim Uhrlesen attestiert, allerdings mit deutlich besseren Ergebnissen. Damals erreichte GPT-4o bei Dashboard-Aufgaben, die das Ablesen von Uhren und Messgeräten erforderten, noch 54,8 Prozent Genauigkeit. Die aktuellen ClockBench-Ergebnisse mit maximal 13,3 Prozent für das beste Modell deuten darauf hin, dass der neue Test deutlich anspruchsvoller ist, sich die Fähigkeiten der Modelle beim Uhrlesen aber auch nicht sonderlich verbessert haben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.