Weniger ist mehr: 78 Trainingsbeispiele reichen für autonome Agenten aus

Eine neue Studie stellt die Grundannahmen der KI-Entwicklung infrage: Statt auf massive Datenmengen zu setzen, genügen angeblich 78 strategisch ausgewählte Beispiele, um überlegene autonome KI-Agenten zu entwickeln.
Das wollen Wissenschaftler:innen verschiedener chinesischer Forschungsinstitutionen mit ihrer Untersuchung LIMI ("Less Is More for Intelligent Agency") zeigen. Die Forschenden definieren "Agency" als die emergente Fähigkeit von KI-Systemen, als autonome Agenten zu funktionieren. Diese Systeme sollen Probleme aktiv entdecken, Hypothesen formulieren und Lösungen durch selbstgesteuerte Interaktion mit Umgebungen und Tools ausführen können.
Überlegenheit bei Agenten-Benchmark
Das LIMI-Modell erreicht laut der Studie mit nur 78 sorgfältig ausgewählten Trainingssamples eine Leistung von 73,5 Prozent auf dem AgencyBench-Benchmark.
Der AgencyBench-Benchmark umfasst komplexe Aufgaben, die realistische Arbeitsszenarien simulieren. Dazu gehören die Entwicklung von Software-Systemen wie C++-Chat-Anwendungen oder Java-To-do-Apps, die Programmierung webbasierter Spiele mit KI-Gegnern, der Aufbau von Microservice-Pipelines sowie Forschungsworkflows wie LLM-Leistungsvergleiche, Datenanalysen und komplexe Recherche-Aufgaben zu NBA-Spielern oder S&P 500-Unternehmen.
Die Überlegenheit gegenüber aktuellen Open-Weight-Spitzenmodellen ist erheblich: Deepseek-V3.1 kommt auf nur 11,9 Prozent, Kimi-K2-Instruct auf 24,1 Prozent, Qwen3-235B-A22B-Instruct auf 27,5 Prozent und GLM-4.5 auf 45,1 Prozent.
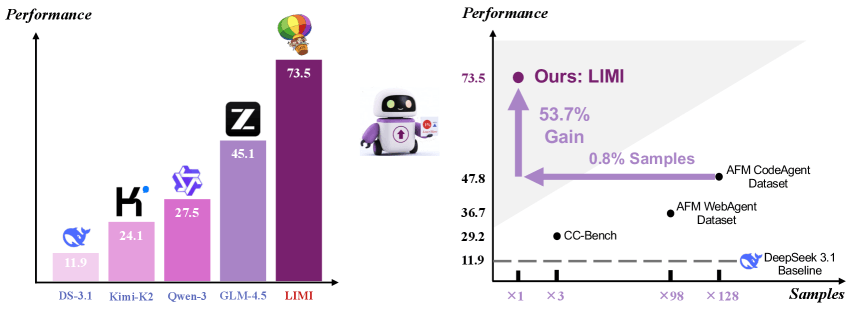
Auffällig ist, dass LIMI bereits beim ersten Versuch 71,7 Prozent der Anforderungen korrekt umsetzt, verglichen mit dem besten Baseline-Modell GLM-4.5 mit nur 37,8 Prozent. Dies entspricht einer Verbesserung von 33,9 Prozentpunkten. Bei der allgemeinen Erfolgsrate zeigt LIMI mit 74,6 Prozent ebenfalls eine deutliche Überlegenheit gegenüber GLM-4.5 mit 47,4 Prozent.
Die Überlegenheit erstreckt sich auch auf etablierte Benchmarks für Coding-Aufgaben und wissenschaftliches Rechnen. Mit einer durchschnittlichen Leistung von 57,2 Prozent übertraf LIMI alle Baseline-Modelle deutlich.
Der Vergleich mit alternativen Trainingsansätzen verdeutlicht die Effizienz: GLM-4.5-Code, trainiert mit 10.000 Samples, erreichte nur 47,8 Prozent auf AgencyBench. GLM-4.5-Web mit 7.610 Samples kam auf 36,7 Prozent, und GLM-4.5-CC mit 260 Samples erreichte 29,2 Prozent.
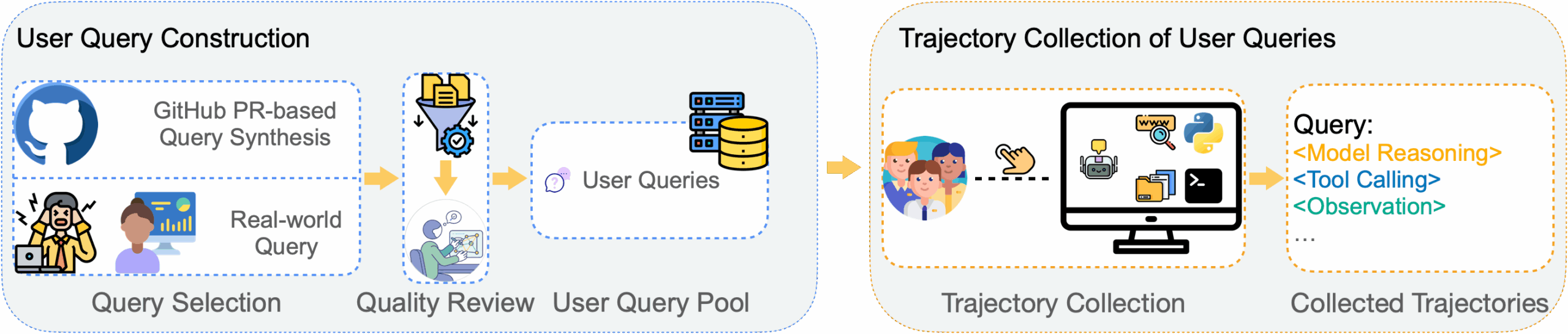
Für die Datengenerierung entwickelten die Wissenschaftler:innen eine neuartige Methodik: Sie synthetisierten Nutzer:innenanfragen aus GitHub-Pull-Requests mit GPT-5 und sammelten vollständige Interaktionssequenzen durch Mensch-KI-Zusammenarbeit in einer Kommandozeilen-Umgebung.
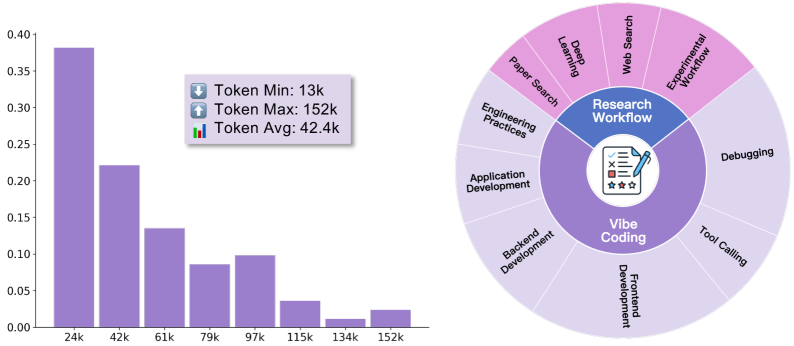
Die längste Interaktionssequenz erreichte 152.000 Tokens und demonstriere die Tiefe und Komplexität kollaborativer Problemlösungsprozesse, die ausgeprägte autonome Verhaltensweisen charakterisieren.
Paradigmenwechsel für die KI-Entwicklung
Die Ergebnisse könnten weitreichende Implikationen für die Entwicklung autonomer KI-Systeme haben. Während traditionelle Ansätze zunehmend komplexe Trainingspipelines und erhebliche Ressourcenanforderungen mit sich bringen, zeigt LIMI einen alternativen Weg, der jedoch noch weiter erforscht und in der Praxis geprüft werden muss.
Die Studie demonstriert auch, dass der Ansatz über verschiedene Modellgrößen hinweg funktioniert. LIMI-Air mit 106 Milliarden Parametern verbesserte sich von 17,0 Prozent auf 34,3 Prozent, während LIMI mit 355 Milliarden Parametern von 45,1 Prozent auf 73,5 Prozent stieg.
Code, Modelle und Datensätze sind öffentlich verfügbar.
Vor kurzem hatten bereits Nvidia-Forschende argumentiert, dass die meisten KI-Agenten unnötig auf überdimensionierte Large Language Models setzen und kleinere Modelle mit weniger als zehn Milliarden Parametern für agentische Anwendungen ausreichen würden. Die LIMI-Studie untermauert diese These nun mit empirischen Belegen für die Überlegenheit strategischer Datenkuratierung gegenüber der reinen Modellskalierung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.