OpenAI testet KI-Modelle erstmals systematisch an realer Wissensarbeit

Update –
- FileType-Auswertung ergänzt
Update Artikel vom 27. September 2025:
Eine Grafik aus dem GDPval-Paper zeigt deutlich, dass die Bewertung der KI-Modelle stark vom Dateiformat der abgegebenen Ergebnisse abhängt. Während die Modelle bei reinen Textaufgaben (pure text) die niedrigsten Win-Raten erzielen – Claude Opus 4.1 kommt hier nur auf 14 Prozent, GPT-5 auf 22 Prozent – sieht das Bild bei anderen Formaten ganz anders aus.
Bei PDFs steigt die Win-Rate für Claude auf 46 Prozent, bei Excel-Tabellen (xlsx) auf 45 Prozent und bei PowerPoint-Präsentationen (pptx) sogar auf 48 Prozent. In der Kategorie „other“ – zu der verschiedene weitere Formate zählen – erreicht Claude Opus 4.1 mit 50 Prozent Parität mit den menschlichen Fachkräften. GPT-5 zeigt ein ähnliches Muster: Auch hier liegen die Werte für strukturierte oder visuelle Formate wie xlsx (36 Prozent) und „other“ (49 Prozent) deutlich über denen für reinen Text.
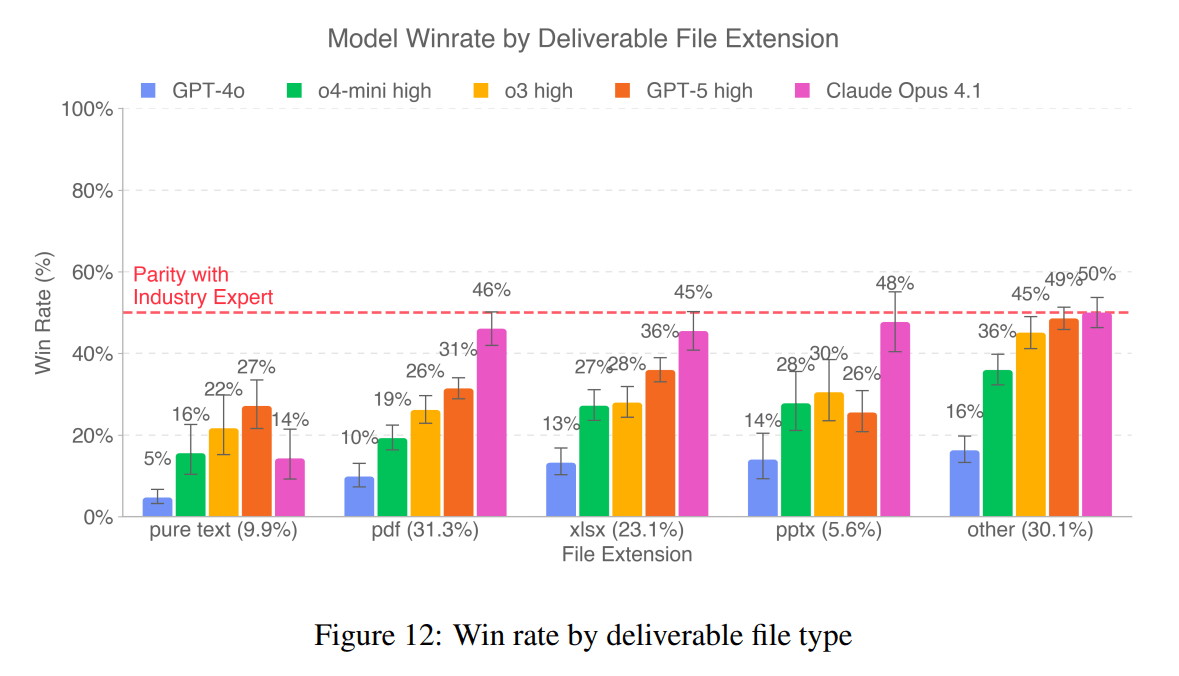
OpenAI liefert für diese Unterschiede keine Erklärung. Es liegt jedoch nahe, dass formale Kriterien wie Layout und visuelle Aufbereitung die menschlichen Gutachterinnen und Gutachter stark beeinflussen. Gerade bei Präsentationen, Tabellen oder PDFs können die Modelle mit sauberer Formatierung, klaren Strukturen und ansprechender Visualisierung punkten, selbst wenn der inhaltliche Gehalt nicht zwingend überlegen ist. Bei unformatiertem Fließtext entfällt dieser Vorteil, und die KI muss direkt mit der sprachlichen Präzision und Argumentationslogik menschlicher Fachkräfte konkurrieren.
Bemerkenswert ist zudem, dass die Formate PDF, Excel und „other“ zusammen über 80 Prozent aller Deliverables ausmachen. Das erklärt, warum Modelle wie Claude Opus 4.1 insgesamt auf relativ hohe Win-Raten kommen, obwohl sie bei reinen Textaufgaben weiterhin deutlich hinter menschlichen Expertinnen und Experten liegen.
Ursprünglicher Artikel vom 26. September 2025:
Mit GDPval führt OpenAI einen Benchmark für reale Wissensarbeit ein: 1320 Aufgaben aus 44 Berufen, bewertet von Branchenprofis.
Die erste Version deckt 44 Berufe in neun Industrien ab, die jeweils mehr als fünf Prozent zum US-BIP beitragen. Innerhalb dieser Industrien wählte OpenAI jene Berufe mit den höchsten Lohn- und Vergütungsbeiträgen aus und prüfte mithilfe der Berufedatenbank O*NET, ob sie überwiegend Wissensarbeit sind (Schwellenwert: mindestens 60 Prozent nicht-physische Tasks). Grundlage für die Auswahl sind Daten des US-Bundesamts für Arbeitsstatistik (Mai 2024), so OpenAI.
Die Aufgaben stammen aus Bereichen wie Technik, Pflege, Recht, Softwareentwicklung oder Journalismus. Entwickelt wurden sie von Berufsexperten mit durchschnittlich 14 Jahren Erfahrung. Alle Aufgaben basieren auf realen Arbeitsergebnissen wie juristischen Schriftsätzen, Pflegeplänen oder technischen Präsentationen.
Aufgaben mit realen Anforderungen
Im Gegensatz zu klassischen KI-Benchmarks bestehen GDPval-Aufgaben nicht nur aus Text-Prompts, sondern beinhalten zusätzliche Materialien und komplexe Ergebnisformate. Ein Beispiel: Ein Maschinenbauingenieur soll einen Prüfstand für ein Kabelspulsystem entwerfen, inklusive 3D-Modell und PowerPoint-Präsentation, alles auf Basis technischer Spezifikationen.
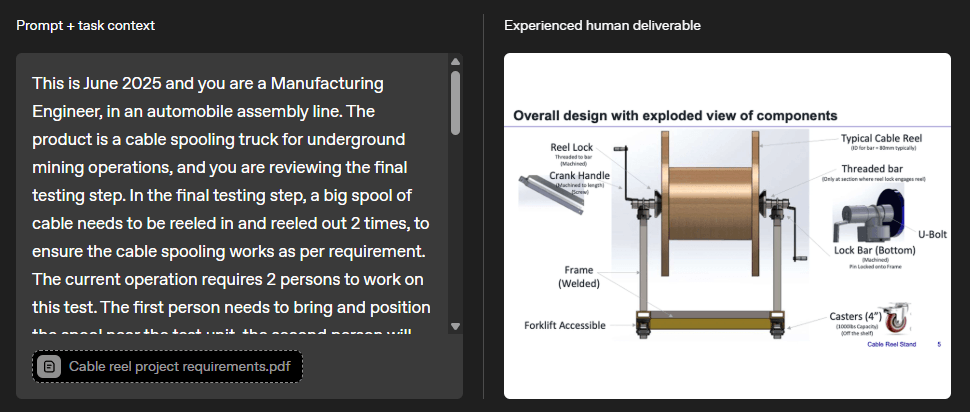
Die Bewertung erfolgt in Blindtests durch Branchenexpertinnen und -experten, die KI-Ergebnisse direkt mit den menschlichen Referenzlösungen vergleichen und als "besser", "gleich gut" oder "schlechter" einordnen.
Zusätzlich wurde ein KI-gestützter Bewertungsassistent entwickelt, der menschliche Bewertungen simulieren soll, aber derzeit noch experimentellen Charakter hat. Jede Aufgabe wurde laut Paper im Schnitt fünfmal überprüft (Peer-Checks, zusätzliche Fachreviews, modellgestützte Validierung).
Frontier-Modelle nähern sich Expertenniveau
In ersten Tests schnitten aktuelle Spitzenmodelle wie GPT-5 und Claude Opus 4.1 überraschend gut ab: Bei rund der Hälfte der 220 Aufgaben im veröffentlichten Gold-Set bewerteten Experten die KI-Ergebnisse als gleichwertig oder besser als die menschlichen.
Im Vergleich zu GPT-4o, das im Frühjahr 2024 erschien, hat sich die Leistung von GPT-5 je nach Metrik mehr als verdoppelt oder verdreifacht. Claude Opus 4.1 liegt noch weiter vorn und generierte bei knapp der Hälfte der Aufgaben Ergebnisse, die als genauso gut oder besser als die von Menschen bewertet wurden. Das Claude-Modell überzeugte laut OpenAI vorwiegend bei Ästhetik und Formatierung, GPT-5 bei Fachkenntnis und Genauigkeit.
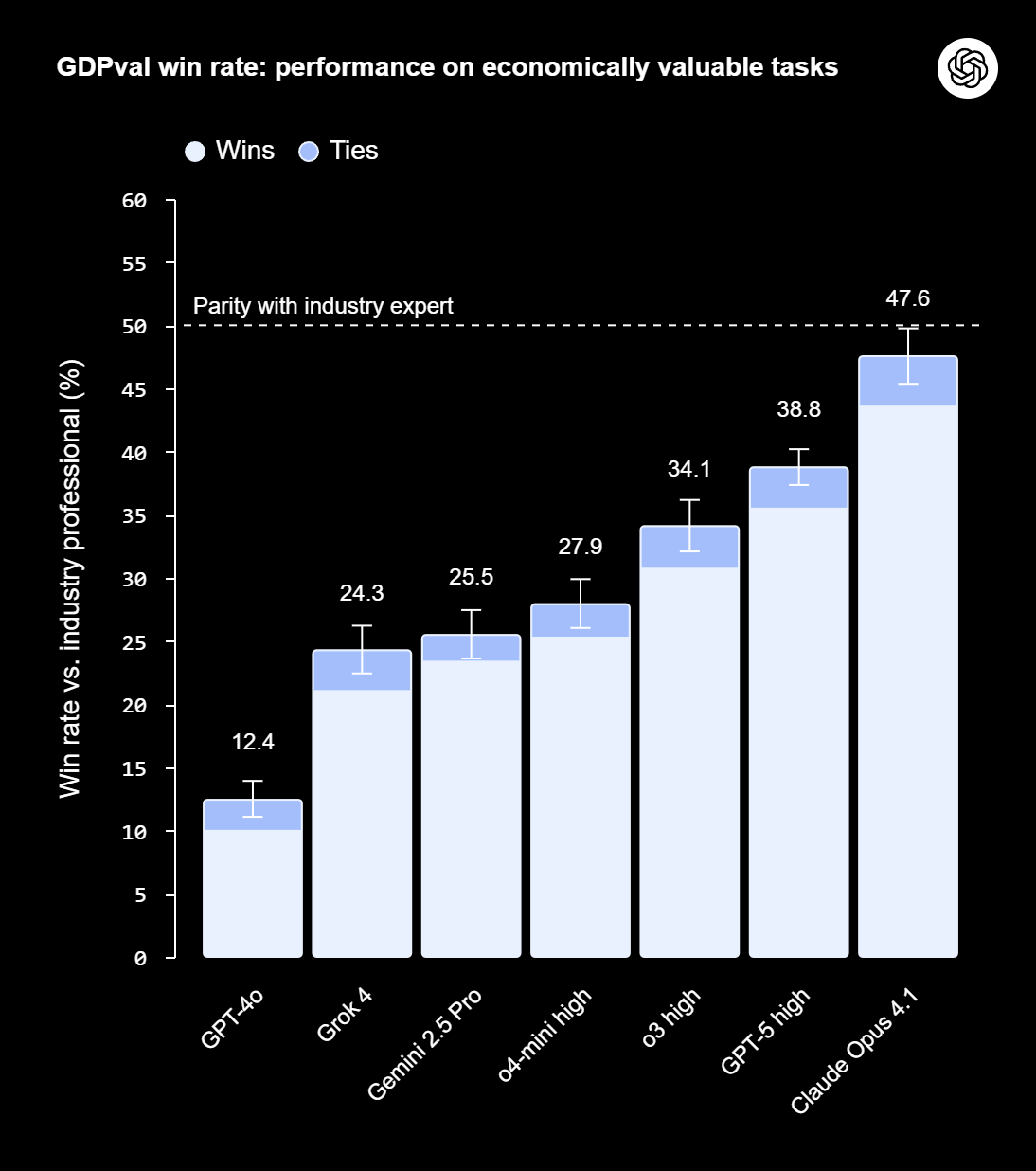
In Bezug auf Effizienz zeigen sich laut OpenAI deutliche Vorteile: Die Modelle erledigten Aufgaben rund 100-mal schneller und 100-mal günstiger als menschliche Experten, wenn man reine Inferenzzeit und API-Kosten betrachtet. Die KI-Firma erwartet, dass es Zeit und Kosten spart, wenn Modelle Aufgaben zunächst übernehmen, bevor Menschen sie bearbeiten; in der Praxis bleiben menschliche Aufsicht, Iteration und Integration nötig.
Noch keine echte Arbeitsplatzsimulation
Die aktuelle Version von GDPval beschränkt sich auf sogenannte Einzelversuch-Aufgaben ("One Shot"): Modelle bearbeiten jede Aufgabe nur einmal, ohne Rückmeldungen, Kontextaufbau oder Iterationen. Auch mit realer Ambiguität – etwa unklaren Anforderungen oder Rücksprachen mit Kolleginnen und Kunden – müssen sie sich nicht auseinandersetzen.
Der Benchmark testet damit lediglich die Bearbeitung einzelner, isolierter Arbeitsschritte am Computer. Doch Berufe bestehen aus mehr als nur solchen Teilaufgaben. Auch OpenAI betont, dass aktuelle KI-Modelle keine vollständigen Jobs ersetzen, sondern vor allem bei klar strukturierten, wiederholbaren Tätigkeiten unterstützen können. Hinzu kommt, dass der Testdatensatz mit nur 30 Aufgaben pro der 44 untersuchten Berufe relativ schmal ausfällt. Weitere Details finden sich im Paper.
Langfristig soll GDPval dabei helfen, den wirtschaftlichen Nutzen von KI-Modellen systematisch zu erfassen und die Auswirkungen auf den Arbeitsmarkt besser zu verstehen. OpenAI plant, künftige Versionen interaktiver und realitätsnäher zu gestalten. Aufgaben sollen etwa mit unklarer Ausgangslage oder Feedbackschleifen integriert werden. Wer Aufgaben beisteuern oder an der Bewertung mitwirken möchte, kann sich hier oder als OpenAI-Kunde hier registrieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.