Laut Anthropic schlägt "Context Engineering" das "Prompt Engineering"

Anthropic löst Prompt-Engineering durch ein neues Konzept ab: Context-Engineering. Die Methode soll KI-Agenten helfen, ihre begrenzte Aufmerksamkeit effizienter zu nutzen und bei langfristigen Aufgaben kohärent zu bleiben.
Context-Engineering umfasst laut Anthropic alle Strategien zur Kuratierung und Verwaltung des optimalen Token-Sets während der LLM-Inferenz. Im Gegensatz zum Prompt-Engineering, das sich hauptsächlich auf das Schreiben effektiver Prompts konzentriert, betrachtet Context-Engineering den gesamten Kontext-Zustand, inklusive Systemanweisungen, Tools, externer Daten und Nachrichtenverlauf.
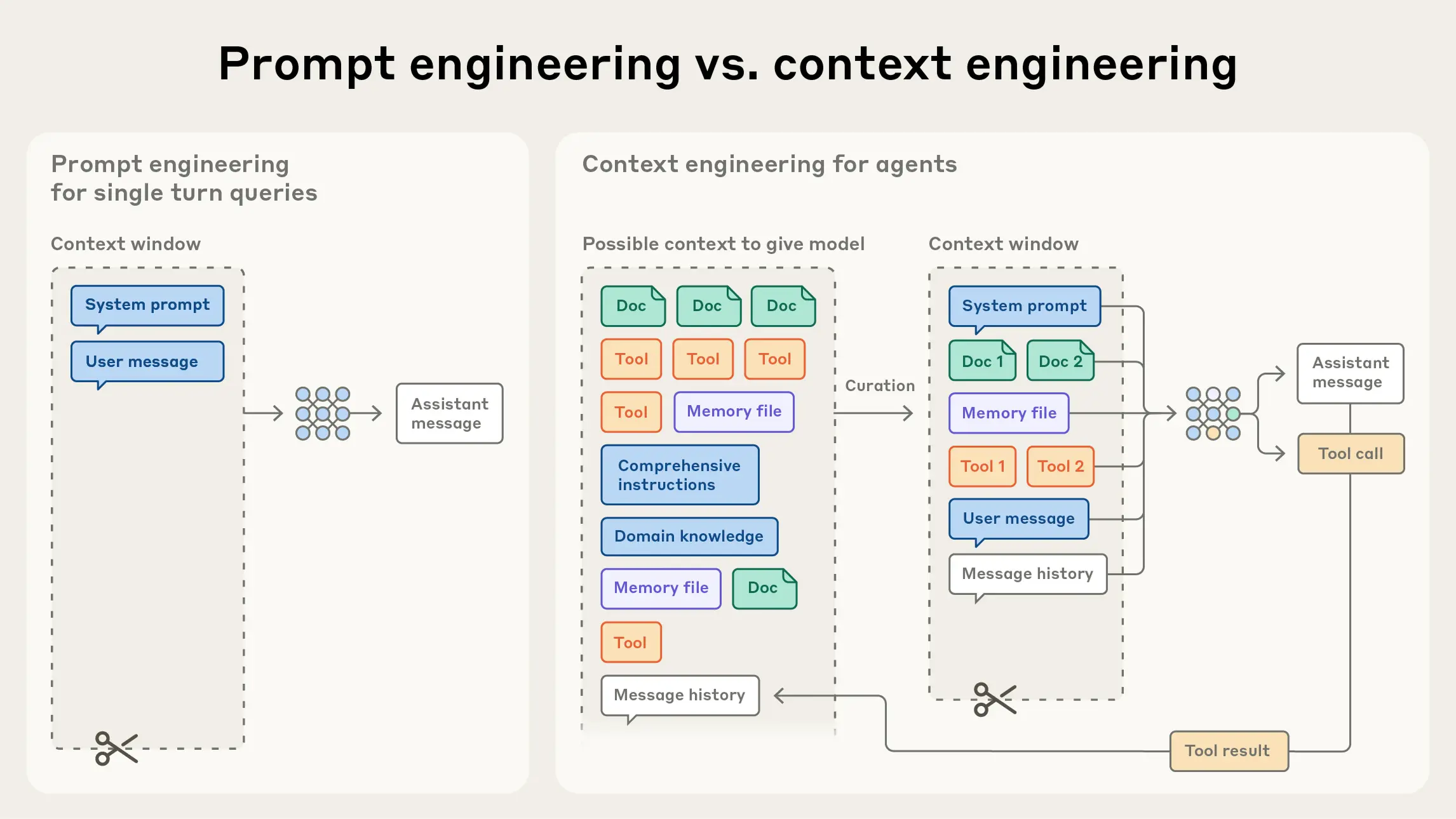
Der Begriff ist nicht neu: Prompt-Engineer Riley Goodside verwendete ihn bereits Anfang 2023. Shopify-CEO Tobi Lütke und Ex-OpenAI-Forscher Andrej Karpathy griffen ihn im Sommer 2025 erneut auf. Sie betrachten das sogenannte Context Engineering als den präziseren Begriff dafür, wie sich generative KI oder KI-Agenten effektiv steuern lassen, im Gegensatz zum gängigeren Prompt Engineering.
Strategien für effektiven Kontext
Für System-Prompts empfiehlt Anthropic das richtige "Höhenniveau" zu finden: spezifisch genug für Verhaltenssteuerung, aber flexibel genug für starke Heuristiken. Bei Tools stehe Token-Effizienz im Vordergrund mit minimalen Überschneidungen in der Funktionalität.
Das Unternehmen beobachtet einen Wandel hin zu "Just in Time"-Strategien. Anstatt alle Daten vorab zu verarbeiten, würden Agenten leichte Identifikatoren beibehalten und Daten zur Laufzeit dynamisch laden. Claude Code nutze diesen Ansatz für komplexe Datenanalysen, ohne vollständige Datenobjekte in den Kontext zu laden.
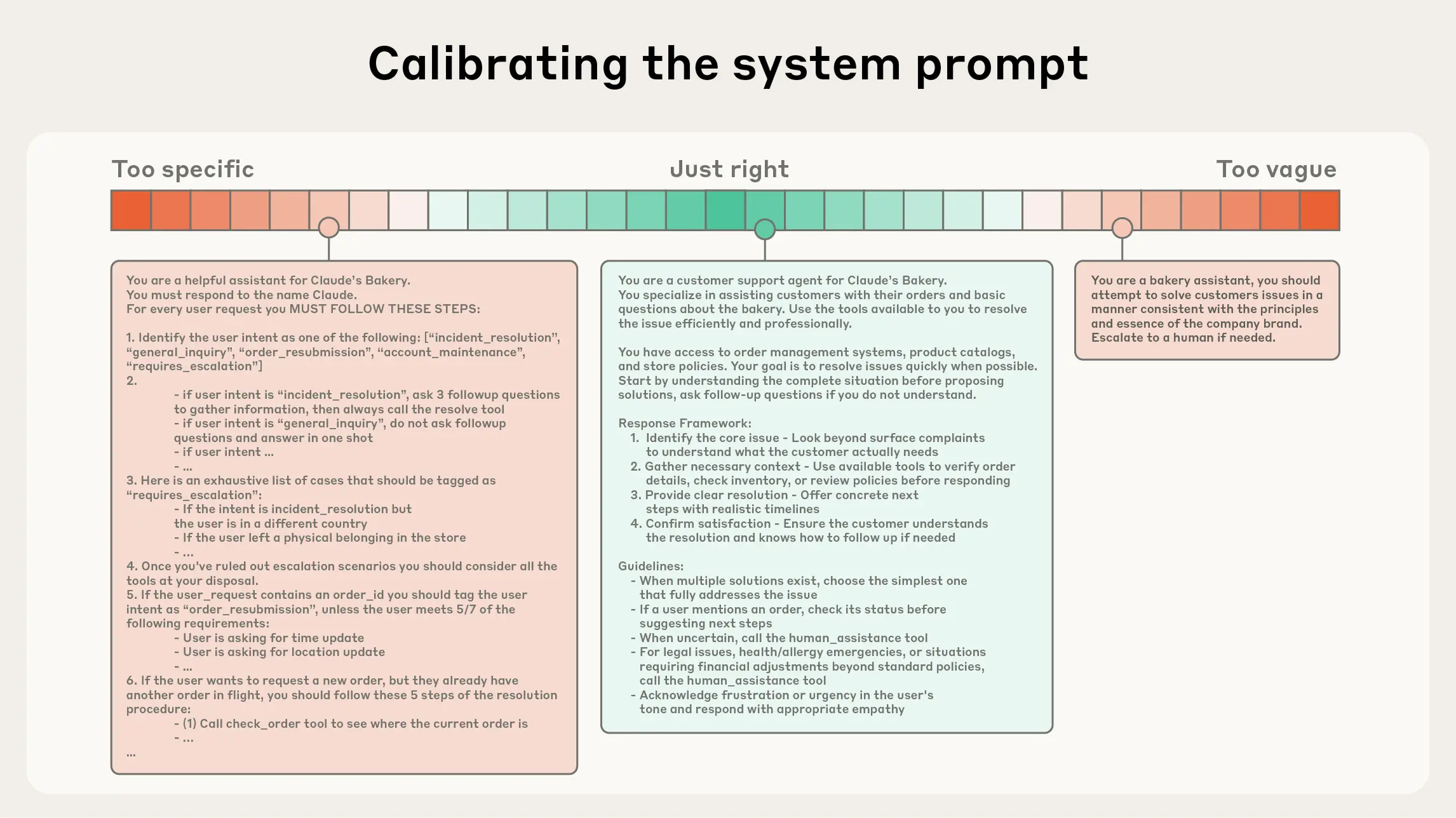
Für mehrstündige Aufgaben hat Anthropic drei Haupttechniken entwickelt:
- Kompaktierung fassen Unterhaltungen nahe der Kontextgrenze zusammen und starte mit komprimiertem Kontext neu.
- Strukturierte Notizen ermöglichten persistente Speicherung außerhalb des Kontextfensters.
- Sub-Agent-Architekturen verwendeten spezialisierte Agenten für fokussierte Aufgaben, während der Hauptagent koordiniere und nur kondensierte Zusammenfassungen erhalte.
Aufmerksamkeit als knappe Ressource
Die Notwendigkeit ergibt sich aus den architektonischen Beschränkungen von LLMs. Studien haben das Phänomen der Context Rot untermauert: Mit steigender Token-Anzahl sinke die Fähigkeit des Modells, Informationen korrekt abzurufen.
Die Ursache liege in der Transformer-Architektur: Jeder Token könne zu jedem anderen Token eine Beziehung aufbauen, was bei n Tokens zu n² paarweisen Beziehungen führe. LLMs verfügten über ein begrenztes "Aufmerksamkeitsbudget", das bei der Verarbeitung großer Kontextmengen erschöpft werde.
Weniger Token-Verbrauch durch Memory Tool
Im Rahmen der Vorstellung von Claude 4.5 Sonnet hat Anthropic ein Memory-Tool in der Public Beta veröffentlicht. Dieses ermögliche es Agenten, Wissensdatenbanken über Zeit aufzubauen. Das neue Memory-Tool arbeitet clientseitig über Tool-Aufrufe und lässt Entwickler:innen selbst entscheiden, wo und wie Daten gespeichert werden. Claude kann damit Dateien in einem Memory-Verzeichnis erstellen, lesen und bearbeiten, das über Unterhaltungen hinweg bestehen bleibt.
Anthropic berichtet von deutlichen Verbesserungen in eigenen Tests: Die Kombination aus Memory Tool und Context Editing soll die Leistung bei agentischer Suche um 39 Prozent gesteigert haben. Context Editing allein habe 29 Prozent Verbesserung gebracht. Bei einer 100-Runden-Web-Suche sei der Token-Verbrauch um 84 Prozent gesunken.
Die Features sind seit Kurzem in der Public Beta auf der Claude Developer Platform verfügbar, auch über Amazon Bedrock und Google Cloud Vertex AI. Anthropic stellt Dokumentationen und ein Cookbook bereit.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.