IBM startet Granite 4.0: Hybride Open-Source-Sprachmodelle mit weniger Speicherbedarf

Kurz & Knapp
- IBM stellt mit Granite 4.0 eine Open-Source-KI-Sprachmodellreihe vor, die eine hybride Mamba/Transformer-Architektur nutzt, um den Speicherbedarf bei der Inferenz deutlich zu reduzieren und eine effiziente Verarbeitung auch bei langen Kontexten zu ermöglichen.
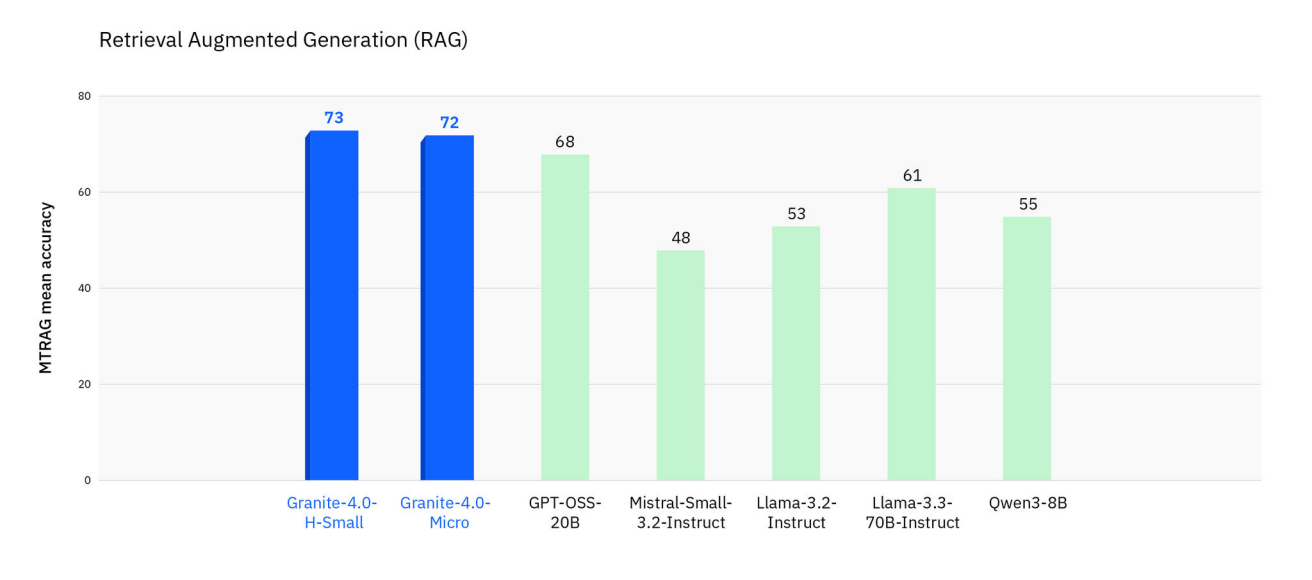
- Die vier Open-Source-Modelle sind speziell auf Unternehmensanwendungen wie Kundenservice und RAG-Systeme ausgerichtet und bieten laut IBM bis zu 70 Prozent weniger RAM-Verbrauch als reine Transformer-Modelle.
- Sie wurden nach ISO/IEC 42001:2023 zertifiziert, einer internationalen KI-Norm, die Anforderungen an Transparenz, Sicherheit und verantwortungsvollen Einsatz von KI-Systemen definiert.
IBM startet die vierte Generation seiner Granite-Sprachmodelle. Granite 4.0 setzt auf eine hybride Mamba/Transformer-Architektur, die den Speicherbedarf in der Inferenz stark reduzieren soll, ohne die Leistung zu beeinträchtigen.
IBM positioniert Granite 4.0 als Bausteine für agentische Workflows und als eigenständige Modelle für typische Unternehmensaufgaben wie Kundenservice oder RAG-Systeme, mit Fokus auf niedrige Latenz und geringere Betriebskosten, laut IBM. Die Thinking-Varianten sollen im Herbst folgen.
Die Modelle erscheinen als Open Source unter Apache 2.0, sind kryptografisch signiert und wurden als erste offene Sprachmodellfamilie nach ISO/IEC 42001:2023 akkreditiert. Die Trainingsdaten seien kuratiert, ethisch beschafft und unternehmensgeeignet, so IBM.
Alle Granite-4.0-Modelle wurden aus demselben 22T-Token-Korpus gespeist, der laut IBM aus DataComp-LM (DCLM), GneissWeb, TxT360-Subsets, Wikipedia und weiteren unternehmensrelevanten Quellen zusammengestellt ist. Für Inhalte, die Granite auf IBM watsonx.ai generiert, gewährt IBM eine unbegrenzte Freistellung bei Drittanbieter-IP-Ansprüchen.
Granite 4.0 umfasst vier Modellvarianten:
- Granite-4.0-H-Small: hybrides Mixture-of-Experts-Modell (32B Parameter, 9B aktiv)
- Granite-4.0-H-Tiny: hybrides MoE (7B Parameter, 1B aktiv)
- Granite-4.0-H-Micro: dichtes Hybridmodell mit 3B Parametern
- Granite-4.0-Micro: klassisches Transformer-Modell mit 3B Parametern
Das H-Small-Modell ist laut IBM als leistungsfähiger Allrounder für produktive Workflows konzipiert. Tiny und Micro richten sich an Low-Latency- oder Edge-Szenarien und können als schnelle Module in größeren agentischen Prozessen eingesetzt werden – etwa für Function Calling.
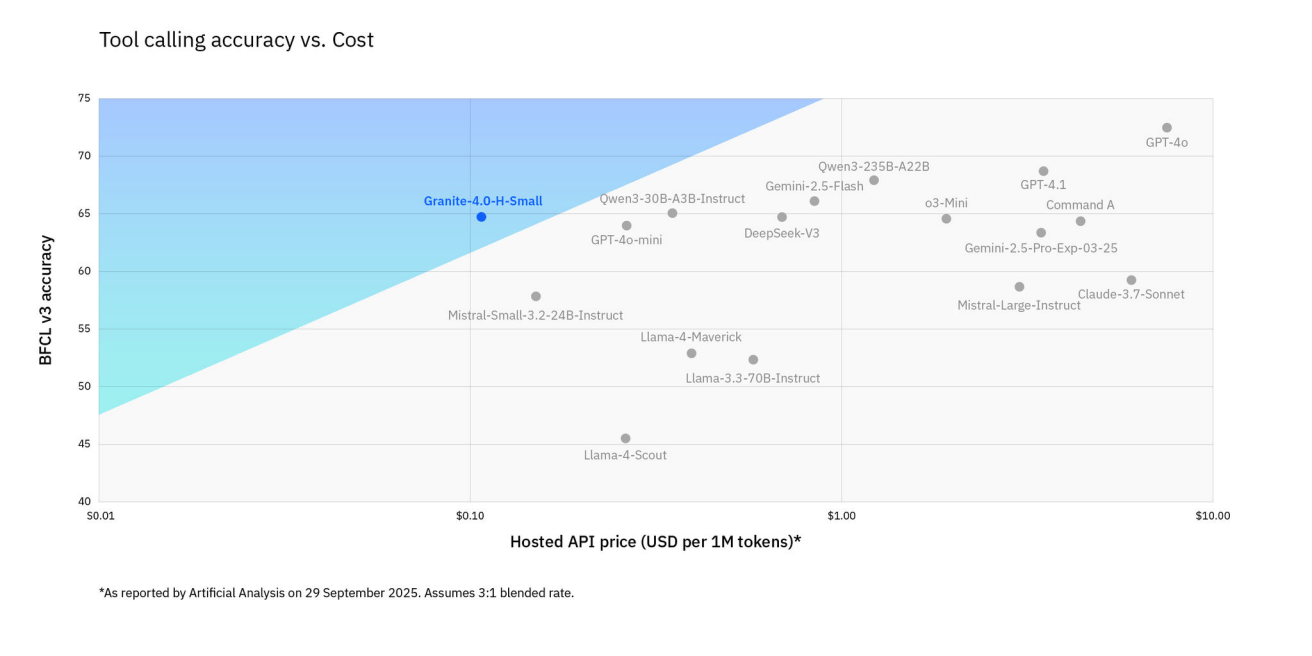
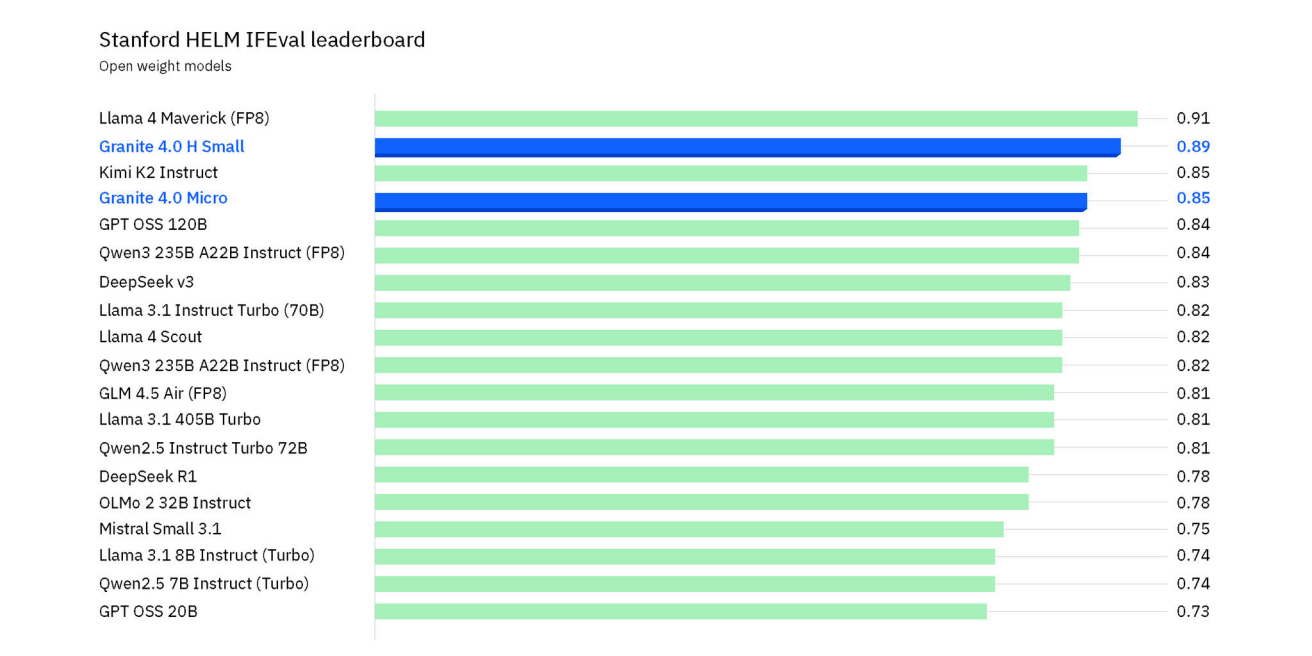
Architektur
Technisch kombiniert Granite 4.0 Mamba-2- und Transformer-Schichten im Verhältnis 9:1. Während Transformer-Modelle bei langen Kontexten schnell an Speichergrenzen stoßen, skaliert Mamba linear mit der Sequenzlänge und benötigt konstanten Speicher. Positionskodierung wird nicht mehr benötigt: Mamba verarbeitet Eingaben sequenziell und erhält dabei die Reihenfolge automatisch.
Transformer bleiben laut IBM beim In‑Context‑Learning (z. B. Few‑Shot-Prompting) zwar im Vorteil. Doch durch die Hybridarchitektur sollen beide Ansätze bestmöglich kombiniert werden. Tiny und Small nutzen zudem Mixture‑of‑Experts‑Blöcke mit "shared experts", die permanent aktiviert sind, um die Parametereffizienz zu erhöhen.
Für reale Workloads nennt IBM bis zu 70 Prozent weniger RAM-Verbrauch im Vergleich zu reinen Transformer-Modellen, insbesondere bei langen Eingaben oder parallelen Sessions.
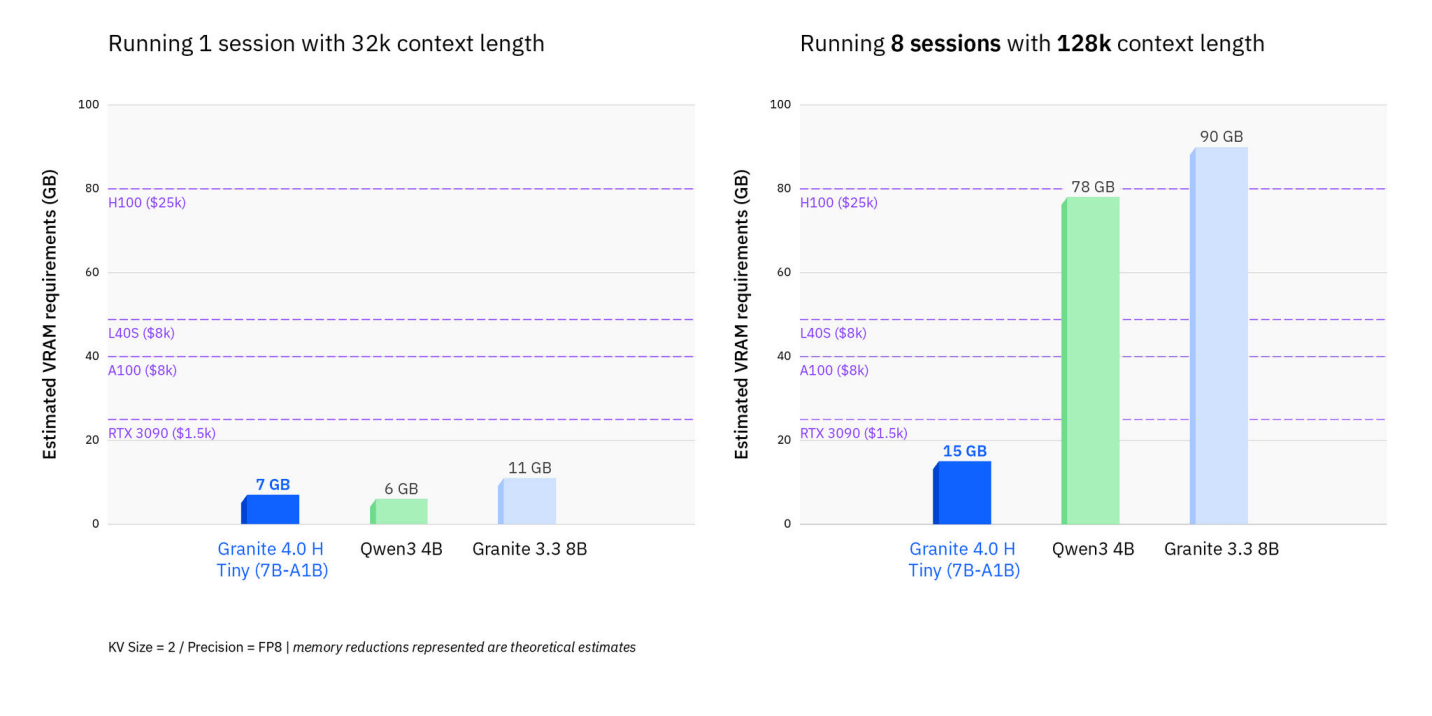
Granite 4.0 ist zudem kompatibel mit AMD Instinct MI-300X und durch die Zusammenarbeit mit Qualcomm und Nexa AI auch optimiert für den Einsatz auf Hexagon-NPUs, etwa auf Smartphones oder PCs.
Verfügbarkeit
Granite 4.0 Instruct ist in IBM watsonx.ai und bei Partnern verfügbar (Dell Pro AI Studio, Dell Enterprise Hub, Docker Hub, Hugging Face, Kaggle, LM Studio, NVIDIA NIM, Ollama, OPAQUE, Replicate). Base-Modelle stehen auf Hugging Face bereit. Der Zugang über Amazon SageMaker JumpStart und Microsoft Azure AI Foundry soll bald folgen.
Zum Einstieg verweist IBM auf den Granite Playground sowie die technischen Anleitungen in den Granite Docs. Außerdem werden Granite 4.0-Modelle von Tools wie Unsloth für effizientes Finetuning und Continue für Coding-Assistenten unterstützt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren