KI-System JanusCoder: Ein Modell für Text, Code und visuelle Ausgaben
Ein internationales Forschungsteam hat mit JanusCoder eine neue Generation von KI-Modellen vorgestellt, die Code-Generierung und visuelle Ausgaben in einem einheitlichen System vereinen. Die Modelle sollen die Lücke zwischen textbasierter Programmierung und visueller Darstellung schließen.
Moderne Softwareentwicklung erfordert zunehmend die Verbindung von Code und visuellen Elementen. Entwickler:innen müssen längst nicht nur funktionsfähigen Code schreiben, sondern auch ansprechende Datenvisualisierungen, interaktive Web-Interfaces und komplexe Animationen erstellen. Bisherige KI-Modelle behandeln diese Aufgaben jedoch getrennt voneinander und erfordern spezialisierte Lösungen für jeden Bereich.
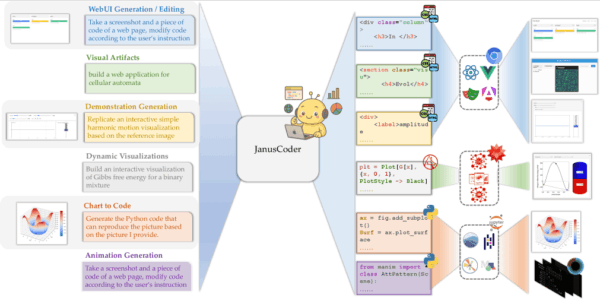
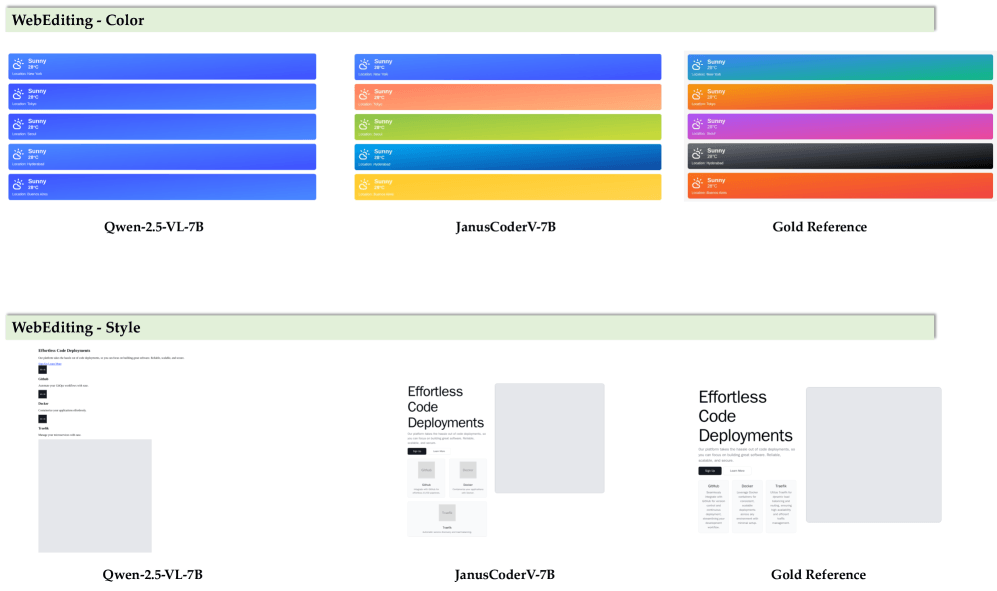
Wissenschaftler:innen von Institutionen aus Hongkong, China und den USA haben nun JanusCoder und JanusCoderV entwickelt. Der zentrale Unterschied liegt in der Vereinheitlichung verschiedener Aufgaben unter einer gemeinsamen Schnittstelle. Statt separate Modelle für Chart-to-Code, WebUI-Generierung oder Animationserstellung zu verwenden, verarbeitet JanusCoder alle diese Aufgaben mit demselben System. Das macht sich etwa bei der Auswahl einer stimmigen Farbpalette bemerkbar.
Die Modelle unterstützen verschiedene Programmiersprachen und können Code für Matplotlib-Diagramme, interaktive Web-UIs, wissenschaftliche Demonstrationen und mathematische Animationen generieren. Dabei können sie sowohl rein textbasierte Anweisungen verarbeiten als auch visuelle Eingaben wie Screenshots oder Diagramme in funktionsfähigen Code umwandeln.
JanusCode-800K als Trainingsbasis
Grundlage für das Training ist der Datensatz JanusCode-800K, den die Forschenden als größten multimodalen Code-Intelligenz-Korpus bezeichnen. Der Datensatz wurde mit einem eigens entwickelten Synthese-Toolkit erstellt, das verschiedene Strategien zur Datengenerierung und -verbesserung kombiniert.
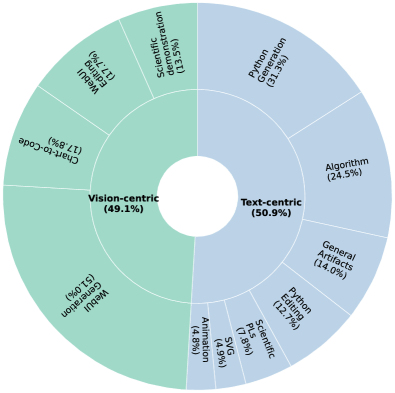
Ein zentraler Aspekt ist dabei die Nutzung von Synergien zwischen verschiedenen Domänen. Die Forschenden zeigen, dass Wissen zwischen verwandten Bereichen übertragen werden kann. So kann etwa R-Code das Training für Mathematica-Aufgaben verstärken oder visuelle Ausgaben von Python-Visualisierungen für Chart-to-Code-Daten verwendet werden.
Da ausführbarer Code nicht automatisch hochwertigen visuellen Output garantiert, entwickelten die Forschenden eine spezielle Qualitätskontrolle. Diese verwendet Vision-Language-Models, um die Qualität der generierten visuellen Inhalte zu bewerten.
Das System bewertet vier Dimensionen: Aufgabenrelevanz, Vollständigkeit der Umsetzung, Code-Qualität und visuelle Klarheit. Nur Datenproben, die einen vordefinierten Schwellenwert überschreiten, werden in den finalen Datensatz aufgenommen.
Starke Leistung bei verschiedenen Aufgabentypen
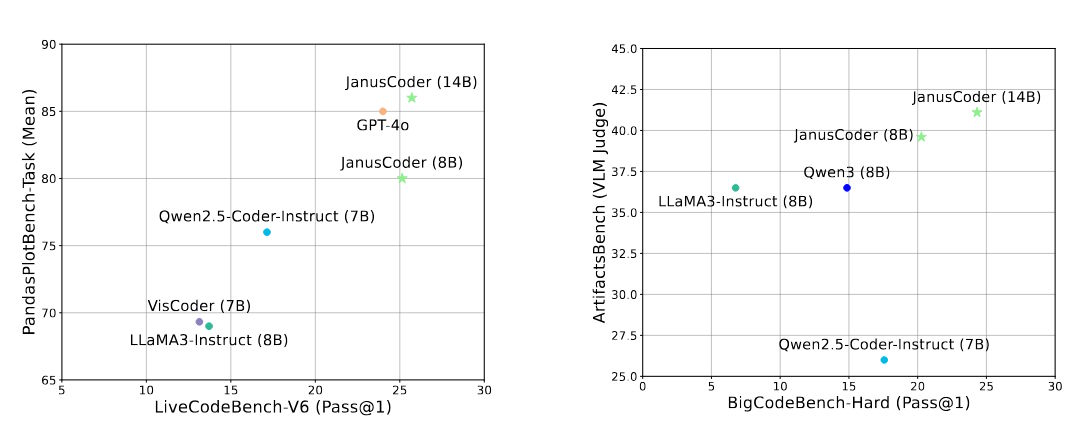
In den Experimenten zeigen JanusCoder-Modelle mit 7B bis 14B Parametern Leistungen, die an führende kommerzielle Modelle mit einem Vielfachen der Parameterzahl heranreichen oder diese gar übertreffen. Bei Tests zur Python-Visualisierung erreicht JanusCoder-14B eine Fehlerrate von nur 9,7 Prozent und liegt damit gleichauf mit GPT-4o.
Bei Aufgaben, die visuelle Eingaben und Codeausgaben kombinieren, zeigt JanusCoderV eine gemischte Leistung im Vergleich zu kommerziellen Modellen. Während es bei Chart-to-Code-Aufgaben (ChartMimic) selbst GPT-4o deutlich übertrifft, bleibt es in anderen Bereichen wie der Webseiten-Generierung hinter der kommerziellen Konkurrenz zurück. Tests zur Generierung von Webseiten aus Screenshots und zur wissenschaftlichen Demonstrationserstellung zeigen signifikante Verbesserungen sowohl in der visuellen Qualität als auch in der strukturellen Korrektheit des generierten Codes.
Die Modelle behalten dabei starke allgemeine Programmierfähigkeiten bei. Bei Standard-Coding-Benchmarks erreichen sie konkurrenzfähige Ergebnisse und übertreffen sogar auf Datenvisualisierung spezialisierte Modelle wie VisCoder.
Umfangreiche Experimente validieren die Designentscheidungen der Forschenden. Das Entfernen verschiedener Datenkategorien aus dem Trainingssatz führt zu Leistungseinbußen, was die Wirksamkeit der domänenübergreifenden Synergien bestätigt. Ohne die visuelle Qualitätskontrolle sinkt die Performance ebenfalls merklich.
Die Forschenden zeigen auch, dass ihr Ansatz über verschiedene Basismodelle hinweg konsistente Verbesserungen erzielt. Von Qwen3 über InternVL bis zu verschiedenen Modellgrößen profitieren alle getesteten Architekturen von dem JanusCode-800K-Datensatz.
JanusCoder ist als Open-Source-Projekt auf GitHub verfügbar und soll als Standard für multimodale Code-Intelligenz dienen. Die Modelle könnten für Entwickler:innen interessant sein, die komplexe visuelle Anwendungen erstellen müssen, ohne auf mehrere spezialisierte Tools angewiesen zu sein.
Diese Entwicklung reiht sich in einen breiteren Trend ein, KI-Modelle über reine Code-Generierung hinaus zu erweitern. Meta verfolgt mit seinem kürzlich vorgestellten Weltmodell einen ähnlichen Ansatz: Statt nur syntaktisch korrekten Code zu produzieren, soll das Modell ein tieferes Verständnis für reale Anwendungen und Kontexte entwickeln.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.