KI-generierte OP-Videos: Optisch überzeugend, medizinisch katastrophal
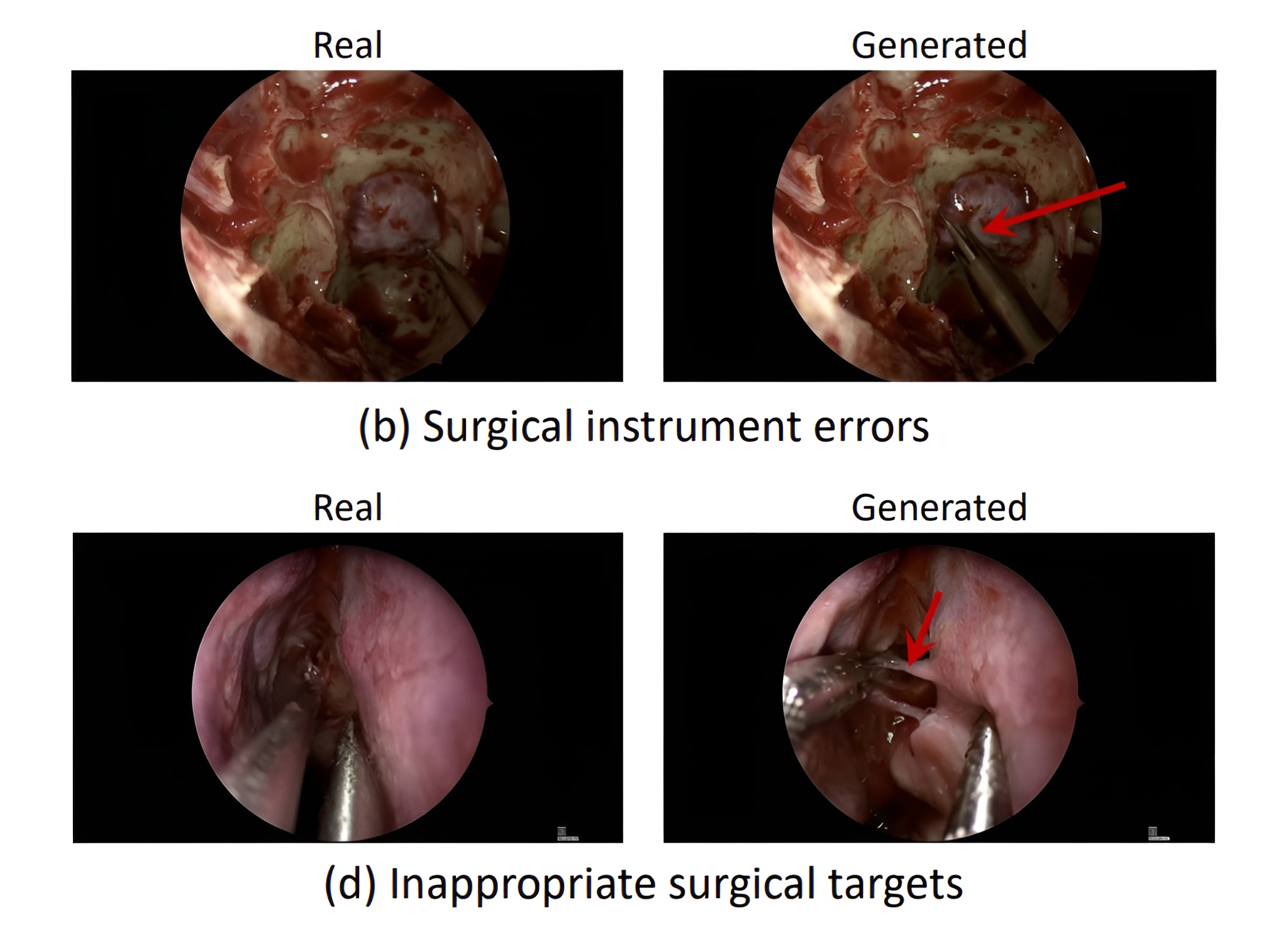
Forschende haben Googles neueste Video-KI mit chirurgischen Aufnahmen getestet. Das Ergebnis zeigt eine deutliche Kluft zwischen optischer Qualität und medizinischem Verständnis.
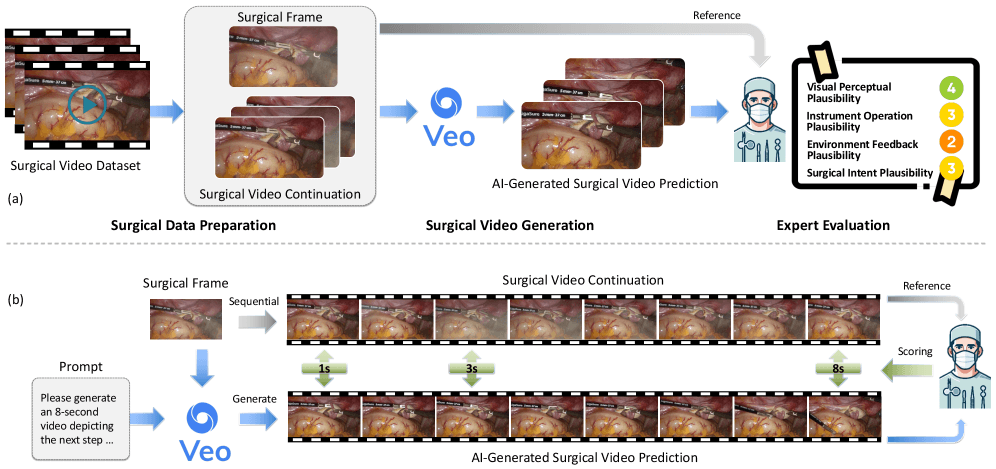
Das Veo-3-Modell von Google sollte anhand eines einzelnen Bildes vorhersagen, wie eine Operation in den nächsten acht Sekunden weitergeht. Ein internationales Forschungsteam hat dafür den SurgVeo-Benchmark mit 50 echten OP-Videos aus Bauch- und Gehirnoperationen entwickelt.
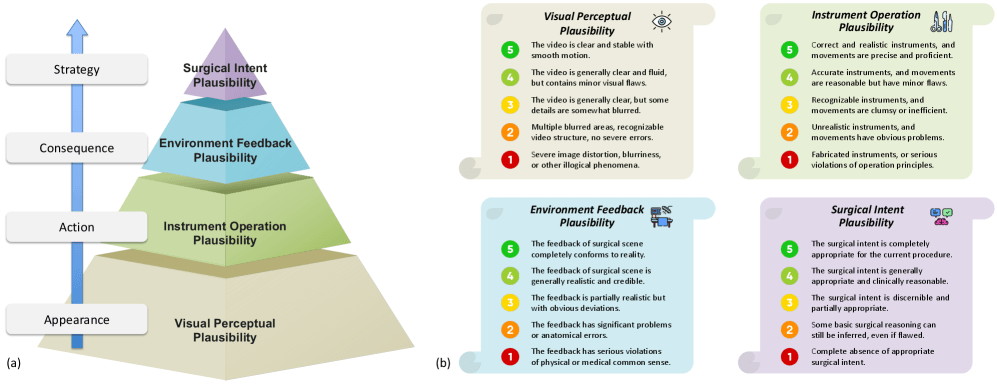
Die Bewertung übernahmen vier erfahrene Chirurg:innen. Sie prüften die KI-Videos nach vier Kriterien. Zunächst bewerteten sie das Aussehen der Videos, dann die korrekte Verwendung der Instrumente, die realistische Gewebereaktion und schließlich den medizinischen Sinn der gezeigten Aktionen.
KI beeindruckt visuell, versagt aber medizinisch
Das Ergebnis zeigt eine eklatante Diskrepanz zwischen visueller Plausibilität und tatsächlicher Wahrhaftigkeit. Zwar erzeugt Veo-3 optisch beeindruckende Videos – Chirurg:innen beschrieben die Bildqualität teils als „schockierend klar“ –, doch die inhaltliche Zuverlässigkeit blieb deutlich zurück. In Tests zu Bauchoperationen erzielte die KI bei der Bewertung der visuellen Plausibilität nach einer Sekunde immerhin 3,72 von 5 Punkten. Sobald jedoch medizinisches Fachwissen erforderlich war, brach die Leistungsfähigkeit drastisch ein.
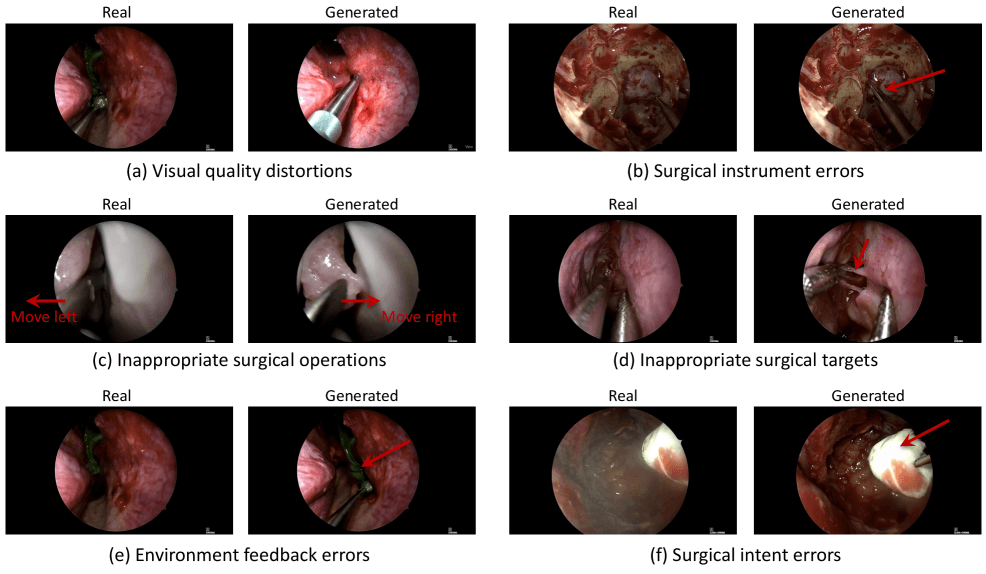
Bei Bauchoperationen bewerteten die Ärzt:innen die Instrumentenhandhabung mit nur 1,78 Punkten, die Gewebereaktionen mit 1,64 Punkten. Am schlechtesten schnitt die chirurgische Logik ab. Hier gab es nur 1,61 Punkte.
Hirn-OPs überfordern die KI besonders
Noch gravierender wurde das Problem bei Gehirnoperationen. Diese erwiesen sich als erheblich schwieriger für die KI als Baucheingriffe. Schon nach einer Sekunde zeigte sich, dass die KI mit der Präzision und den winzigen Bewegungen der Neurochirurgie nichts anfangen kann. Die Instrumentenhandhabung erreichte bei Gehirnoperationen nur 2,77 Punkte gegenüber 3,36 Punkten bei Baucheingriffen. Bei Gehirnoperationen sank die chirurgische Logik sogar auf nur noch 1,13 Punkte nach acht Sekunden.
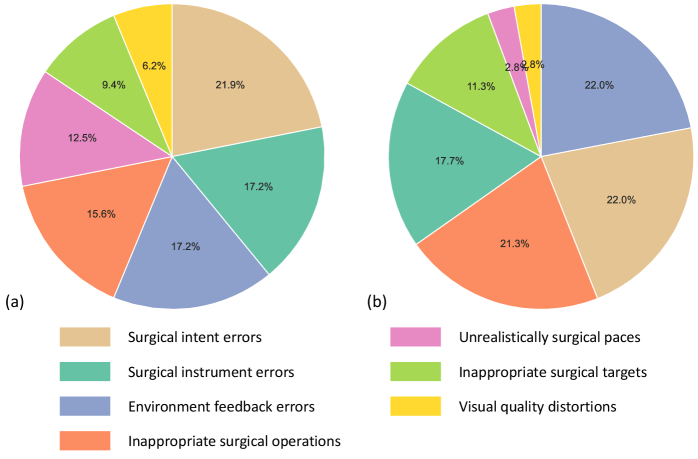
Die Forschenden analysierten auch, welche Fehler am häufigsten auftraten. Das Ergebnis war ernüchternd. Über 93 Prozent aller Probleme betrafen die medizinische Logik. Die KI erfand Instrumente, die es nicht gibt, zeigte unmögliche Gewebereaktionen oder führte Aktionen aus, die medizinisch keinen Sinn ergeben.
Nur 6,2 Prozent der Fehler bei Baucheingriffen und 2,8 Prozent bei Gehirnoperationen betrafen tatsächlich die Bildqualität. Die KI kann also visuell überzeugende OP-Videos erstellen. Sie versteht nur nicht, was in einer echten Operation passiert.
Mehr Informationen bringen keine Verbesserung
Die Wissenschaftler:innen testeten auch, ob zusätzliche Hinweise helfen. Sie gaben der KI einmal nur den Operationstyp vor, ein anderes Mal auch die genaue Phase des Eingriffs. Das Ergebnis brachte keine signifikanten oder konsistenten Verbesserungen.
Laut den Forschenden zeigt dies, dass das Kernproblem im Mangel an Fähigkeiten zur Verarbeitung von Informationen liegt – nicht an deren Verfügbarkeit.
Weiter Weg zu plausibler visueller (medizinischer) KI
Die Studie zeigt, wie weit der Weg zu praxistauglicher visueller medizinischer KI noch ist. Solche Systeme könnten künftig die Ärzteausbildung verändern, bei der präoperativen Planung unterstützen oder als Grundlage für intraoperative Leitsysteme dienen. Noch aber ist aktuelle Video-KI weit davon entfernt, medizinische Expertise zu simulieren – sie erzeugt zwar täuschend echte Bilder, doch das Verständnis dahinter fehlt.
Die Forschenden wollen ihren SurgVeo-Benchmark künftig der wissenschaftlichen Gemeinschaft über GitHub zugänglich machen, damit weitere Teams ihre Modelle testen und leistungsfähigere Ansätze entwickeln können.
Die Ergebnisse der SurgVeo-Studie verdeutlichen auch die Risiken von KI-generierten Videos als Trainingsgrundlage in der Medizin. Während Nvidia mit GR00T-Dreams erfolgreich KI-Videos nutzt, um humanoide Roboter zu schulen, wäre ein ähnlicher Ansatz im medizinischen Umfeld hochproblematisch. Systeme wie Veo-3 halluzinieren mitunter unsinnige chirurgische Eingriffe und stellen gefährliche Aktionen als plausibel dar. Synthetische Trainingsdaten könnten so Robotern falsche Techniken beibringen.
Zudem wird deutlich, dass die Idee von Videomodellen als Weltmodellen bislang eine Zukunftsvision bleibt. Aktuelle Systeme verfügen weder über ein kohärentes Verständnis der Welt noch über die Fähigkeit, Kausalzusammenhänge stabil zu erfassen. Zwar können sie Bewegungen und Abläufe überzeugend imitieren, doch es fehlt an grundlegender physikalischer und anatomischer Logik. So entstehen Videosequenzen, die oberflächlich plausibel wirken, ohne tatsächliche Handlungslogik zu begreifen.
Eine Studie zu visuellen Sprachmodellen bestätigt diese Lücke zwischen reiner Bildgenerierung und echtem Verständnis: Kein aktuelles System konnte in Tests konsistente Beziehungen zwischen Ursache und Wirkung in Videos erkennen.
Gleichzeitig gibt es textbasierte Anwendungen in der Medizin, in denen generative KI bereits beachtliche Fortschritte erzielt. Microsofts „MAI Diagnostic Orchestrator“ erreichte in einer Untersuchung bei komplexen Fällen eine viermal höhere diagnostische Genauigkeit als erfahrene Allgemeinmediziner:innen, auch wenn die Studie einige methodische Einschränkungen aufweist.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.