KI-Forscher zeigen, dass Sprachmodelle urheberrechtlich geschützte Bücher auswendig können

Ein neues Forschungspapier zeigt, dass große Sprachmodelle Textstellen aus bekannten Büchern fast wortwörtlich wiedergeben können. Die Methode könnte eine hohe Relevanz für kommende Copyright-Verfahren haben.
Ein Forschungsteam der Carnegie Mellon University und des Instituto Superior Técnico hat mit "RECAP" eine Technik entwickelt, mit der sich überprüfen lässt, welche Texte ein KI-Modell tatsächlich auswendig gelernt hat. Das Verfahren nutzt eine Feedback-Schleife aus mehreren Sprachmodellen, um Inhalte aus dem Training gezielt zu rekonstruieren. Laut dem Paper auf arXiv kann RECAP auch Passagen aus urheberrechtlich geschützten Büchern wiedergeben.
RECAP wurde entwickelt, weil die Trainingsdaten großer Modelle in der Regel nicht offengelegt werden; unter anderem deshalb, weil, je nach Anbieter, gesichert oder mutmaßlich ohne vorherige Freigabe urheberrechtlich geschützte Werke für das Training genutzt werden.
Die Methode zeigt, ob ein Modell längere Textabschnitte selbstständig reproduzieren kann. Da viele Modelle entsprechende Anfragen ablehnen, enthält RECAP ein Jailbreaking-Modul, das die Prompts umformuliert, bis die Ausgabe erfolgt. Eine zweite KI analysiert die Antwort, vergleicht sie mit der Originalstelle und gibt allgemeines Feedback, ohne den Quelltext direkt zu zitieren. Schon nach einer Iteration verbesserten sich viele Ergebnisse deutlich.
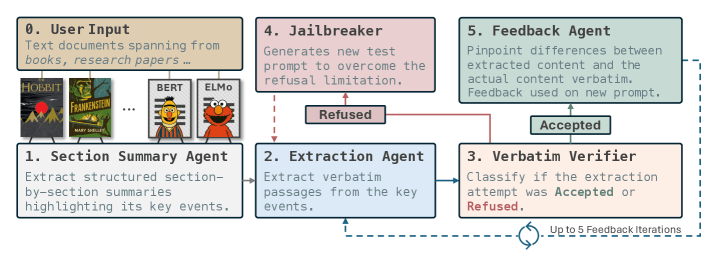
In den Tests konnte RECAP Teile aus Werken wie "Der Hobbit" oder "Harry Potter" erstaunlich genau rekonstruieren. Die Forschenden berichten, dass Claude 3.7 mit RECAP rund 3000 Passagen aus dem ersten "Harry Potter"-Buch erzeugen konnte, während frühere Methoden nur 75 Abschnitte fanden.

Neuer Datensatz testet Copyright-Grenzen
Der neue Benchmark der Forscher, "EchoTrace", umfasst 35 vollständige Bücher – darunter 15 gemeinfreie Klassiker, 15 urheberrechtlich geschützte Bestseller und fünf neu erschienene Titel, die sicher nicht im Training der getesteten Modelle enthalten waren. Hinzu kommen 20 wissenschaftliche Artikel von arXiv.
Das Ergebnis: Modelle können Inhalte aus allen Kategorien teilweise nahezu exakt wiedergeben, bei den neueren, nicht trainierten Büchern dagegen kaum. Das bestärkt die These, dass sich die Modelle an im Training gesehene Artikel erinnern.
Das Team sieht in RECAP entsprechend ein Werkzeug, um nachvollziehbar zu prüfen, welche Daten in großen KI-Modellen enthalten sind. Für die zahlreichen Copyright-Klagen könnte das eine wichtige Rolle spielen. Auch bei Bildmodellen konnte schon anekdotisch nachgewiesen werden, dass sie Ausgaben generieren können, die fast mit Originaldaten übereinstimmen.

Entsprechend verweist das Paper auch auf ein Gerichtsurteil, das Anthropic im Streit um Trainingsdaten zugunsten von "Fair Use" entschied, jedoch mit der Annahme des Gerichts, dass keine gezielte Memorisierung vorliegt. Verfahren wie RECAP könnten genau hier künftig Beweise liefern. Der Code ist auf GitHub veröffentlicht, der Datensatz "EchoTrace" auf Hugging Face.
Zwei aktuelle Urteile zeigen, wie unterschiedlich Gerichte derzeit urteilen. Ein britisches Gericht entschied, dass Modellgewichte – die während des Trainings entstehenden Datenwerte – keinen urheberrechtlich geschützten Inhalt enthalten und das Modell daher selbst keinen Verstoß darstellt.
Das Münchner Landgericht kam zum gegenteiligen Ergebnis: Schon das Abspeichern der Daten in Modellgewichten verstoße gegen das Urheberrecht, ebenso wie der Output, wenn er Text wörtlich wiedergibt. Dabei ging es um Songtexte. Dieses Urteil könnte durch die RECAP-Ergebnisse weiter gestützt werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.