Deepmind-Studie will Maschinenblick und menschliche Wahrnehmung aufeinander abstimmen

Ein Forschungsteam von Google Deepmind, deutschen Partnern und Anthropic hat eine Methode vorgestellt, mit der KI-Modelle menschliche Urteilsmuster in der visuellen Wahrnehmung besser nachvollziehen sollen. Die Studie in Nature zeigt, dass solche „human-aligned“ Modelle robuster, generalisierungsfähiger und weniger fehleranfällig sind.
Tiefe neuronale Netze imitieren in der Bildverarbeitung menschliche Leistungen, versagen aber oft unter ungewohnten Bedingungen. Laut der in Nature veröffentlichten Studie „Aligning machine and human visual representations across abstraction levels“ unterscheiden sich Mensch und Modell grundlegend: Menschen ordnen visuelle Konzepte hierarchisch, also von feinen zu groben Bedeutungsstufen, während maschinelle Modelle lokale Ähnlichkeiten zwar gut, abstraktere Zusammenhänge aber kaum erfassen.
Dieses Missverhältnis betrifft zentrale Dimensionen der Wahrnehmung wie die Zuordnung von Objekten (zum Beispiel Hund–Fisch als „belebt“, aber visuell verschieden) oder die Einschätzung von Unsicherheit. Menschliche Einschätzungen sind tendenziell konsistent mit ihrer Genauigkeit, wohingegen KI-Modelle oft hohe Sicherheit auch bei Fehlschlüssen zeigen.

„AligNet“: Ein Zwischenschritt zu menschenähnlicher Wahrnehmung
Um die Diskrepanz zu verringern, entwickelten Lukas Muttenthaler und sein Team den Ansatz AligNet. Kern ist ein sogenanntes „Surrogate Teacher Model“, eine Version des multimodalen Modells SigLIP, das an menschliche Urteile aus dem Datensatz THINGS angepasst wurde.
Dieses „Lehrer“-Modell simuliert menschliche Ähnlichkeitsurteile für Millionen synthetisch erzeugter Bilder aus ImageNet und liefert sogenannte „pseudomenschliche“ Softlabels. Damit wurden verschiedene vortrainierte Computer-Vision-Modelle, darunter Vision Transformer (ViT) und selbstüberwachte Modelle wie DINOv2, feinjustiert. Das Ergebnis: Die so abgestimmten Modelle stimmten deutlich häufiger mit menschlichen Urteilen überein, insbesondere bei abstrakten Vergleichsaufgaben.
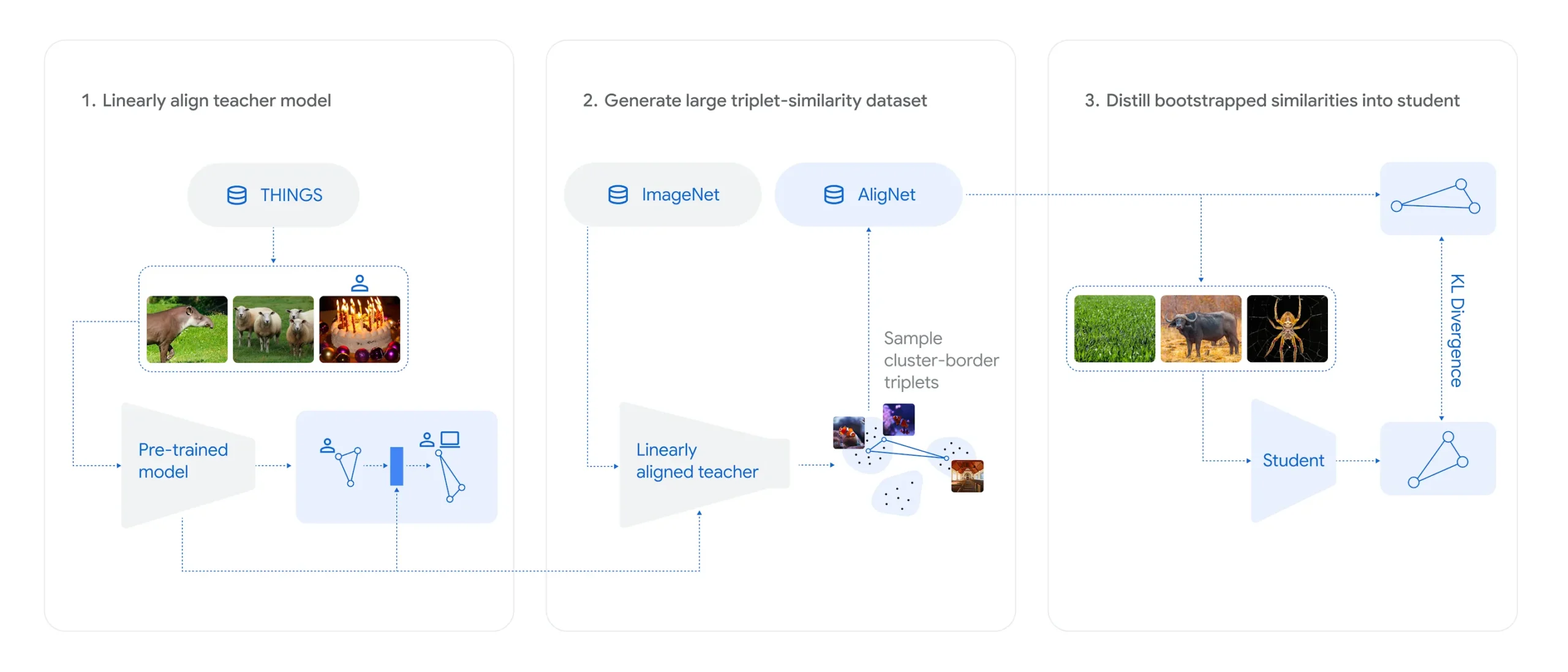
Auf dem neuen „Levels“-Datensatz, der Urteile von 473 Versuchspersonen auf mehreren Abstraktionsebenen erfasst, übertraf ein AligNet-modelliertes ViT-B sogar die Übereinstimmung unter menschlichen Teilnehmern.
Menschliche Struktur verbessert maschinelle Robustheit
Der Abgleich blieb nicht nur kognitiv relevant, sondern zeigte messbare technische Vorteile. Laut der Studie verbesserten die AligNet-Modelle ihre Treffergenauigkeit in Generalisierungs- und Robustheitstests teils um über 100 Prozent im Vergleich zu Basisversionen.
Auch gegenüber anspruchsvollen Benchmarks wie dem BREEDS-Datensatz, der Verteilungen zwischen Trainings- und Testdaten verschiebt, erwiesen sich die „human-aligned“ Varianten als stabiler. Sogar auf dem adversarialen ImageNet-A stiegen die Genauigkeitswerte um bis zu 9,5 Prozentpunkte. AligNet-Modelle zeigten außerdem ein besseres Verständnis von Unsicherheit, deren Schätzungen eng mit der Reaktionszeit menschlicher Testpersonen korrelierten – ein Hinweis auf realistischeres Entscheidungsverhalten.
Die Reorganisation der internen Repräsentationen zeigte zudem, dass Modelle nach der Anpassung Objekte nicht mehr nur optisch, sondern auch semantisch gruppierten: Echsen rücken näher an Tiere statt an gleichfarbige Pflanzenbilder.
Was das für zukünftige KI-Modelle bedeutet
Laut Muttenthaler und Kollegen deutet der Ansatz auf einen möglichen Weg zu interpretierbareren und vertrauenswürdigeren KI-Systemen hin. Durch die Integration menschlicher Ähnlichkeitsstrukturen könnten Foundation Models stabiler auf neue Situationen reagieren. Die Forschenden betonen zugleich, dass vollkommene Menschenähnlichkeit kein Ziel sein müsse – menschliche Urteile seien selbst von kulturellen und individuellen Verzerrungen geprägt.
Die Trainingsdaten und Modelle des Projekts AligNet sind offen verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.