OpenAI-Forscher enthüllt Details zu neuem KI-Modell mit möglichem Leistungssprung

OpenAI-Forscher Jerry Tworek hat Details zu OpenAIs neuem KI-Modell geteilt, das einen größeren Leistungssprung bringen könnte, zumindest in einigen Bereichen.
Das Modell, intern als „IMO-Goldmedaillengewinner“ bekannt, soll in den kommenden Monaten in einer „deutlich verbesserten Version“ erscheinen. Aktuell befinde es sich noch im Forschungsstadium und werde für den öffentlichen Einsatz weiterentwickelt, so Tworek.
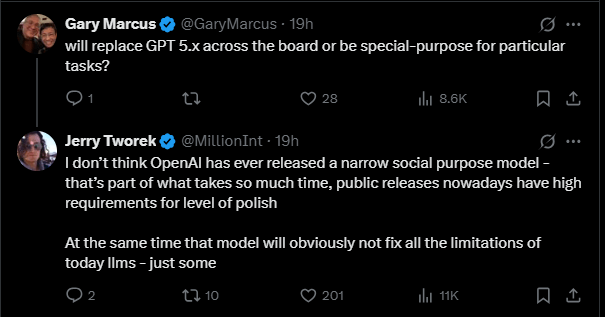
Auf eine Frage von OpenAI-Kritiker Gary Marcus, ob das Modell GPT-5.x vollständig ersetzen oder ein spezialisiertes System für bestimmte Aufgaben werden solle, antwortete Tworek, dass OpenAI bislang keine Modelle mit engem Einsatzzweck veröffentlicht habe. Das neue Modell werde zwar Fortschritte machen, aber "offensichtlich nicht alle Schwächen heutiger Sprachmodelle beseitigen" – aber immerhin "einige davon."
Die Frage nach der Generalisierbarkeit ist deshalb brisant, weil OpenAI bei der Vorstellung des IMO-Modells betont hatte, dass es nur "sehr wenig" auf die Anforderungen der Mathematik-Olympiade hin optimiert worden sei. Vielmehr handle es sich um ein generalistisches Modell, das auf allgemeinen Fortschritten im Reinforcement Learning und erhöhter Rechenleistung basiere – ohne Zugriff auf spezialisierte Werkzeuge wie Code-Interpreter außerhalb natürlicher Sprache.
Gerade die Übertragung von Reinforcement Learning auf Aufgaben, bei denen es keine eindeutig richtige oder falsche Antwort gibt, gilt weiterhin als ungelöstes Problem. Ein Durchbruch in diesem Bereich wäre beinahe ein Beleg dafür, dass das noch junge Paradigma des Reasoning-Modell-Skalierens tatsächlich den massiven Rechenausbau rechtfertigt, der zentrales Thema der aktuellen Diskussion um eine mögliche KI-Blase ist.
Verifizierbarkeit als strukturelle Grenze für LLMs
Parallel dazu beschreibt der frühere OpenAI- und Tesla-Forscher Andrej Karpathy ein zentrales Strukturproblem: Im Paradigma der „Software 2.0“ sei nicht die Spezifizierbarkeit einer Aufgabe entscheidend, sondern ihre Verifizierbarkeit. Nur wenn ein System automatisiertes Feedback erhält – etwa durch richtig/falsch-Bewertungen oder klare Belohnungsstrukturen –, kann es durch Reinforcement Learning effizient trainiert werden.
„Je verifizierbarer eine Aufgabe ist, desto besser lässt sie sich im neuen Programmierparadigma automatisieren“, schreibt Karpathy. „Ist sie nicht verifizierbar, bleibt nur die Hoffnung auf Generalisierungs-Magie neuronaler Netze – oder schwächere Verfahren wie Imitation.“ Genau diese Dynamik treibe die „zerklüftete Frontlinie“ der LLM-Entwicklung an.
Software 1.0 easily automates what you can specify. Software 2.0 easily automates what you can verify.
Verifizierbare Aufgaben wie Mathematik, Programmieren oder strukturierte Spiele zeigen daher besonders schnelle Fortschritte – teilweise über das Niveau menschlicher Experten hinaus. Auch die Mathe-Olympiade fällt in diese Kategorie. Im Gegensatz dazu stagnieren kreative, strategische oder kontextabhängige Aufgaben, bei denen keine klare Rückmeldung möglich ist.
Die Einschätzungen von Tworek und Karpathy ergänzen sich: Fortschritte wie beim IMO-Modell deuten darauf hin, dass verifizierbare Aufgaben durch das Reasoning-Skalierungsparadigma tatsächlich systematisch lösbar werden; und das wären viele. Für andere Aufgaben bleibt es jedoch beim Prinzip Hoffnung.
KI-Fortschritte, die Nutzer kaum noch spüren
Allerdings könnten übermenschlich leistungsfähige Modelle in verifizierbaren Domänen wie der Mathematik dennoch die Forschung beschleunigen – etwa bei Beweisen, Optimierungsfragen oder Modellbildung. Das bedeutet jedoch nicht zwangsläufig, dass normale Nutzer solche Fortschritte im Alltag bemerken.
OpenAI hatte zuletzt angedeutet, dass viele Nutzer die tatsächlichen Verbesserungen moderner KI-Modelle nicht mehr erkennen, weil die alltäglichen Aufgaben für Sprachmodelle inzwischen meist trivial seien – zumindest im Rahmen ihrer bekannten Einschränkungen wie Halluzinationen oder faktische Fehler. Während sich die Forschung auf immer komplexere, schwer messbare Leistungsbereiche verlagert, bleibt der gefühlte Fortschritt für viele Nutzer unsichtbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.