Metas neues KI-Modell SAM 3 verbindet Sprache und Vision flexibler als zuvor
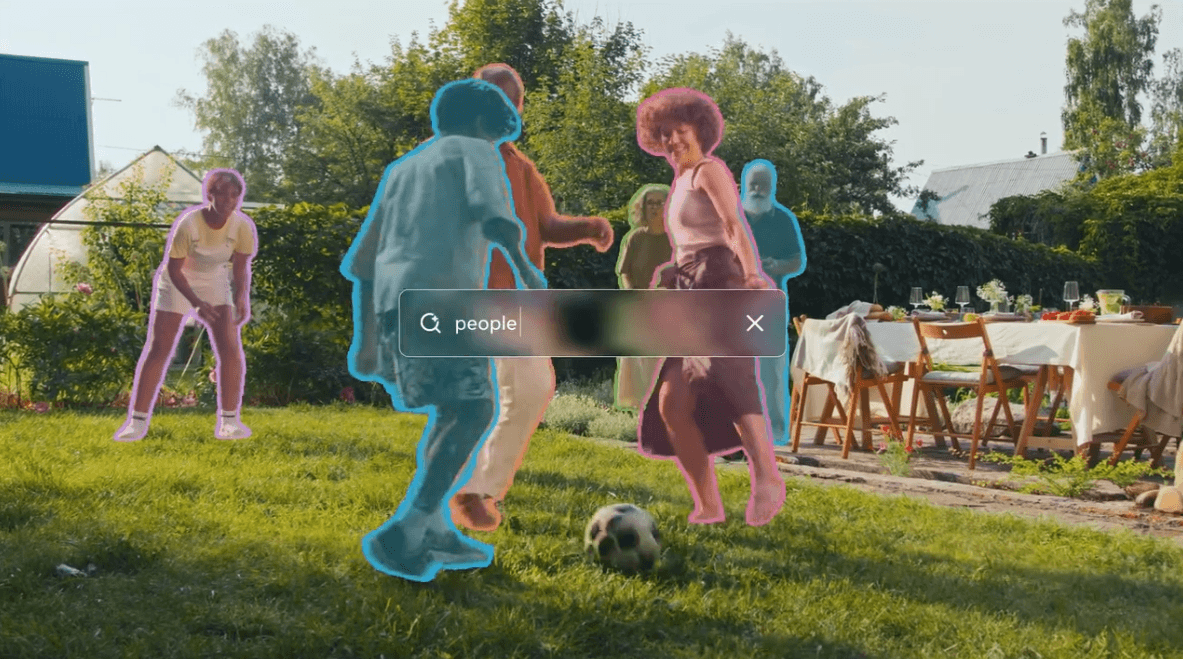
Meta veröffentlicht die dritte Generation seines "Segment Anything Model". SAM 3 soll Bilder und Videos gleichermaßen verstehen und setzt auf eine neue Trainingsmethode, die menschliche und künstliche Annotatoren kombiniert.
Im Gegensatz zu früheren Ansätzen, die oft auf ein festes Set an Begriffen beschränkt waren, soll SAM 3 über ein offenes Vokabular verfügen. Nutzer können dem Modell Text-Prompts oder Beispielbilder ("Exemplar Prompts") geben, um spezifische visuelle Konzepte zu isolieren.
Zusätzlich zur Veröffentlichung der Modellgewichte und des Codes stellt Meta den Segment Anything Playground bereit, eine Web-Oberfläche, auf der Interessierte das Modell testen können.
Abkehr von starren Labels
Eine der zentralen Herausforderungen in der Computer Vision ist laut Meta die Verknüpfung von Sprache mit visuellen Elementen. Herkömmliche Modelle könnten zwar häufige Objekte wie "Person" erkennen, scheiterten aber oft an nuancierten Beschreibungen wie "der gestreifte rote Regenschirm", da sie auf vordefinierte Kategorien trainiert seien.
SAM 3 führt daher die sogenannte "Promptable Concept Segmentation" ein. Das Modell akzeptiert kurze Nomen-Phrasen oder Beispielbilder als Eingabe, um alle Instanzen dieses Konzepts in einem Medium zu finden. Die aus SAM 1 und SAM 2 bekannten visuellen Prompts – wie Masken, Begrenzungsrahmen (Boxes) oder Punkte – werden weiterhin unterstützt. Klassische Eingaben wie Masken oder Punkte bleiben weiterhin möglich.
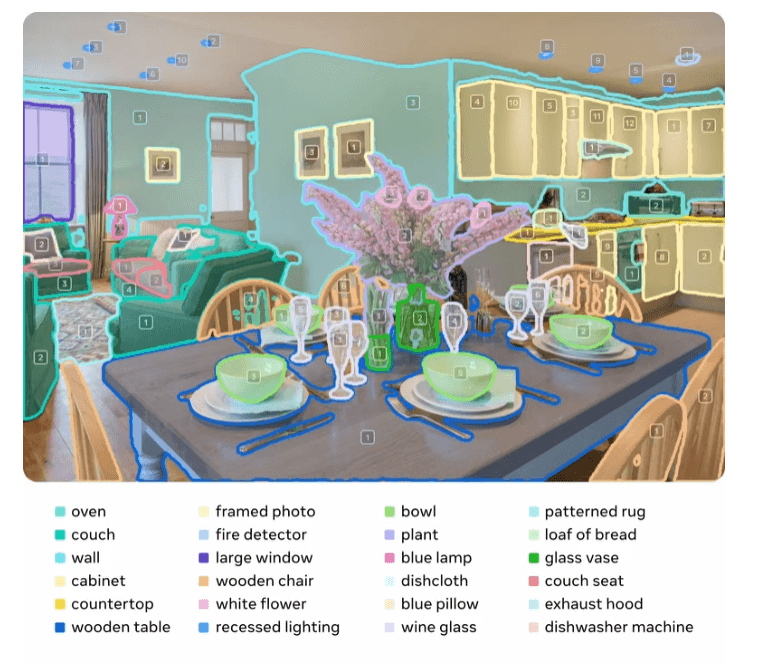
In internen Benchmarks, speziell dem neu eingeführten "Segment Anything with Concepts" (SA-Co), soll SAM 3 eine doppelt so hohe Leistung wie existierende Systeme erreichen. In Vergleichstests übertrifft SAM 3 laut Meta sowohl spezialisierte Modelle wie GLEE und OWLv2 als auch große multimodale Modelle wie Gemini 2.5 Pro.

Data Engine und Architektur
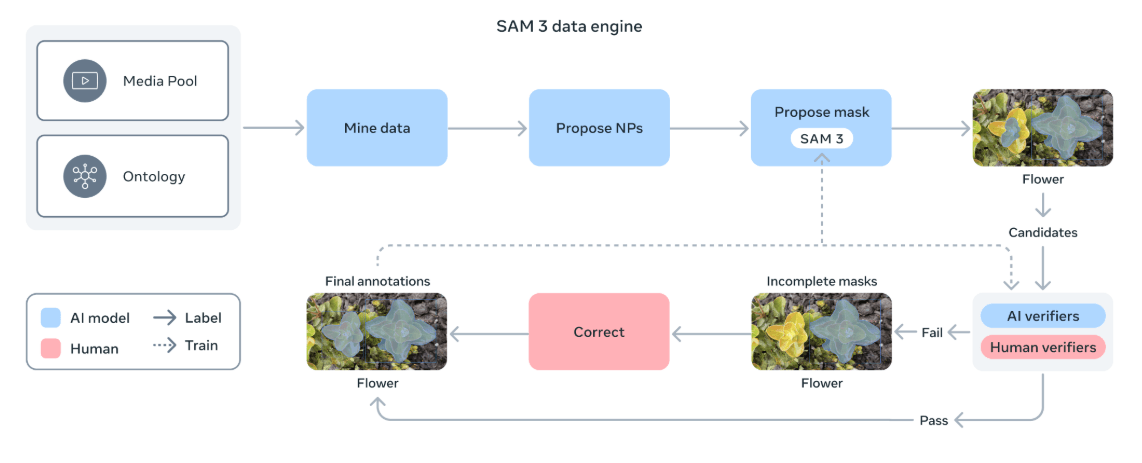
Für das Training entwickelte Meta eine hybride "Data Engine": Eine Pipeline aus KI-Modellen, darunter SAM 3 und ein Llama‑basiertes Captioning, erzeugt initiale Segmentierungsmasken; anschließend prüfen und korrigieren menschliche und KI‑Annotatoren die Vorschläge.
Laut dem Forschungspapier beschleunigt dieser Prozess die Annotation erheblich: Die KI-Unterstützung sei bei negativen Prompts (Objekt nicht vorhanden) rund fünfmal schneller als reine Handarbeit und bei positiven Prompts immerhin 36 Prozent effizienter. Das Resultat ist ein Trainingsdatensatz mit mehr als vier Millionen einzigartigen Konzepten.
Meta integriert die Technologie bereits in eigene Produkte. Auf dem Facebook Marketplace soll SAM 3 die Funktion "View in Room" ermöglichen, mit der Nutzer Möbelstücke virtuell in ihrem Zuhause platzieren können. In der Videobearbeitungs-App "Edits" von Instagram soll das Modell Effekte ermöglichen, die nur auf bestimmte Personen oder Objekte angewendet werden.
Die Inferenzgeschwindigkeit von SAM 3 gibt Meta mit 30 Millisekunden pro Bild für über 100 erkannte Objekte auf einer Nvidia H200-GPU an. Bei Videos skaliere die Latenz mit der Anzahl der Objekte, ermögliche aber bei etwa fünf gleichzeitigen Objekten eine Verarbeitung nahezu in Echtzeit.
Meta nennt auch einige Limitationen: SAM 3 habe Schwierigkeiten bei sehr spezifischen Fachbegriffen außerhalb seines Trainingsbereichs ("Zero-Shot"), etwa in der medizinischen Bildanalyse. Zudem scheitere das Modell bei komplexen, logischen Beschreibungen wie "das vorletzte Buch von rechts im oberen Regal". Hierfür schlägt Meta den Einsatz von SAM 3 in Kombination mit multimodalen Sprachmodellen vor. Meta nennt diese Kombination den "SAM 3 Agent".
SAM 3D: Räumliches Verständnis für Objekte und Menschen
Parallel zu SAM 3 veröffentlichte Meta SAM 3D, ein Paket aus zwei neuen Modellen, die 3D-Rekonstruktionen aus einzelnen 2D-Bildern ("Single Image") ermöglichen sollen.
SAM 3D Objects konzentriert sich auf die Rekonstruktion von Objekten und Szenen. Da 3D-Trainingsdaten im Vergleich zu 2D-Bildern extrem rar sind, wandte Meta auch hier das Prinzip der "Data Engine" an: Statt 3D-Modelle aufwendig von Künstlern erstellen zu lassen, mussten Annotatoren lediglich von der KI generierte Gittermodelle (Meshes) bewerten und auswählen. Auf diese Weise wurden laut Meta fast eine Million Bilder mit 3D-Informationen annotiert. Das System soll in der Lage sein, aus einem Foto ein manipulierbares 3D-Objekt zu erstellen.
Das zweite Modell, SAM 3D Body, ist auf die Erfassung menschlicher Posen und Formen spezialisiert. Es nutzt das neue Format "Meta Momentum Human Rig" (MHR), das die Skelettstruktur von der Weichteilform trennt. Trainiert mit rund acht Millionen Bildern, soll das Modell auch bei Verdeckungen oder ungewöhnlichen Körperhaltungen robust funktionieren.
Meta räumt jedoch ein, dass die Technologie noch am Anfang steht. Die Auflösung der generierten 3D-Objekte sei moderat, was bei komplexen Strukturen zu Detailverlust führe. Zudem betrachte SAM 3D-Objects Objekte isoliert und könne physikalische Interaktionen zwischen mehreren Objekten bisher nicht korrekt abbilden. Auch bei der Hand-Erkennung durch SAM 3D Body erreicht das Modell laut Meta bislang nicht die Präzision spezialisierter Hand-Tracking-Tools.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.