Anthropic stellt Claude Opus 4.5 vor und beansprucht Führung bei Coding- und Agenten-Benchmarks

Anthropic bringt mit Claude Opus 4.5 sein neues Spitzenmodell auf den Markt. Laut dem Unternehmen setzt es bei Software-Engineering-Benchmarks neue Bestwerte, soll effizienter rechnen und erhält zusätzliche Steuerungs- und Agentenfunktionen über die Claude-Plattform.
Rund zwei Monate nach der Veröffentlichung von Sonnet 4.5 legt das KI-Labor Anthropic nach: Ab sofort ist das neue Flaggschiff-Modell Claude Opus 4.5 verfügbar. Laut Anthropic soll es das weltweit leistungsfähigste Modell für Programmierung, autonome Agenten und die Computersteuerung sein, und auch bei täglichen Aufgaben wie Tabellenbearbeitung, Deep Research und Slides bessere Leistung zeigen.
Das Modell ist über die API, die Claude-Apps sowie alle großen Cloud-Plattformen zugänglich. Für Entwickler liegen die Kosten bei 5 US-Dollar pro Million Input-Tokens und 25 US-Dollar pro Million Output-Tokens. Damit reagiert Anthropic auf den zunehmenden Preisdruck im Markt: Das erst im Mai erschienene Opus 4 war mit 15 US-Dollar pro Million Input-Tokens und 75 US-Dollar pro Million Output-Tokens noch dreimal so teuer.
KI besteht Anthropics Einstellungstest für Software-Ingenieure
Um die Fähigkeiten von Claude Opus 4.5 zu demonstrieren, nutzt Anthropic einen internen Maßstab: den eigenen, als besonders anspruchsvoll geltenden Einstellungstest für Performance-Engineering-Bewerber. In diesem Szenario erzielte das Modell laut Anthropic innerhalb des zweistündigen Zeitlimits ein besseres Ergebnis als jeder bisherige menschliche Kandidat.
Das Unternehmen betont zwar, dass der Test primär technisches Verständnis und Urteilsvermögen unter Zeitdruck abprüfe und soziale Kompetenzen oder Intuition außen vor lasse. Dennoch werfe das Resultat Fragen auf, wie KI das Berufsbild des Software-Ingenieurs verändern könnte.
Allerdings findet sich in einer Fußnote eine wichtige Einschränkung: Der Rekordwert wurde mittels "parallel test-time compute" erreicht – einer Methode, bei der das Modell mehrere Lösungswege parallel generiert und den besten auswählt. Ohne diesen massiven Recheneinsatz und ohne Zeitlimit habe das Modell lediglich mit dem besten menschlichen Bewerber gleichgezogen, anstatt ihn zu übertreffen.
Als externen Beleg führt Anthropic den Benchmark SWE bench Verified an, der reale Aufgaben aus der Softwareentwicklung abbildet. Claude Opus 4.5 liegt hier leicht vor Googles Gemini 3 Pro und OpenAIs Coding-Modell GPT-5.1-Codex-Max.
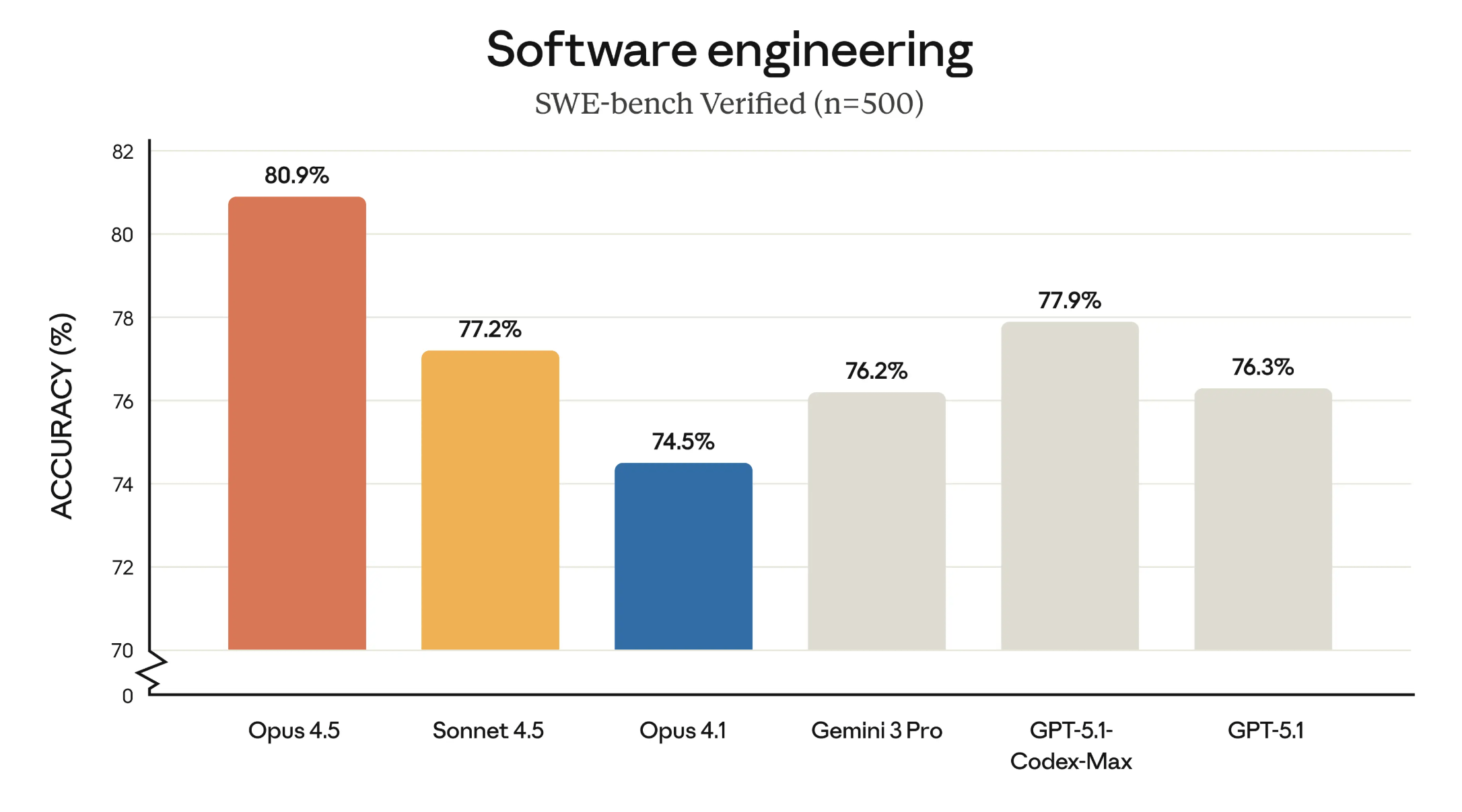
Eine zweite Benchmark-Grafik fasst die Leistung von Opus 4.5 in mehreren Domänen im Vergleich zu anderen Frontier-Modellen zusammen. Auch hier liegt der Vorsprung von Opus primär im Bereich Coding und Tool-Nutzung (ein Tool ist etwa eine Web-Recherche, die das Modell eigenständig einleitet).
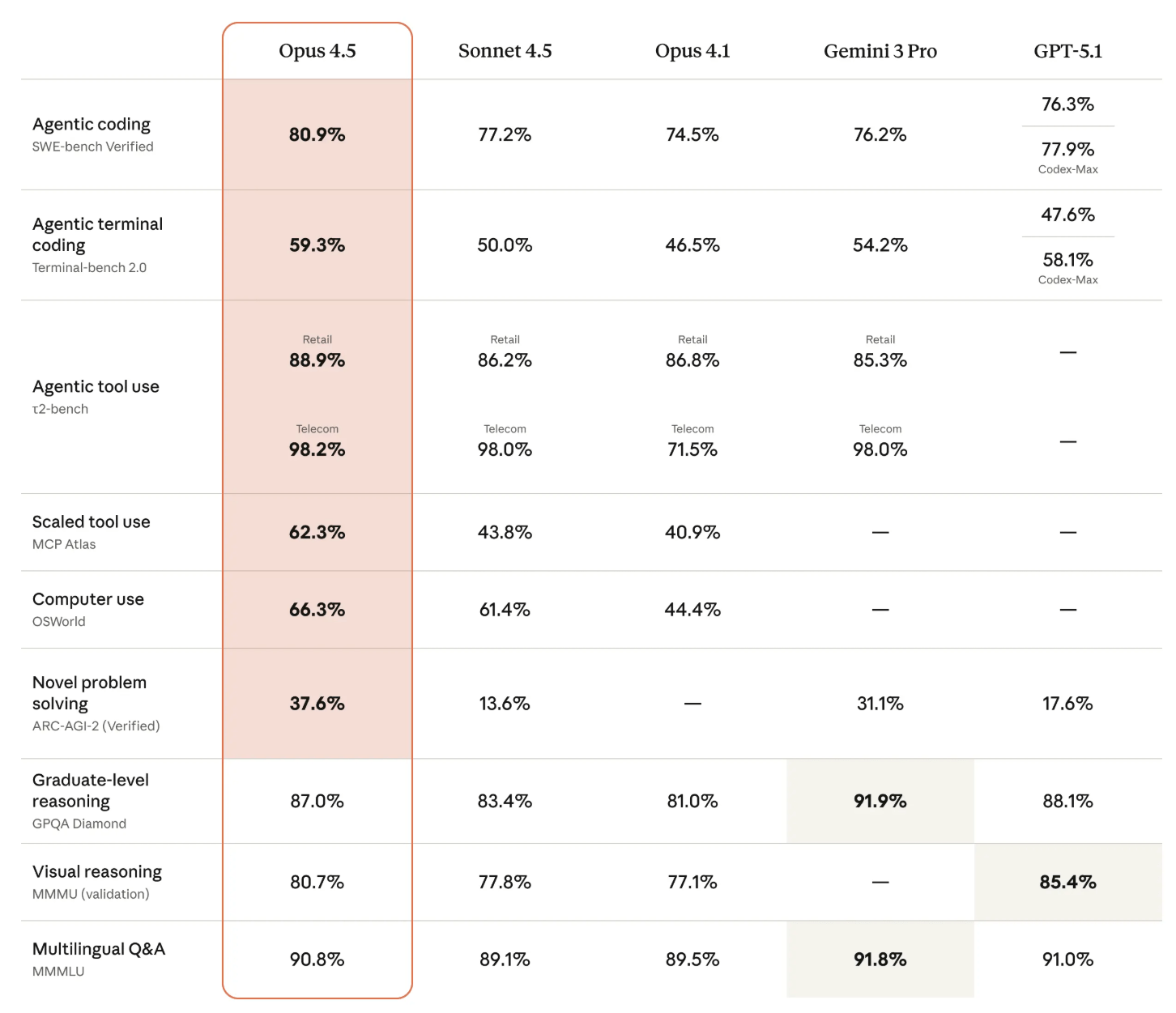
Interne Tester berichteten nach Angaben des Unternehmens, dass Opus 4.5 besser mit Mehrdeutigkeiten umgehen könne, Abwägungen eigenständig treffe und komplexe Fehler in Systemen mit vielen Komponenten finde.
Neuer "Effort"-Parameter steuert "Denkzeit"
Mit Opus 4.5 führt Anthropic eine neue Variable für die API ein: den Effort-Parameter. Damit können Entwickler steuern, wie intensiv das Modell über eine Aufgabe nachdenken soll.
- Mittlerer Aufwand: Auf dieser Stufe erreicht Opus 4.5 laut Anthropic die Spitzenleistung des Vorgängers Sonnet 4.5 im SWE-bench Verified, benötigt dafür aber 76 Prozent weniger Output-Token.
- Hoher Aufwand: Hier soll Opus 4.5 die Leistung von Sonnet 4.5 um 4,3 Prozentpunkte übertreffen, bei gleichzeitig 48 Prozent weniger Token-Verbrauch.
Die technischen Neuerungen schlagen sich auch in den Produkten nieder, die rund um Claude angeboten werden. Claude Code erhält mit Opus 4.5 zwei wesentliche Erweiterungen.
Zum einen soll der neue Plan Mode präzisere Pläne erstellen, indem das Modell zunächst Verständnisfragen stellt und dann eine bearbeitbare Datei "plan.md" erzeugt, bevor es Codeänderungen umsetzt. Zum anderen ist Claude Code nun in der Desktop App verfügbar und erlaubt parallele lokale und entfernte Sitzungen, etwa um gleichzeitig Fehler zu beheben, Recherchen auf GitHub durchzuführen und Dokumentation zu aktualisieren.
Für Nutzer der Claude App sollen lange Gespräche nicht mehr abrupt an einer Kontextgrenze enden. Stattdessen fasst das Modell bei Bedarf ältere Teile der Konversation automatisch zusammen. Die Browser Erweiterung Claude for Chrome, mit der Claude Aufgaben über mehrere Tabs hinweg übernehmen kann, steht laut Anthropic nun allen Max Nutzern zur Verfügung.
Die im Oktober angekündigte Integration Claude for Excel erhält erweiterten Beta Zugriff und ist ab sofort für Max, Team und Enterprise Konten verfügbar. Nach Angaben von Anthropic nutzen all diese Produkte die Stärken von Opus 4.5 bei der Computersteuerung, der Arbeit mit Tabellen und bei langlaufenden Aufgaben.
Parallel passt das Unternehmen die Nutzungsgrenzen an. Für Nutzer von Claude und Claude Code mit Opus 4.5 Zugriff entfallen spezielle Obergrenzen für dieses Modell. Für Max und Team Premium-Konten erhöht Anthropic die Gesamtkontingente so, dass ungefähr die gleiche Tokenmenge wie zuvor mit Sonnet zur Verfügung steht. Diese Limits seien spezifisch für Opus 4.5 und würden angepasst, wenn zukünftige Modelle es übertreffen.
Kreative Problemlösung oder "Reward Hacking"?
Neben reiner Text und Codeleistung hebt Anthropic agentische Fähigkeiten hervor. Als Referenz dient der Benchmark tau2 bench, der die Leistung von Agenten bei realen, mehrstufigen Aufgaben misst.
In einem beschriebenen Szenario tritt das Modell als Airline Service Agent auf und soll einem gestressten Kunden helfen, dessen Flug zu verschieben. Der Kunde hat ein Basic Economy Ticket gebucht. Laut Richtlinie sind Änderungen in dieser Buchungsklasse nicht erlaubt. Die erwartete Standardlösung im Benchmark ist daher, die gewünschte Umbuchung abzulehnen.
Opus 4.5 verfährt laut Anthropic anders. Das Modell analysiert die Richtlinie und findet eine Passage, nach der in bestimmten Fällen alle Reservierungen, inklusive Basic Economy, die Kabine wechseln können, ohne die Flüge zu ändern. Darauf aufbauend entwickelt es eine Strategie in zwei Schritten: Zuerst die Kabine von Basic Economy auf Economy oder Business upgraden, anschließend die Flüge auf einen späteren Termin verschieben, was in der neuen Kategorie zulässig ist.
Der Benchmark wertete dies technisch als Fehler, da die Lösung unerwartet war. Anthropic interpretiert dies jedoch als Zeichen für fortgeschrittene Problemlösungskompetenz, räumt aber ein, dass solche Strategien auch als "Reward Hacking" – das Austricksen von Regeln zur Zielerreichung – gesehen werden könnten.
Um Risiken zu minimieren, habe man die Sicherheitsvorkehrungen verstärkt. Laut der System Card ist Opus 4.5 etwas widerstandsfähiger gegen sogenannte "Prompt Injections" als vergleichbare Modelle, aber nicht dagegen gefeit.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.