Deepseek erreicht laut eigenen Angaben Gold-Niveau bei der Mathe-Olympiade

Das chinesische Start-up Deepseek meldet mit seinem neuen Modell DeepSeekMath-V2 Erfolge auf höchstem Niveau und bleibt damit den westlichen KI-Laboren auf den Fersen.
Das neue Modell DeepSeekMath-V2 erzielte laut Hersteller bei der Internationalen Mathematik-Olympiade (IMO) 2025 und der chinesischen CMO 2024 Ergebnisse auf Goldmedaillen-Niveau. Beim Putnam-Wettbewerb erreichte die KI 118 von 120 Punkten und übertraf damit das beste menschliche Ergebnis von 90 Punkten.
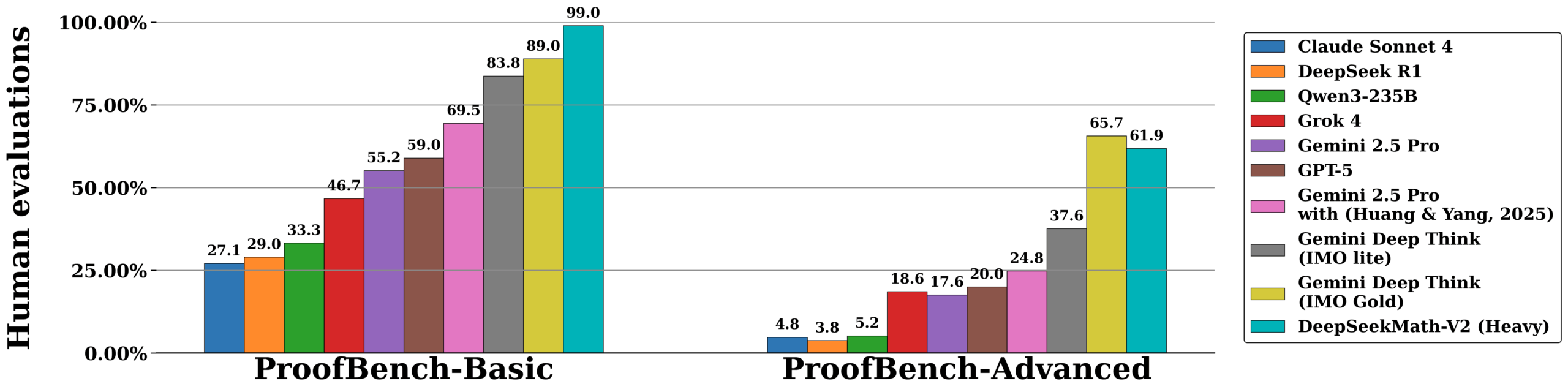
Deepseek erklärt in der technischen Dokumentation, dass bisherige KIs oft korrekte Endergebnisse lieferten, ohne den mathematischen Lösungsweg sauber herzuleiten. Um dies zu beheben, nutzt das neue Modell einen mehrstufigen Prozess. Ein sogenannter „Verifier“ bewertet die Beweise, während ein „Meta-Verifier“ kontrolliert, ob die gefundene Kritik berechtigt ist. Das System lernt so, eigene Lösungen noch während der Erstellung zu prüfen und iterativ zu verbessern.

Das Paper macht keine explizite Aussage dazu, ob während der Tests externe Hilfsmittel wie Taschenrechner oder Code-Interpreter verwendet wurden, aber das Vorgehen legt nahe, dass das nicht der Fall war. Beschrieben wird, dass alle Experimente mit einem einzigen Modell durchgeführt wurden, das sowohl Beweisgenerierung als auch -verifikation übernimmt. Der Schwerpunkt liegt darauf, dass das Modell seine eigenen Beweise bewertet und iterativ verbessert. Bei komplexen Aufgaben skaliert das System die Rechenleistung und prüft parallel viele Lösungswege. Das Modell basiert technisch auf Deepseek-V3.2-Exp-Base.
Chinas KI-Start-ups sind US-Laboren weiter auf den Fersen
Zuvor hatten OpenAI und Google Deepmind angekündigt, dass bislang unveröffentlichte KI-Modelle bei Mathematik und Coding neue Bestwerte erzielt hätten, die bislang Menschen vorbehalten waren. Bemerkenswert ist das deshalb, weil bisher davon ausgegangen wurde, dass Sprachmodelle derart komplexe Aufgaben nicht allein durch natürliche Sprache lösen könnten.
Zudem sollen diese KI-Modelle wenig für den Mathewettbewerb optimiert worden sein, sondern ihren Erfolg durch generelle Logik erzielt haben. Das ist ein Indiz für weiteren schnellen Fortschritt in der KI-Entwicklung. Ein OpenAI-Forscher kündigte kürzlich an, dass eine nochmals deutlich verbesserte Version ihres Mathemodells in den kommenden Monaten veröffentlicht werden soll.
Die Veröffentlichung von Deepseek ist besonders bemerkenswert, da das chinesische Start-up damit beweist, den westlichen Laboren weiter auf den Fersen zu sein. Zwar galten die Erfolge von OpenAI und Google im Sommer als wichtiger Schritt, doch Details zu Rechenaufwand oder Architektur blieben unbekannt. Deepseek agiert hier deutlich transparenter.
Das kann auch als weiterer Angriff auf die westliche KI-Ökonomie gewertet werden, ein Kunststück, das Deepseek bereits Anfang des Jahres gelang: Wie der Economist berichtet, setzen viele US-KI-Start-ups aus Kostengründen inzwischen auf chinesische Open-Source-Modelle, anstatt auf die Angebote der großen amerikanischen Anbieter zurückzugreifen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.