Klings Video O1 kann Szenen, Subjekte und Kameraeinstellungen ändern – alles gleichzeitig
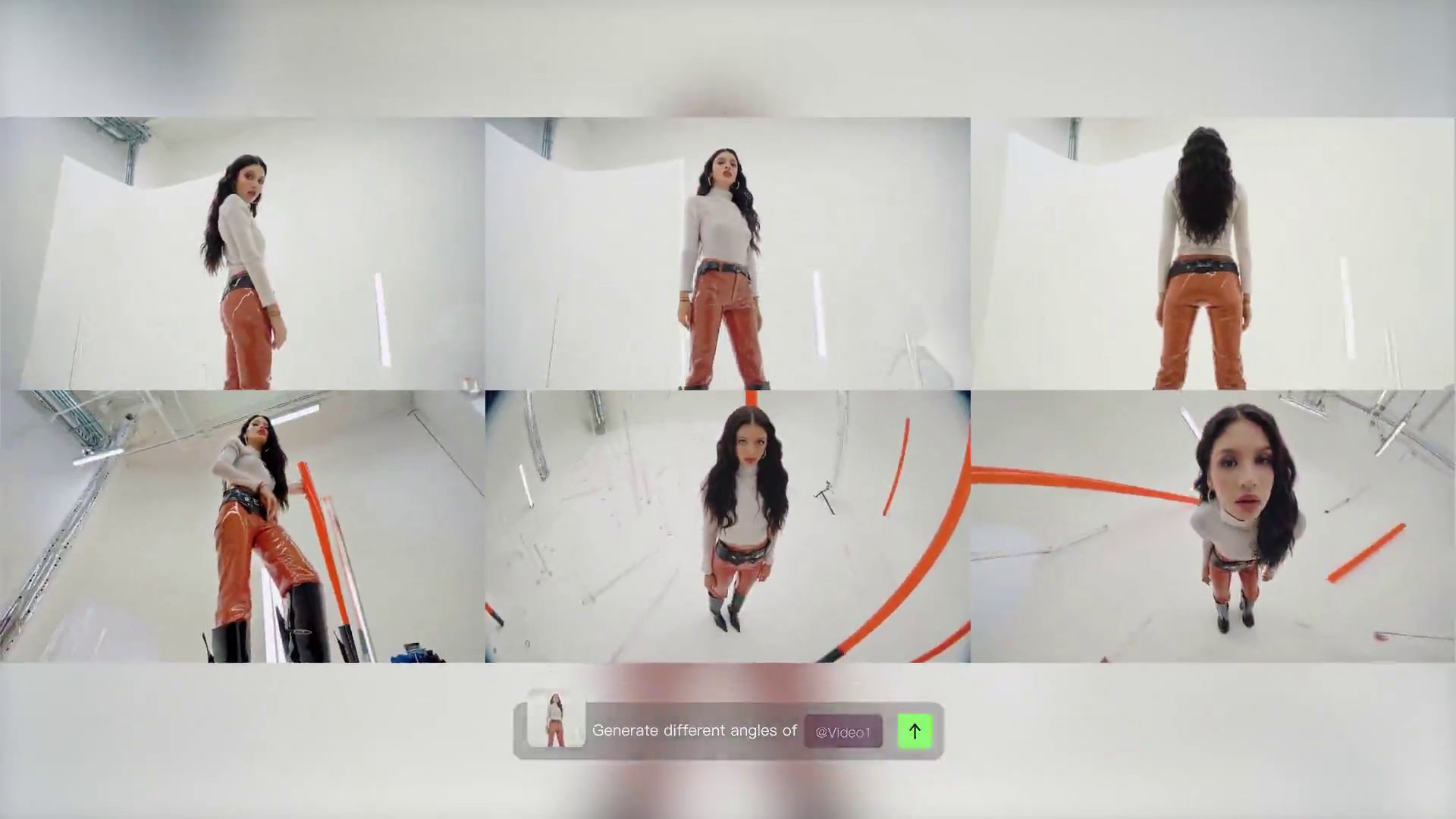
Das chinesische KI-Unternehmen Kuaishou hat das Modell "Video O1" vorgestellt. Laut dem Unternehmen hinter Kling AI handelt es sich um das "weltweit erste vereinheitlichte multimodale Videomodell", das verschiedene Aufgaben der Videogenerierung und -bearbeitung in einem einzigen System zusammenführt.
Video O1 integriert laut Kuaishou mehrere Aufgaben, die bisher separate Tools erforderten. Das Modell kann nicht nur aus Prompts oder Referenzbildern Videos mit einer Länge von drei bis zehn Sekunden generieren, sondern auch Bearbeitungen an Videos vornehmen, um etwa Protagonisten, Wetter, Videostil oder Farben zu verändern. Dabei kombiniert Video O1 mehrere Aufgaben in einem einzigen Prompt: Nutzer fügen etwa gleichzeitig ein Subjekt hinzu, modifizieren den Hintergrund und ändern den Stil.
Multimodale Verarbeitung von Bildern, Text und Videos
Das Modell verarbeitet auch verschiedene Eingabetypen gleichzeitig. Es interpretiert bis zu sieben Bilder, Videos, Subjekte und Text als Prompts. Nutzer können durch Textbefehle wie "Passanten entfernen" oder "Tageslicht zu Dämmerung ändern" Videos bearbeiten, ohne manuelle Maskierung oder Keyframes setzen zu müssen.
Nutzer laden Charaktere, Requisiten oder Szenen hoch, die das System dann in verschiedenen Kontexten einsetzt. Als Referenz können auch Aktionen oder Kamerabewegungen dienen. Das System versteht die Eingabedaten und hält die Subjekte, Personen oder Produkte Kling zufolge über verschiedene Aufnahmen hinweg konsistent.
Die Architektur von Video O1 basiert auf einem multimodalen Transformer, viel weiter geht das Unternehmen jedoch zur Technik nicht ins Detail. Kling führt eine sogenannte "Multimodale Visual Language" (MVL) ein, die als interaktives Medium zwischen Text und multimodalen Signalen dient. Das Modell nutzt Reasoning-Ketten und deduziert so Ereignisse. Diese Fähigkeiten ermöglichen eine intelligente Videogenerierung, die über einfache Musterrekonstruktion hinausgehe.
Vorsprung gegenüber Google und Runway
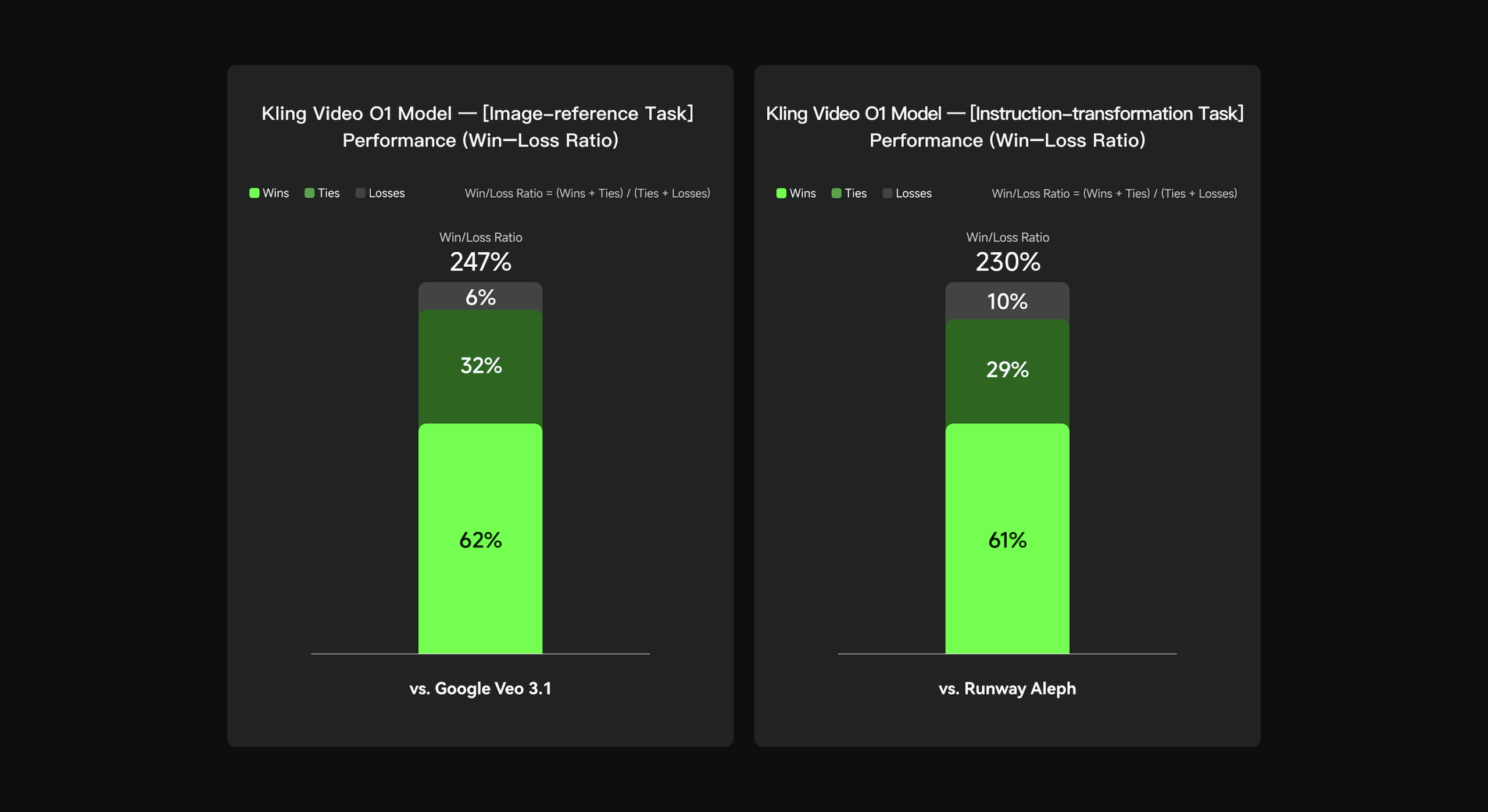
Kuaishou hat Video O1 intern gegen Google Veo 3.1 und Runway Aleph getestet. Bei der Aufgabe, Videos aus Bildreferenzen zu erstellen, schnitt Video O1 weitaus besser ab als Googles "Zutaten zu Video"-Feature. Bei Video-Transformationen, also dem Bearbeiten bestehender Videos, war O1 den Evaluatoren in 230 Prozent der Fälle lieber als Runway Aleph. Diese Zahlen stammen jedoch aus internen Tests von Kuaishou selbst und wurden bislang nicht extern verifiziert.
O1 steht ab sofort über die Weboberfläche von Kling zur Verfügung. Das chinesische Unternehmen mag mit O1 bei der Videobearbeitung und -generierung wieder einen kleinen Schritt nach vorn gemacht haben, der Markt ist jedoch hart umkämpft. Praktisch zeitgleich hat Runway mit Gen-4.5 sein neuestes und leistungsfähigstes Videomodell enthüllt. Neben westlichen Unternehmen wie Google, OpenAI und Midjourney konkurriert Kling mit einigen, primär auf Kosteneffizienz getrimmten Anwärtern aus der chinesischen Nachbarschaft wie Hailuo, Seedance oder Vidu.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.