Amazon re:Invent: Neuer KI-Chip, günstige Nova-2-Modelle und autonome Agenten

Amazon versucht auf der re:Invent 2025, technologisch Boden gutzumachen. Der Fokus liegt auf massiver Skalierung durch eigene Hardware, aggressiv bepreisten Modellen der Nova-2-Serie und dem Versuch, KI-Assistenten zu vollautonomen "Mitarbeitern" aufzuwerten.
Um die Abhängigkeit von Nvidia zu verringern und die Kosten für KI-Workloads zu senken, stellt Amazon Web Services (AWS) die dritte Generation seiner eigenen KI-Beschleuniger vor. Der Trainium3 UltraServer wird im 3-Nanometer-Verfahren gefertigt und soll im Vergleich zum Vorgänger die vierfache Geschwindigkeit und Speicherkapazität bieten, bei einer um 40 Prozent gesteigerten Energieeffizienz.
Die eigentliche Nachricht ist jedoch die Skalierung: AWS ermöglicht es nun, Cluster aus bis zu einer Million Trainium3-Chips zu bilden. Kunden wie Anthropic nutzen diese Infrastruktur bereits.
Gleichzeitig deutet Amazon einen Strategiewechsel für die kommende Generation an: Der bereits in Entwicklung befindliche Trainium4 soll Nvidias NVLink Fusion unterstützen. Damit öffnet sich AWS für hybride Systemarchitekturen, in denen die günstigere Amazon-Hardware direkt mit Nvidia-GPUs kommunizieren kann – ein pragmatisches Zugeständnis an die Marktdominanz des CUDA-Ökosystems.
Preiskampf mit Nova 2
Auf dieser Hardware-Basis rollt Amazon seine neue Modell-Familie aus: Nova 2 Lite und Nova 2 Pro. Der Konzern positioniert die Modelle wie die Vorgängergeneration primär über harte Preis-Leistungs-Daten gegen OpenAI und Google.
Eine Testreihe von Artificial Analysis bescheinigt dem Flaggschiff Nova 2.0 Pro (Preview) einen deutlichen Leistungssprung. Im hauseigenen Index legte das Modell um 30 Punkte zu und schließt damit zur Spitzengruppe auf - bleibt aber weiter hinter den Spitzenmodellen der Konkurrenz.
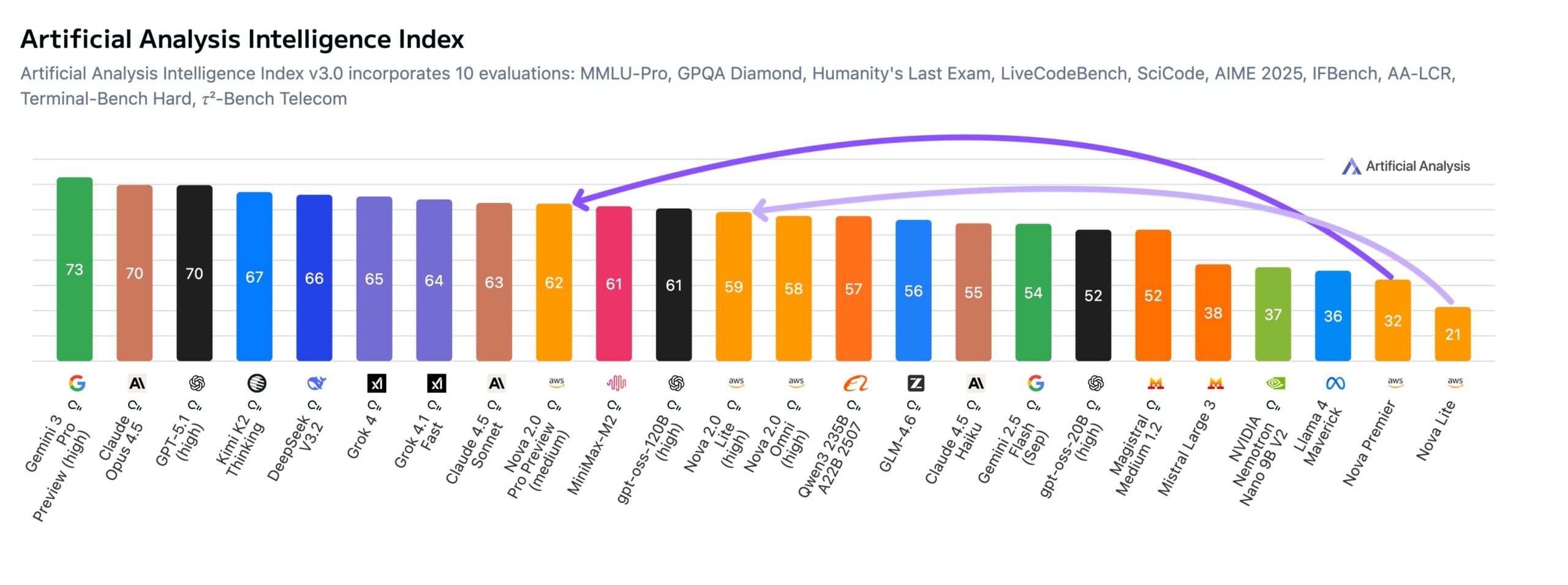
Aggressiv ist vor daher allem das Pricing: Mit 1,25 US-Dollar pro Million Input-Token und 10 US-Dollar für den Output unterbietet Nova 2.0 Pro die Konkurrenz deutlich. Ein Benchmark-Lauf im Index kostete laut Artificial Analysis mit dem Amazon-Modell rund 662 US-Dollar, während für Claude 4.5 Sonnet (817 US-Dollar) oder Google Gemini 3 Pro (1201 US-Dollar) deutlich mehr fällig wurde.
Neben den Standardmodellen und dem multimodalen Nova 2.0 Omni (Text, Bild, Video, Audio) führt Amazon Nova Forge ein. Das Tool ermöglicht Unternehmenskunden das sogenannte "Custom Pre-Training". Anders als beim reinen Fine-Tuning können Firmen hier eigene Daten bereits in die Trainingsphase des Modells einbringen. Reddit nutzte den Service, um ein Moderations-Modell zu erstellen, das laut CTO Chris Slowe die spezifischen Eigenheiten der Plattform besser versteht als generische Modelle.
Nova Sonic 2.0: Hohe Logik-Leistung bei Audio
Im Bereich der Sprachverarbeitung stellt Amazon das Speech-to-Speech-Modell Nova Sonic 2.0 vor. Laut Benchmarks von Artificial Analysis positioniert sich das Modell hinsichtlich der logischen Fähigkeiten ("Reasoning") zwischen den Marktführern.
Im "Big Bench Audio", einem Testdatensatz mit 1.000 komplexen Audio-Fragen, erreicht Nova Sonic 2.0 eine Genauigkeit von 87,1 Prozent. Damit belegt es Platz 2, hinter Googles Gemini 2.5 Flash Native Audio Thinking, aber noch vor OpenAIs GPT Realtime.
Bei der Latenz geht Amazon einen Kompromiss ein: Mit durchschnittlich 1,39 Sekunden bis zur ersten Audio-Antwort ist Nova Sonic zwar über zwei Sekunden schneller als das leistungsstärkere Google-Modell, liegt aber hinter den neuesten OpenAI-Modellen zurück. Das Modell unterstützt bidirektionales Audio-Streaming in fünf Sprachen (darunter Deutsch) und passt seine Sprechweise dynamisch an die Prosodie – also Betonung und Rhythmus – der Eingabe an.
Vom Assistenten zum autonomen Agenten
Auf der Anwendungsebene versucht AWS-CEO Matt Garman, das Narrativ vom KI-Chatbot hin zum autonomen Agenten zu verschieben. Laut Garman werden 80 bis 90 Prozent der künftigen KI-Wertschöpfung durch solche Agenten entstehen, die Aufgaben eigenständig abarbeiten, statt nur auf Prompts zu reagieren.
Dafür führt AWS drei spezialisierte "Frontier Agents" ein, die tief in die Entwickler-Workflows integriert werden sollen:
- Kiro soll als Entwickler-Agent Kontext über verschiedene Sitzungen und Repositories hinweg behalten. Laut AWS kann er Aufgaben wie Bug-Triage oder Code-Abdeckung autonom bearbeiten und Pull Requests vorbereiten. Das Ziel ist, den Entwickler von der Rolle des "KI-Aufsehers", der ständig Kontext liefern muss, zu entlasten.
- Der AWS Security Agent automatisiert Sicherheitsüberprüfungen und Penetrationstests.
- Der AWS DevOps Agent überwacht Infrastruktur-Metriken (via CloudWatch, Datadog etc.) und soll bei Ausfällen eigenständig Ursachenanalysen durchführen.
Amazon verspricht, dass diese Systeme nach einer Lernphase von drei bis sechs Monaten die spezifischen Muster eines Unternehmens adaptieren. Ob diese Autonomie in der Praxis tatsächlich die versprochene Entlastung bringt oder neue Komplexität in der Überwachung schafft, müssen Praxistests zeigen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.