Weniger ist mehr: Einzelne KI-Modelle können vernetzte KI-Agenten schlagen

Eine umfangreiche Studie von Google Research, Google Deepmind und MIT widerlegt die verbreitete Annahme, dass mehr KI-Agenten automatisch bessere Ergebnisse liefern. Die Forscher identifizieren präzise Bedingungen, unter denen Multi-Agenten-Systeme helfen oder schaden.
Die Idee klingt intuitiv: Wenn ein KI-Agent eine Aufgabe bewältigen kann, sollten mehrere spezialisierte Agenten, die zusammenarbeiten, noch besser abschneiden. "More agents is all you need" lautete entsprechend der Titel einer viel beachteten Studie aus dem vergangenen Jahr.
Doch eine neue Untersuchung von Forschern bei Google Research, Google Deepmind und dem MIT zeichnet ein differenzierteres Bild: Die Leistung von Multi-Agenten-Systemen schwankt zwischen 81 Prozent Verbesserung und 70 Prozent Verschlechterung, abhängig von der Aufgabenstruktur.
Die Forscher führten 180 kontrollierte Experimente durch, bei denen sie fünf verschiedene Architekturvarianten über drei große Sprachmodell-Familien (OpenAI GPT, Google Gemini, Anthropic Claude) und vier Benchmarks hinweg testeten. Um saubere Vergleiche zu ermöglichen, hielten sie Prompts, Werkzeuge und Token-Budgets konstant und variierten ausschließlich die Koordinationsstruktur und die Modellfähigkeit.
Parallelisierbare Aufgaben profitieren, sequenzielle Aufgaben leiden
Die Ergebnisse zeigen ein klares Muster: Bei Finanzanalyse-Aufgaben, die sich in unabhängige Teilprobleme zerlegen lassen, erreichte die zentralisierte Multi-Agenten-Koordination eine Verbesserung von 80,9 Prozent gegenüber einem einzelnen Agenten. Verschiedene Agenten konnten dabei parallel Umsatztrends, Kostenstrukturen und Marktvergleiche analysieren und ihre Ergebnisse anschließend zusammenführen.
Bei Planungsaufgaben in einer Minecraft-Umgebung hingegen verschlechterten sämtliche Multi-Agenten-Varianten die Leistung um 39 bis 70 Prozent. Der entscheidende Unterschied laut den Forschern: Jede Crafting-Aktion verändert den Inventarzustand, von dem nachfolgende Aktionen abhängen. Diese sequenziellen Abhängigkeiten lassen sich nicht sinnvoll auf mehrere Agenten verteilen.
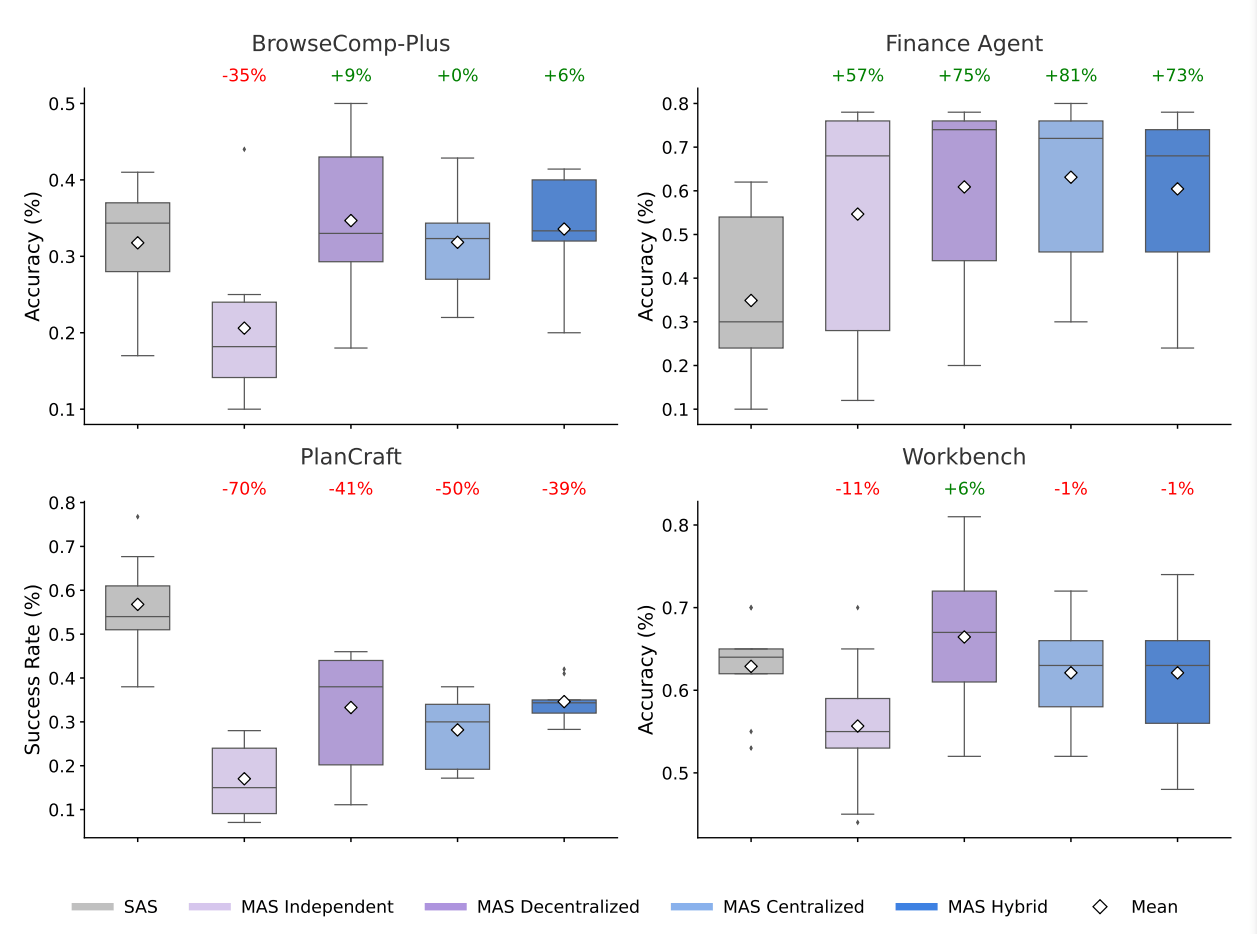
Diese Messung zeigt: Bei Aufgaben, bei denen jeder Schritt den Zustand verändert und spätere Schritte davon abhängen, haben alle getesteten Multi-Agenten-Varianten die Leistung verschlechtert. Hier ist ein Einzelagent im Vorteil, weil er einen durchgehenden Kontext behält und nichts zwischen Agenten komprimiert werden muss.
Drei Effekte bestimmen den Koordinationserfolg
Insbesondere bei Aufgaben mit vielen verschiedenen Werkzeugen (bspw. Websuche, Dateisuche, Code schreiben) leidet die Leistung überproportional unter dem Multi-Agenten-Overhead. Der Grund liegt laut den Forschern darin, dass Multi-Agenten-Systeme das verfügbare Token-Budget fragmentieren und den einzelnen Agenten zu wenig Kapazität für komplexe Werkzeugorchestrierung bleibt.
Der zweite Effekt betrifft die Fähigkeitssättigung: Sobald ein einzelner Agent bereits eine Erfolgsquote von etwa 45 Prozent erreicht, bringt zusätzliche Koordination abnehmende oder sogar negative Erträge. Die Koordinationskosten übersteigen dann das verbleibende Verbesserungspotenzial.
Drittens: Wenn mehrere Agenten ohne Austausch miteinander arbeiten, können ihre Fehler sich stark aufsummieren, bis zu 17-mal mehr als bei nur einem Agenten. Das passiert, weil niemand die Zwischenergebnisse der anderen prüft und Fehler so unbemerkt weitergegeben werden.
Wird hingegen ein zentraler Koordinator eingesetzt, der alle Ergebnisse sammelt und überprüft, bleiben die Fehler deutlich besser unter Kontrolle; sie steigen "nur" etwa um das 4-Fache.
Die 45-Prozent-Marke
Die wichtigste Faustregel: Wenn ein einzelner Agent bei einer Aufgabe schon mehr als 45 Prozent richtig macht, lohnt sich ein Multi-Agenten-System meistens nicht. Nur bei Aufgaben, die sich gut aufteilen lassen, können mehrere Agenten Vorteile bringen. Wenn sehr viele verschiedene Werkzeuge gebraucht werden (circa 16), ist es oft besser, einen einzelnen Agenten oder eine dezentrale Zusammenarbeit zu wählen.
Bei den Modell-Herstellern gab es leichte Unterschiede: OpenAI punktet bei hybriden Architekturen, Anthropic bei zentralisierten, und Google war am robustesten über alle Multi-Agenten-Architekturen hinweg.
Auch Kosten spielen eine Rolle
Die Forscher untersuchten zudem, wie viele Aufgaben gelöst werden, wenn man die gleiche Menge Rechenleistung (also Tokens) einsetzt. Ein einzelner Agent schafft dabei am meisten: Mit 1000 Tokens werden im Schnitt 67 Aufgaben erfolgreich erledigt.
Wenn mehrere Agenten zentral gesteuert zusammenarbeiten, sinkt der Wert auf 21 erfolgreiche Aufgaben, also nur noch ein Drittel. Besonders aufwendig sind die sogenannten hybriden Teams – dort werden mit 1000 Tokens nur noch 14 Aufgaben gelöst.
Ein Grund dafür: Je mehr Agenten beteiligt sind, desto öfter müssen sie sich absprechen und Informationen austauschen (Reasoning-Turns). Das kostet Zeit und Rechenleistung. Hybride Systeme benötigen dabei etwa sechsmal mehr solcher Austausch-Schritte als ein einzelner Agent. Deshalb empfehlen die Forscher, bei begrenztem Rechenbudget höchstens drei bis vier Agenten einzusetzen, sonst wird die Zusammenarbeit zu teuer und ineffizient.
Für Entwickler bedeutet das: Der Einzelagent sollte die Standardlösung sein, es sei denn, die Aufgabe lässt sich klar in unabhängige Teilprobleme zerlegen und der Einzelagent liegt noch deutlich unter der in der Studie ermittelten 45-Prozent-Erfolgszone.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.