Metas Pixio lernt durch Pixel-Rekonstruktion und übertrifft aufwendigere KI-Modelle

Forscher von Meta AI haben ein Bildmodell entwickelt, das allein durch Pixel-Rekonstruktion lernt. Pixio übertrifft aufwendigere Methoden bei Tiefenschätzung und 3D-Rekonstruktion, obwohl es weniger Parameter hat und einfacher trainiert wurde.
Eine etablierte Methode, um KI-Modellen das Verstehen von Bildern beizubringen, verdeckt Teile eines Bildes und lässt das Modell die fehlenden Bereiche rekonstruieren. Um das zu schaffen, muss es lernen, was auf Bildern typischerweise zu sehen ist: Formen, Farben, Objekte und wie diese räumlich zusammenhängen.
Dieser Ansatz, bekannt als Masked Autoencoder (MAE), galt zuletzt als unterlegen gegenüber komplexeren Methoden wie DINOv2 oder DINOv3. Ein Forschungsteam bei Meta AI zeigt nun in einer Studie, dass das nicht stimmen muss: Ihr verbessertes Modell Pixio übertrifft DINOv3 bei mehreren praktischen Aufgaben.
Modell lernt Reflexionen und 3D-Geometrie
Die Forscher zeigen anhand von Beispielen, welche Fähigkeiten Pixio durch die Pixel-Rekonstruktion entwickelt. Bei stark verdeckten Bildern rekonstruiert das Modell nicht nur Texturen, sondern erschließt auch die räumliche Anordnung der Szene. Es erkennt symmetrische Farbmuster und versteht Reflexionen, etwa wenn es eine gespiegelte Person in einem Fenster vorhersagt, obwohl dieser Bereich verdeckt war.

Diese Fähigkeiten entstehen, weil das Modell für eine genaue Rekonstruktion verstehen muss, was auf dem Bild zu sehen ist: Welche Objekte gibt es, wie ist der Raum aufgebaut, welche Muster wiederholen sich?
Drei Änderungen am Vorgängermodell
Pixio baut auf dem MAE-Framework auf, das Meta bereits 2021 vorstellte. Die Forscher identifizierten jedoch Schwachstellen im ursprünglichen Design und führten drei wesentliche Änderungen ein: Erstens verstärkten sie den Decoder, also den Teil des Modells, der die fehlenden Pixel rekonstruiert. Beim ursprünglichen MAE war dieser zu flach und damit zu schwach, sodass Encoder-Repräsentationen ihre Qualität für die Rekonstruktion opfern mussten.

Zweitens vergrößerten sie die verdeckten Bereiche: Statt einzelner kleiner Quadrate werden nun größere zusammenhängende Blöcke maskiert. So kann das Modell nicht einfach benachbarte Pixel kopieren, sondern muss das Bild tatsächlich "verstehen".
Drittens erweiterten sie das System um mehrere [CLS]-Token (class tokens) – spezielle Token, die am Anfang der Eingabe stehen und während des Trainings globale Eigenschaften aggregieren. Jeder dieser Token speichert Informationen wie Szenentyp, Kamerawinkel oder Beleuchtung, sodass das Modell vielseitigere Bildmerkmale lernen kann.
Bewusster Verzicht auf Benchmark-Optimierung
Für das Training sammelte das Team zwei Milliarden Bilder aus dem Web. Anders als bei DINOv2 und DINOv3 verzichteten die Forscher bewusst auf eine aufwendige Optimierung für bestimmte Testdatensätze.
DINOv3 etwa fügt Bilder aus dem bekannten ImageNet-Datensatz direkt in seine Trainingsdaten ein und verwendet sie bis zu 100-fach. Sie machen dadurch etwa zehn Prozent der gesamten Trainingsdaten aus. Das verbessert die Ergebnisse auf ImageNet-basierten Tests, könnte aber die Übertragbarkeit auf andere Aufgaben einschränken.
Pixio verwendet stattdessen eine einfachere Strategie: Bilder, die schwerer zu rekonstruieren sind, werden häufiger für das Training ausgewählt. Leicht vorhersagbare Produktfotos tauchen seltener auf, visuell komplexe Szenen häufiger.
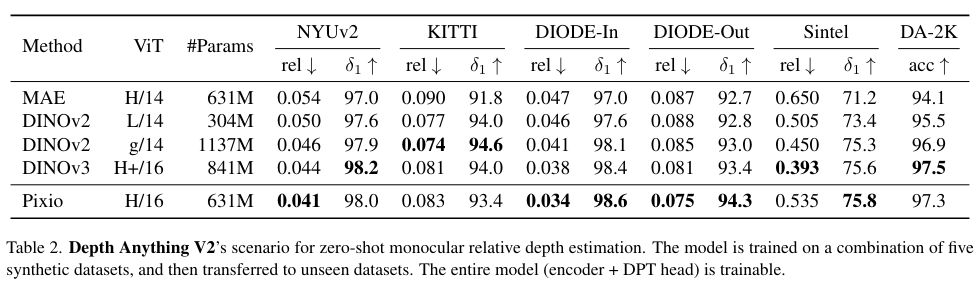
In den Benchmark-Tests schneidet Pixio mit 631 Millionen Parametern oftmals besser ab als DINOv3 mit 841 Millionen Parametern. Bei der monokularen Tiefenschätzung, also der Berechnung von Entfernungen aus einem einzelnen Foto, ist Pixio 16 Prozent genauer als DINOv3. Bei der 3D-Rekonstruktion aus Fotos übertrifft es DINOv3 ebenfalls, obwohl Letzteres mit acht verschiedenen Ansichten pro Szene trainiert wurde und Pixio nur mit Einzelbildern.
Auch beim Robotik-Lernen, bei dem Roboter aus Kamerabildern Handlungen ableiten sollen, liegt Pixmo vorn: 78,4 Prozent gegenüber 75,3 Prozent bei DINOv2.
Grenzen des Ansatzes
Die Trainingsmethode hat allerdings auch Grenzen. Das Verdecken von Bildteilen sei eine künstliche Aufgabe, denn in der echten Welt sehen wir vollständige Szenen, so die Forscher. Niedrige Verdeckungsraten machen die Aufgabe zu leicht, hohe Raten liefern zu wenig Kontext für eine sinnvolle Rekonstruktion.
Als mögliche Weiterentwicklung schlagen die Forscher Video-basiertes Training vor. Bei Videos könnte das Modell lernen, zukünftige Bilder aus vergangenen vorherzusagen – eine natürlichere Aufgabe, die ohne künstliche Verdeckung auskommt. Den Code haben die Forscher auf GitHub veröffentlicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.