Forscherteam will unlogische KI-Grübelei mit neuen "Laws of Reasoning" beenden
Kurz & Knapp
- Große Reasoning-Modelle zeigen oft unlogisches Verhalten: Sie investieren bei einfachen Aufgaben mehr Aufwand als bei schwierigen und liefern dabei schlechtere Ergebnisse.
- Forscher schlagen Regeln vor, nach denen der Denkaufwand proportional zur Schwierigkeit steigen und die Genauigkeit bei schwierigeren Aufgaben abnehmen sollte.
- Durch spezielles Training, das den Aufwand für kombinierte Aufgaben besser steuert, lässt sich die Genauigkeit in Benchmarks um bis zu 11,2 Prozentpunkte erhöhen.
Große Reasoning-Modelle schlussfolgern oft unlogisch: Sie grübeln bei einfachen Aufgaben länger als bei schwierigen und liefern dabei schlechtere Ergebnisse. Ein Forscherteam hat nun theoretische Gesetze formuliert, die beschreiben, wie KI-Modelle idealerweise "denken" sollten.
Reasoning-Modelle wie OpenAIs o1 oder Deepseek-R1 unterscheiden sich von herkömmlichen Sprachmodellen durch ihre Fähigkeit, vor einer Antwort einen internen "Denkprozess" zu durchlaufen. Dabei generiert das Modell eine Kette von Zwischenschritten – den sogenannten Reasoning Trace –, bevor es zur endgültigen Lösung gelangt. Bei der Frage "Was ist 17 × 24?" könnte ein solcher Trace etwa so aussehen:
Ich zerlege die Aufgabe in kleinere Schritte. 17 × 24 = 17 × (20 + 4) = 17 × 20 + 17 × 4. 17 × 20 = 340. 17 × 4 = 68. 340 + 68 = 408. Die Antwort ist 408.
Diese Technik verbessert die Leistung bei komplexen Aufgaben wie mathematischen Beweisen oder mehrstufigen Logikproblemen. Doch wie die aktuelle Forschung zeigt, arbeitet sie nicht immer effizient.
Mehr Rechenaufwand, schlechtere Ergebnisse
Wenn Deepseek-R1 eine Zahl quadrieren soll, generiert das Modell rund 300 Reasoning-Tokens mehr als bei einer zusammengesetzten Aufgabe, die sowohl Summieren als auch Quadrieren erfordert. Gleichzeitig sinkt die Genauigkeit bei der komplexeren Aufgabe um 12,5 Prozent. Dieses Verhalten dokumentiert ein Forscherteam verschiedener US-Universitäten in einer aktuellen Studie.
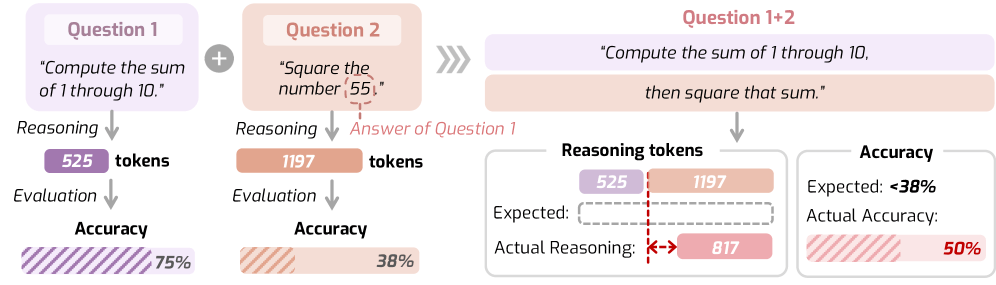
Das Beispiel könnte auf ein grundlegendes Problem aktueller Large Reasoning Models hindeuten: Ihr Denkverhalten folgt offenbar oft keiner erkennbaren Logik. Menschen passen ihren Denkaufwand typischerweise an die Schwierigkeit einer Aufgabe an. KI-Modelle scheinen das nicht zuverlässig zu tun und denken mal zu viel, mal zu wenig. Die Ursache liegt laut den Forschern in den Trainingsdaten, denn die Chain-of-Thought-Beispiele werden meist ohne explizite Regeln für die Denkzeit zusammengestellt.
Zwei Gesetze sollen optimales KI-Denken beschreiben
Das vorgeschlagene Framework "Laws of Reasoning" (LoRe) formuliert zwei zentrale Hypothesen. Das erste Gesetz besagt, dass der Denkaufwand proportional zur Aufgabenschwierigkeit steigen sollte. Doppelt so schwierige Aufgaben erfordern demnach doppelt so viel Rechenzeit. Das zweite Gesetz postuliert, dass die Genauigkeit mit steigender Schwierigkeit exponentiell abnehmen sollte.
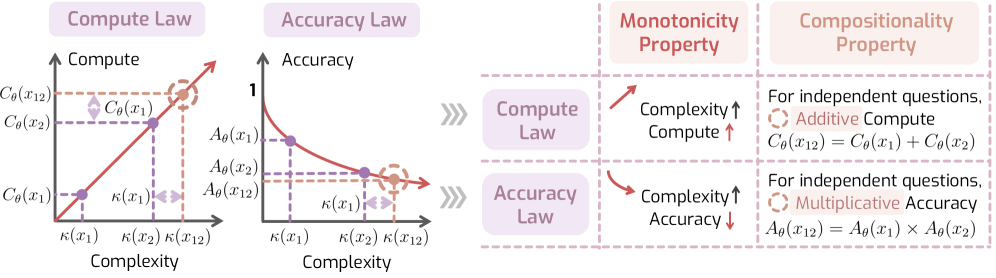
Da sich die tatsächliche Schwierigkeit einer Aufgabe praktisch nicht messen lässt, greifen die Forscher auf zwei überprüfbare Eigenschaften zurück. Die erste erscheint simpel, denn schwierigere Aufgaben sollten mehr Denkzeit erfordern als einfachere. Die zweite betrifft zusammengesetzte Aufgaben. Wenn ein Modell für Aufgabe A eine Minute braucht und für Aufgabe B zwei Minuten, sollte es für die Kombination beider etwa drei Minuten benötigen. Der Gesamtaufwand entspricht dann der Summe der Einzelaufwände.
Aktuelle Modelle scheitern offenbar bei zusammengesetzten Aufgaben
Für die Evaluation entwickelten die Forscher einen zweiteiligen Benchmark. Der erste Teil enthält 40 Aufgaben in den Bereichen Mathematik, Naturwissenschaften, Sprache und Code mit jeweils 30 Varianten steigender Schwierigkeit. Der zweite Teil kombiniert 250 Aufgabenpaare aus dem MATH500-Datensatz zu zusammengesetzten Fragen.
Die Tests an zehn Large Reasoning Models zeigen ein gemischtes Bild. Bei der ersten Eigenschaft schneiden die meisten Modelle gut ab und wenden für schwierigere Aufgaben tatsächlich mehr Denkzeit auf. Eine Ausnahme bildet das kleinste getestete Modell Deepseek-R1-Distill-Qwen-1.5B, das im Sprachbereich sogar eine negative Korrelation aufweist. Es denkt bei einfacheren Aufgaben offenbar länger nach.
Bei zusammengesetzten Aufgaben versagen laut der Studie jedoch alle getesteten Modelle. Die Abweichungen zwischen erwartetem und tatsächlichem Denkaufwand seien erheblich. Selbst Modelle mit speziellen Mechanismen zur Steuerung der Reasoning-Länge wie Thinkless-1.5B oder AdaptThink-7B schnitten demnach nicht besser ab.
Gezieltes Training soll Denkverhalten verbessern
Die Forscher entwickelten einen Finetuning-Ansatz, der das additive Verhalten bei zusammengesetzten Aufgaben gezielt fördern soll. Die Methode nutzt Dreiergruppen aus zwei Teilaufgaben und deren Kombination. Aus mehreren generierten Lösungen wird jene Kombination ausgewählt, bei der der Denkaufwand für die Gesamtaufgabe am besten der Summe der Einzelaufwände entspricht.
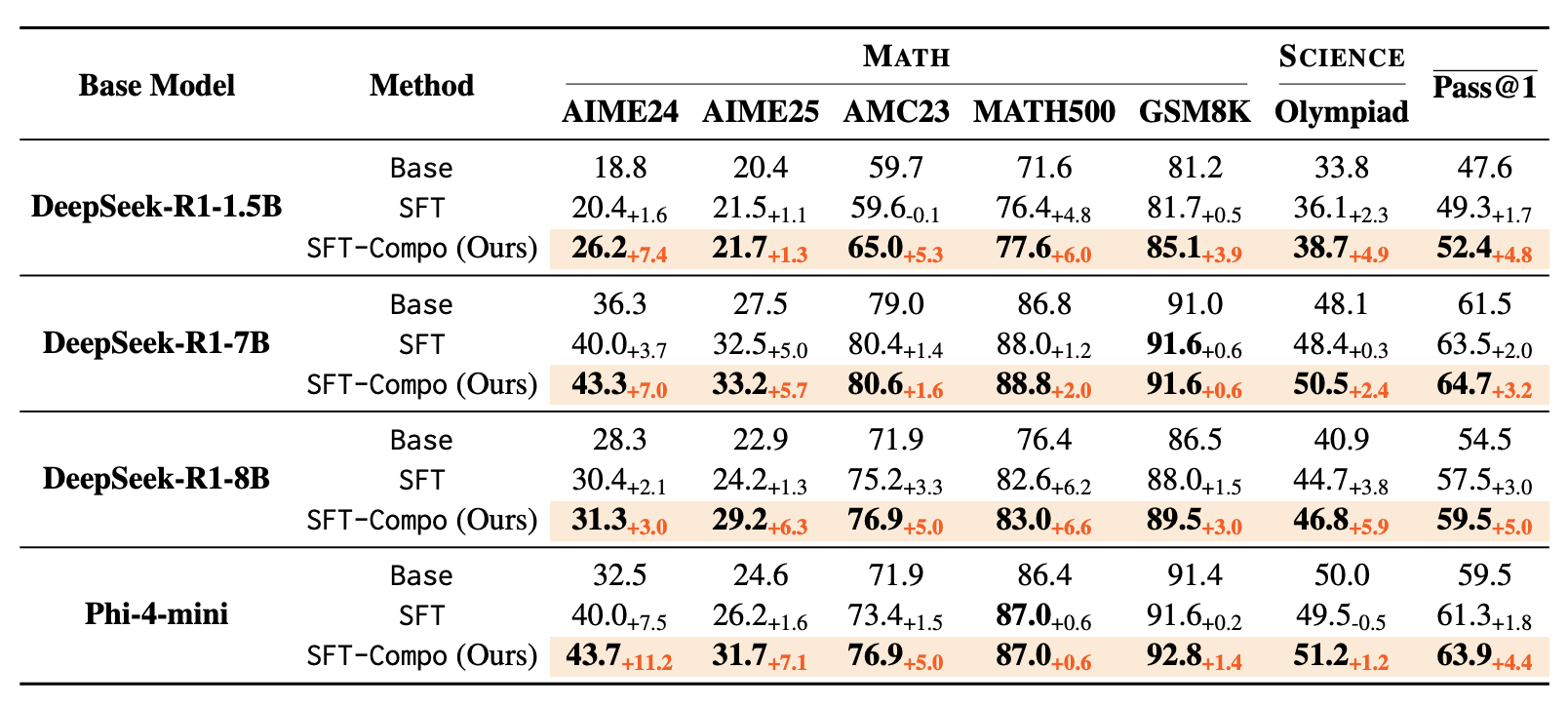
Die Ergebnisse sind nach Angaben der Forscher eindeutig. Bei einem 1.5B-Modell sinke die Abweichung beim Denkaufwand um 40,5 Prozent. Die Reasoning-Fähigkeiten verbesserten sich auf allen sechs getesteten Benchmarks. Das 8B-Modell erreiche eine durchschnittliche Verbesserung von fünf Prozentpunkten bei der Genauigkeit.
Ein überraschendes Ergebnis seien die beobachteten Wechselwirkungen. Das Training auf additive Denkzeiten verbessere auch andere Eigenschaften, die nicht direkt trainiert wurden. Die Forscher räumen Einschränkungen ein, denn der Benchmark enthält nur 40 Ausgangsaufgaben. Zudem wurden aus Kostengründen keine proprietären Modelle getestet. Der Code und die Benchmarks sind öffentlich verfügbar.
"Reasoning" als nächster Skalierungshorizont für KI-Modelle
2025 hat die Entwicklung von Reasoning-Modellen die LLM-Landschaft maßgeblich geprägt, angefangen mit der Veröffentlichung von Deepseek R1 als Modell, das konkurrenzfähige Leistung bei weniger Ressourcenaufwand im Training lieferte, bis hin zur Etablierung von Hybrid-Modellen wie Claude 4.5 Sonnet, die ein flexibles Thinking-Budget festlegen lassen.
Gleichzeitig haben Studien immer wieder gezeigt, dass Reasoning zwar zu besseren Ergebnissen führt, es jedoch nicht mit menschlichen Denkfähigkeiten verwechselt werden darf. Zudem werden wohl nur innerhalb des antrainierten Wissens vorhandene Lösungsansätze effizienter gefunden. Das Modell kann sich keinen Weg zu grundlegend neuen Ideen "erdenken", wie es womöglich ein Mensch könnte.
Auch die neuesten Science-Benchmarks von OpenAI und anderen Institutionen unterstützen diese These: Hier schneiden die Modelle bei bestehenden Frage-Antwort-Tests ausgezeichnet ab, nicht jedoch bei komplexen zusammenhängenden Forschungsaufgaben, die innovative Lösungsansätze erfordern.
Die KI-Branche setzt allerdings darauf, dass Reasoning-Modelle durch massiv gesteigerte Rechenleistung weiter verbessert werden können. OpenAI hat beispielsweise für o3 zehnmal so viel Reasoning Compute genutzt wie beim Vorgänger o1 – und das nur vier Monate nach dessen Veröffentlichung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren