Trotz unterschiedlicher Datenbasis: KI-Systeme konvergieren zu universellen Darstellungen
Forscher am MIT haben 59 wissenschaftliche KI-Modelle verglichen und festgestellt, dass diese trotz unterschiedlicher Architekturen und Trainingsaufgaben zu ähnlichen internen Darstellungen von Molekülen, Materialien und Proteinen konvergieren.
Wissenschaftliche KI-Modelle arbeiten mit ganz unterschiedlichen Eingaben: Manche bekommen Moleküle als codierte Zeichenketten, andere verarbeiten 3D-Atomkoordinaten, wieder andere Proteinsequenzen. Doch obwohl sie auf völlig verschiedenen Daten trainiert wurden, scheinen sie intern etwas Ähnliches zu lernen. Das zeigt eine neue Studie von Forschern am Massachusetts Institute of Technology.
Das Team um Sathya Edamadaka und Soojung Yang hat 59 verschiedene Modelle untersucht, darunter spezialisierte Systeme für Moleküle, Materialien und Proteine, aber auch große Sprachmodelle wie DeepSeek und Qwen. Die Forscher extrahierten die internen Repräsentationen jedes Modells und verglichen sie mit mehreren Metriken.
Bessere Modelle konvergieren stärker
Das Ergebnis: Die gelernten Darstellungen sind über Eingabeformate hinweg signifikant ausgerichtet. Modelle für 3D-Koordinaten etwa stimmen untereinander stark überein, ebenso textbasierte Modelle. Überraschend ist, dass auch zwischen diesen Gruppen deutliche Ähnlichkeiten bestehen.
Je besser ein Modell bei seiner Trainingsaufgabe abschneidet, desto mehr nähert sich seine Repräsentation der des besten Modells an. Laut den Forschern deutet dies darauf hin, dass leistungsstarke Modelle eine gemeinsame Darstellung physikalischer Realität lernen. Auch die Komplexität der internen Darstellungen fällt bei allen Modellen in einen ähnlich engen Bereich, was auf eine universelle Struktur hindeutet.
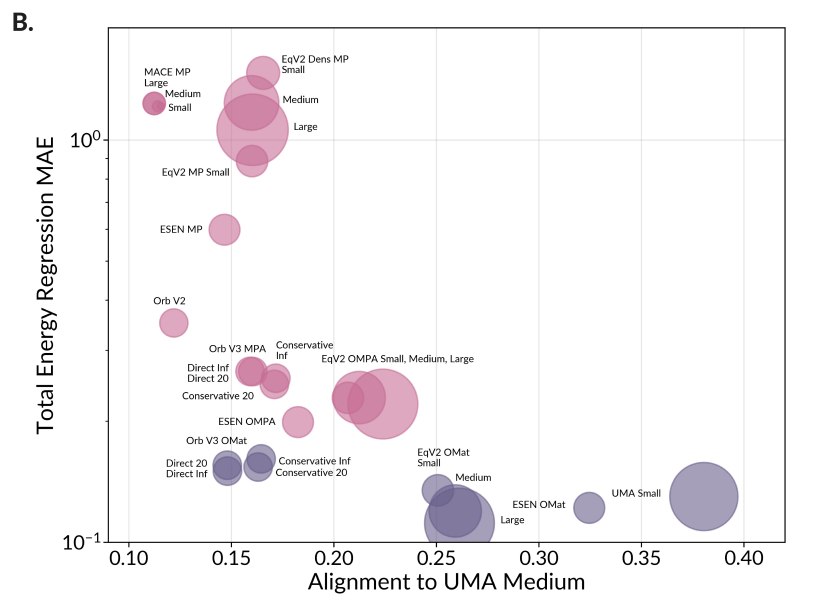
Grenzen bei unbekannten Strukturen
Die Analyse offenbart jedoch auch Grenzen. Bei bekannten Strukturen, die den Trainingsdaten ähneln, liefern gute Modelle übereinstimmende Darstellungen, während schwächere Modelle jeweils eigene, weniger übertragbare Lösungen finden. Bei völlig neuen Strukturen, die stark von den Trainingsdaten abweichen, versagen hingegen fast alle Modelle: Ihre Darstellungen werden oberflächlich und verlieren wichtige chemische Informationen.
Aktuelle Materialmodelle haben demnach noch keinen foundationalen Status erreicht, da ihre Repräsentationen zu stark von limitierten Trainingsdaten geprägt sind. Für echte Generalität seien deutlich diversere Datensätze erforderlich. Die Forscher schlagen Repräsentationsausrichtung als neuen Benchmark vor: Ein Modell erreicht foundationalen Status nur, wenn es sowohl hohe Leistung zeigt als auch stark mit anderen leistungsfähigen Modellen ausgerichtet ist.
Diese fehlende Generalisierung außerhalb der Trainingsdaten ist ein bekanntes Grundproblem aktueller KI-Modelle. Forschungsergebnisse zeigen, dass etwa Transformer-Architekturen bei Kompositionsaufgaben, also dem Kombinieren bekannter Fakten zu neuen abgeleiteten Fakten, systematisch an der Generalisierung außerhalb der Trainingsdaten (Out-of-Distribution, OOD) scheitern.
Schon im Mai 2024 zeigte eine Studie desselben Instituts, dass unterschiedliche KI-Modelle bei wachsender Leistung zu gemeinsamen Darstellungen konvergieren. Die Forscher nannten dies "platonische Repräsentation" in Anlehnung an Platons Höhlengleichnis. Die neue Studie überträgt dieses Konzept erstmals auf wissenschaftliche Modelle und liefert Evidenz dafür, dass auch spezialisierte KI-Systeme für Chemie und Biologie zu einer universellen Repräsentation von Materie konvergieren könnten.
Der gerade erst veröffentlichte SDE-Benchmark für wissenschaftliche Forschung zeigt noch eine andere Form der Konvergenz: Die Modelle konvergieren bei den schwierigsten Fragen häufig auf dieselben falschen Antworten. Auch hier waren es die besten Modelle, die die größte Übereinstimmung zeigten. Das zeigte zuvor schon eine andere Studie, hier im Kontext einer Aufsicht von KI-Prozessen durch eine andere KI. Die Ähnlichkeit in den Beurteilungen würde hier zu blinden Flecken und neuen Ausfallmodi führen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.