"Der Fluch des Wissens": KI-Modelle verstehen nicht, woran Menschen scheitern

Große Sprachmodelle lösen Prüfungsfragen oft besser als Menschen, können aber nicht einschätzen, wie schwer diese Aufgaben für Lernende sind. Eine umfangreiche Studie deckt eine systematische Kluft zwischen maschineller und menschlicher Wahrnehmung auf.
Ein Forschungsteam verschiedener US-Universitäten hat untersucht, ob LLMs die Schwierigkeit von Prüfungsfragen aus menschlicher Perspektive einschätzen können. Dafür testeten die Forscher über 20 Sprachmodelle, darunter GPT-5, GPT-4o, verschiedene Llama- und Qwen-Varianten sowie spezialisierte Reasoning-Modelle wie Deepseek-R1.
Die Modelle sollten abschätzen, wie schwer Prüfungsfragen für Menschen sind. Als Vergleich dienten Schwierigkeitswerte aus realen Feldtests mit Studierenden in vier Bereichen: USMLE (Medizin), Cambridge (Englisch) sowie SAT Reading/Writing und SAT Math.
Das Ergebnis: Die KI-Einschätzungen stimmen nur schwach mit der menschlichen Wahrnehmung überein. Um das zu messen, nutzen die Forscher die sogenannte Spearman-Korrelation – eine statistische Kennzahl, die angibt, wie ähnlich Mensch und Maschine Fragen von "leicht" bis "schwer" einordnen. Ein Wert von 1 bedeutet perfekte Übereinstimmung, 0 zeigt keinen Zusammenhang. Im Durchschnitt erreichen die Modelle jedoch nur Werte unter 0,50. Neuere oder größere Modelle schneiden nicht automatisch besser ab. GPT-5 kommt nur auf 0,34, während das ältere GPT-4.1 mit 0,44 deutlich besser abschneidet.
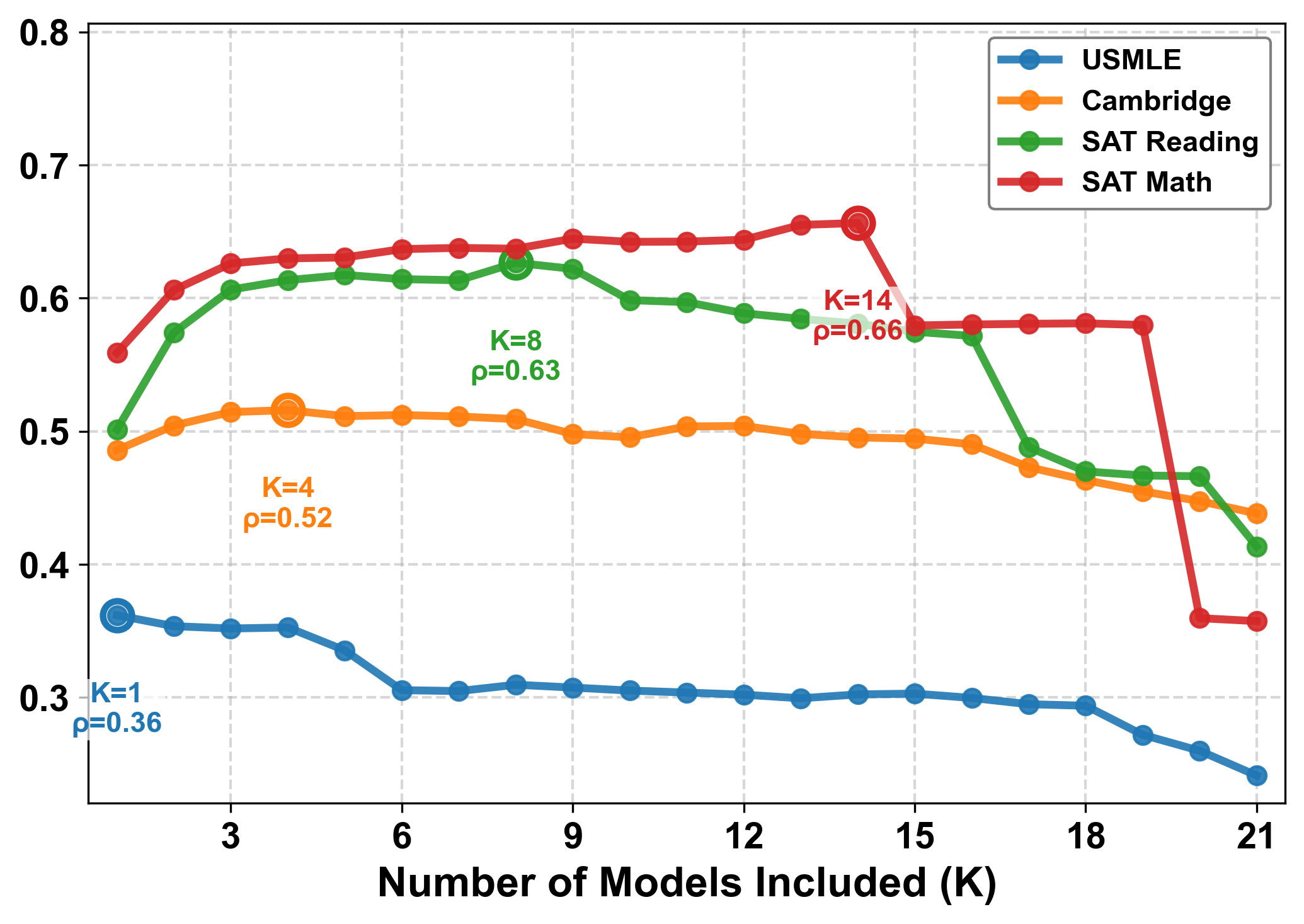
Wer alles weiß, versteht nicht, was andere nicht wissen
Die Forscher nennen das zentrale Problem den „Fluch des Wissens": Die Modelle sind schlicht zu gut, um die Schwierigkeiten schwächerer Lernender nachzuempfinden. Was für Medizinstudierende eine harte Nuss ist, lösen sie mühelos – und können deshalb nicht einschätzen, wo Menschen straucheln.
Die Zahlen bestätigen das. Bei den Fragen aus dem US-Medizin-Staatsexamen löste die große Mehrheit der Modelle genau jene Aufgaben problemlos, an denen menschliche Prüflinge am häufigsten scheiterten.
Die Forscher prüften außerdem, ob sich die Modelle durch entsprechende Anweisungen glaubhaft als schwache, durchschnittliche oder starke Studierende verhalten können. Beim tatsächlichen Beantworten der Fragen änderte sich kaum etwas: Die Genauigkeit verschob sich typischerweise um weniger als einen Prozentpunkt. Die Modelle können ihre eigene Fähigkeit offenbar nicht zuverlässig herunterregeln. Sie finden oft trotzdem die richtige Lösung und können die typischen Fehler schwächerer Lernender nicht authentisch nachbilden.
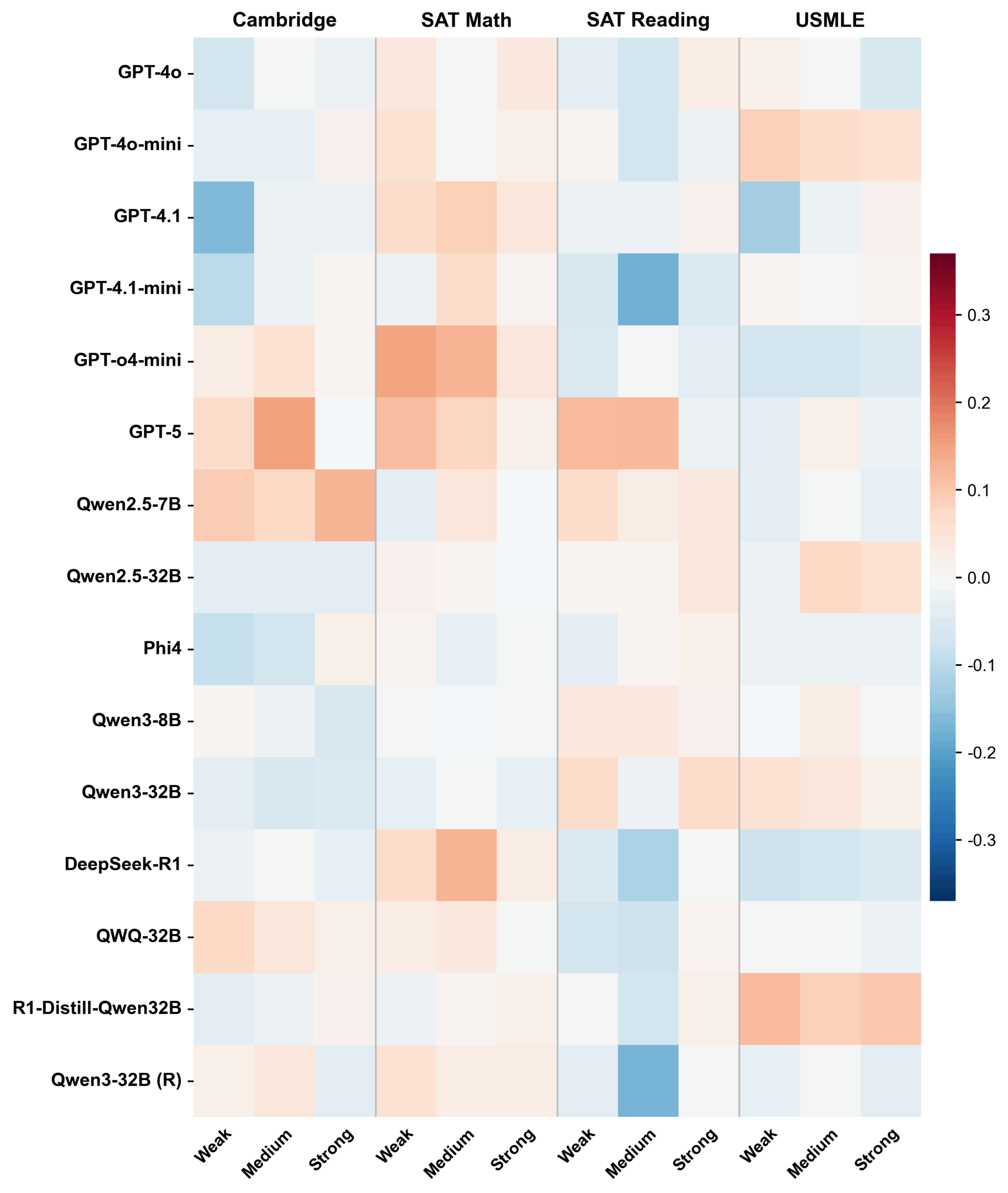
Modelle bilden einen eigenen Konsens, der an Menschen vorbeigeht
Statt sich an die menschliche Wahrnehmung anzunähern, entwickeln die Modelle laut der Studie eine gemeinsame maschinelle Einschätzung. Die verschiedenen Sprachmodelle stimmen untereinander stärker überein als mit den menschlichen Daten – ein „Machine Consensus", der systematisch von der Realität abweicht.
Dabei unterschätzen die Modelle die Schwierigkeit durchgehend. Ihre Vorhersagen ballen sich in einem engen niedrigen Bereich zusammen, während die tatsächlichen Schwierigkeitswerte breiter gestreut sind. Für die Modelle erscheinen fast alle Fragen relativ einfach – weil sie für sie auch einfach sind, so die Forscher.
Auch vorherige Studien zeigen, dass KI-Modelle zur Konsensbildung neigen; das gilt für richtige wie auch für falsche Antworten.
Selbst die eigenen Grenzen bleiben unsichtbar
Ein weiterer Befund betrifft die fehlende Selbstwahrnehmung. Die Forscher untersuchten, ob die Schwierigkeitsvorhersagen der Modelle zumindest mit ihren eigenen Fehlern zusammenhängen: Wenn ein Modell eine Frage als schwierig einschätzt, sollte es diese auch häufiger falsch beantworten.
Die Ergebnisse zeigen jedoch, dass die Vorhersagen nur knapp über dem Zufallsniveau liegen. Selbst GPT-5 kann nicht zuverlässig vorhersagen, bei welchen Aufgaben es selbst versagen wird. Die expliziten Schwierigkeitsschätzungen sind von der tatsächlichen Leistung entkoppelt. Den Modellen fehle die Selbstreflexion, um ihre eigenen Grenzen zu erkennen, argumentieren die Autoren.
Implikationen für Bildungstechnologie
Die genaue Einschätzung von Aufgabenschwierigkeit gilt als Grundlage für Bildungsbewertungen. Sie ist entscheidend für Lehrplangestaltung, automatische Testerstellung und adaptive Lernsysteme. Bisher erfordert dies aufwendige Feldtests mit echten Studierenden. Die Hoffnung war, dass Sprachmodelle diese Einschätzung automatisieren könnten.
Die Studie dämpft diese Erwartung. Die Fähigkeit, Probleme zu lösen, bedeute nicht, menschliche Lernschwierigkeiten zu verstehen. Für den Einsatz in der Bildungstechnologie seien neue Ansätze erforderlich, die über reines Prompting hinausgehen. Möglicherweise müssten Modelle gezielt auf Daten von Studierendenfehlern trainiert werden, um die Kluft zwischen maschinellem Können und menschlichem Lernen zu überbrücken.
Die Debatte über KI im Bildungsbereich wird derzeit von verschiedenen Seiten geführt. Vor kurzem forderte der ehemalige OpenAI-Forscher Andrej Karpathy eine radikale Transformation des Bildungssystems. Schulen sollten davon ausgehen, dass jegliche Arbeit außerhalb des Klassenzimmers mit KI-Unterstützung erstellt wurde, da KI-Detektoren nicht zuverlässig funktionierten. Karpathy plädierte für ein „Flipped Classroom"-Modell: Prüfungen finden in der Schule statt, Wissensaneignung mit KI-Hilfe zu Hause. Sein Ziel sei eine doppelte Kompetenz: Schüler sollten den Umgang mit KI beherrschen, aber auch ohne sie existieren können.
Dass KI im Bildungsbereich eine wachsende Rolle spielt, zeigen auch Nutzungsdaten von OpenAI. In einer Rangliste der beliebtesten Anwendungsgebiete stand „Schreiben und Lektorat" auf Platz eins, gefolgt von „Nachhilfe und Unterricht".
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.