ByteDance gibt KI-Videomodellen ein Gedächtnis für längere Geschichten

Kurz & Knapp
- Forscher von ByteDance und der Nanyang Technological University haben mit StoryMem ein System entwickelt, das KI-generierte Videos über mehrere Szenen hinweg konsistent hält.
- Das System speichert Schlüsselbilder in einer Memory-Bank und nutzt sie dann als Referenz für neue Szenen.
- In Tests schneidet StoryMem 28,7 Prozent besser ab als das Basismodell und 9,4 Prozent besser als der bisherige Stand der Technik.
Ein Team von ByteDance und der Nanyang Technological University hat ein System entwickelt, das KI-generierte Videos über mehrere Szenen hinweg konsistent hält. Der Ansatz speichert Schlüsselbilder aus bereits generierten Szenen und nutzt sie als Referenz für neue.
Aktuelle KI-Videomodelle wie Sora, Kling oder Veo liefern bei einzelnen Clips von wenigen Sekunden Länge mittlerweile beeindruckende Ergebnisse. Sollen jedoch mehrere Szenen zu einer zusammenhängenden Geschichte verbunden werden, zeigt sich ein grundlegendes Problem. Charaktere verändern ihr Aussehen von Szene zu Szene, Umgebungen wirken inkonsistent, visuelle Details wandern.
Bisherige Lösungsversuche stoßen laut den Forschern auf ein Dilemma. Wer alle Szenen gemeinsam in einem Modell verarbeitet, kämpft mit explodierenden Rechenkosten. Wer jede Szene einzeln generiert und anschließend zusammenfügt, verliert die Konsistenz zwischen den Abschnitten.
Das nun vorgestellte System StoryMem wählt einen dritten Weg. Es speichert während der Generierung ausgewählte Schlüsselbilder in einer Memory-Bank und greift bei jeder neuen Szene auf diese zurück. Dadurch soll das Modell wissen, wie ein Charakter oder eine Umgebung in vorherigen Szenen aussah.

Gezielte Auswahl statt Vollspeicherung
Die Forscher setzen dabei nicht auf eine vollständige Speicherung aller generierten Frames. Stattdessen wählt ein Algorithmus gezielt Bilder aus, die visuell bedeutsam sind. Die Auswahl erfolgt über eine Analyse der Bildinhalte, die semantisch unterschiedliche Frames identifiziert. Ein zweiter Filter prüft die technische Qualität und sortiert unscharfe oder verrauschte Bilder aus.
Die Memory-Bank arbeitet mit einem hybriden System. Frühe Schlüsselbilder bleiben als langfristige Referenz erhalten, während neuere Bilder in einem gleitenden Fenster rotieren. So bleibt die Speichergröße begrenzt, ohne dass wichtige visuelle Informationen aus dem Anfang der Geschichte verloren gehen.
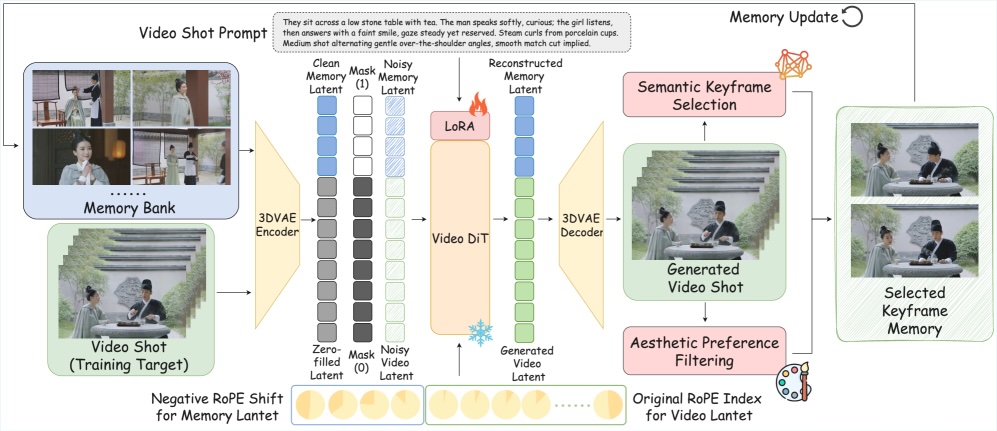
Bei der Generierung einer neuen Szene werden die gespeicherten Bilder zusammen mit dem aktuell entstehenden Video in das Modell eingespeist. Eine spezielle Positionskodierung namens RoPE (Rotary Position Embedding) sorgt dafür, dass das Modell die Memory-Frames als zeitlich vorausgehende Ereignisse interpretiert. Die Forscher weisen den gespeicherten Bildern dabei negative Zeitindizes zu, sodass sie vom Modell als Vergangenheit behandelt werden.
Training auf kurzen Clips genügt
Ein praktischer Vorteil des Ansatzes liegt im Trainingsaufwand. Konkurrierende Methoden erfordern aufwendiges Training auf langen, zusammenhängenden Videosequenzen, die in hoher Qualität kaum verfügbar sind. StoryMem kommt mit einer LoRA-Anpassung (Low-Rank Adaptation) des bestehenden Open-Source-Modells Wan2.2-I2V von Alibaba aus.
Das Team trainierte auf 400.000 kurzen Einzelclips von jeweils fünf Sekunden Länge. Die Clips wurden nach visueller Ähnlichkeit gruppiert, sodass das Modell lernte, aus verwandten Bildern konsistente Fortsetzungen zu generieren. Die Erweiterung fügt dem 14-Milliarden-Parameter-Modell lediglich etwa 0,7 Milliarden zusätzliche Parameter hinzu.

Deutliche Verbesserungen in Tests
Zur Evaluation entwickelten die Forscher einen eigenen Benchmark namens ST-Bench. Er umfasst 30 Geschichten mit insgesamt 300 detaillierten Szenenanweisungen und deckt verschiedene Stile ab, von realistischen Szenarien bis zu Märchen.
Die Ergebnisse zeigen laut der Studie deutliche Verbesserungen bei der Konsistenz zwischen Szenen. StoryMem schneidet 28,7 Prozent besser ab als das unveränderte Basismodell und 9,4 Prozent besser als HoloCine, das die Forscher als bisherigen "State of the Art" bezeichnen. Gleichzeitig erreicht StoryMem den höchsten Ästhetik-Score unter allen getesteten Methoden, die auf Konsistenz optimiert sind.
Eine Nutzerstudie bestätigt die quantitativen Ergebnisse. Hier haben die Probanden die Ergebnisse von StoryMem in den meisten Bewertungsdimensionen gegenüber allen Baselines bevorzugt.
| Method | Aesthetic Quality↑ | Prompt Following↑ | Cross-shot-Consistency↑ | ||
|---|---|---|---|---|---|
| Global | Single-shot | Overall | Top-10-Pairs | ||
| Wan2.2-T2V | 0,6452 | 0,2174 | 0,2452 | 0,3937 | 0,4248 |
| StoryDiffusion + Wan2.2-I2V | 0,6085 | 0,2288 | 0,2349 | 0,4600 | 0,4732 |
| IC-LoRA + Wan2.2-I2V | 0,5704 | 0,2131 | 0,2181 | 0,4110 | 0,4296 |
| HoloCine | 0,5653 | 0,2199 | 0,2125 | 0,4628 | 0,5005 |
| Ours | 0,6133 | 0,2289 | 0,2313 | 0,5065 | 0,5337 |
Das Framework ermöglicht zwei zusätzliche Anwendungsfälle. Nutzer können eigene Referenzbilder als Startpunkt der Memory-Bank einspeisen, etwa Fotos von Personen oder Orten. Das System generiert dann eine Geschichte, in der diese Elemente durchgehend auftauchen. Zudem lassen sich natürlichere Übergänge zwischen Szenen erzielen. Wenn kein harter Schnitt gewünscht ist, verwendet das System den letzten Frame einer Szene als ersten Frame der nächsten.
Grenzen bei komplexen Szenen
Die Forscher benennen einige Einschränkungen. Bei Szenen mit vielen verschiedenen Charakteren stößt das System an Grenzen. Die Memory-Bank speichert Bilder ohne Zuordnung zu einzelnen Figuren. Wenn in einer Szene ein neuer Charakter auftaucht, kann es passieren, dass das Modell visuelle Eigenschaften falsch zuordnet.
Als Abhilfe empfehlen die Forscher, Charaktere in jedem Prompt explizit zu beschreiben. Außerdem können Übergänge zwischen Szenen mit stark unterschiedlichen Bewegungsgeschwindigkeiten unnatürlich wirken, da die Frame-Verbindung keine Geschwindigkeitsinformation überträgt.
Die Projektseite mit weiteren Beispielen ist bereits verfügbar. ST-Bench soll als Benchmark für weitere Forschung veröffentlicht werden. Die Gewichte haben die Forscher auf Hugging Face veröffentlicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren