Gegen KI-Schummelei: NYU-Professor ersetzt schriftliche Tests durch mündliche KI-Prüfungen

Panos Ipeirotis, Professor an der NYU Stern School of Business, hat mündliche Prüfungen mit einem KI-Sprachagenten durchgeführt. Das Experiment kostete 15 Dollar für 36 Studierende und offenbarte neben studentischen Wissenslücken auch Schwächen im eigenen Unterricht.
Die schriftlichen Vorbereitungsaufgaben im neuen Kurs "AI/ML Product Management" sahen verdächtig gut aus – nicht "starker Student" gut, sondern eher "McKinsey-Memo nach drei Überarbeitungsrunden" gut, schreibt Panos Ipeirotis in seinem Blog. Der NYU-Professor ist bekannt für seine Arbeit zu Crowdsourcing und zur Integration von menschlicher und maschineller Intelligenz.
Die Reaktion der Dozenten: Sie riefen ihre Studierenden zufällig im Unterricht auf. Das Ergebnis war laut Ipeirotis "erhellend": Viele, die durchdachte Arbeiten eingereicht hatten, konnten grundlegende Entscheidungen in ihrer eigenen Abgabe nach zwei Nachfragen nicht erklären. Die Diskrepanz zwischen schriftlicher Leistung und mündlicher Verteidigung war zu konsistent, um sie auf Nervosität zu schieben.
Das alte Gleichgewicht, bei dem Take-Home-Arbeiten zuverlässig Verständnis messen konnten, sei dank KI "tot", so Ipeirotis. Studierende könnten die meisten traditionellen Prüfungsfragen jetzt mit KI beantworten.
42 Cent pro mündliche Prüfung
Mündliche Prüfungen hingegen erzwingen Echtzeitdenken und Verteidigung tatsächlicher Entscheidungen, seien aber ein logistischer Albtraum für große Klassen. Inspiriert von Forschung, die zeigt, dass KI bei Bewerbungsgesprächen konsistenter als Menschen agieren kann, wagten Ipeirotis und sein Co-Dozent Konstantinos Rizakos ein Experiment: Die Abschlussprüfung wurde von einem Voice-AI-Agenten auf Basis von ElevenLabs Conversational AI durchgeführt.
Die Prüfung bestand aus zwei Teilen: Zunächst fragte der Agent nach dem Abschlussprojekt des Studenten – Ziele, Daten, Modellierungsentscheidungen, Evaluationen, Fehlermodi. Im zweiten Teil wählte der Agent einen der im Kurs besprochenen Cases und stellte Fragen zu den behandelten Themen.
36 Studierende wurden über neun Tage geprüft, durchschnittlich 25 Minuten pro Prüfung. Die Gesamtkosten: 15 Dollar, davon 8 Dollar für Claude als Hauptbewerter, 2 Dollar für Gemini, 30 Cent für OpenAI und etwa 5 Dollar für ElevenLabs. Das entspricht 42 Cent pro Student.
Zum Vergleich: 36 Studierende mal 25 Minuten mal zwei menschliche Bewerter ergeben 30 Stunden Arbeitszeit. Bei studentischen Hilfskraft-Sätzen von etwa 25 Dollar pro Stunde wären das 750 US-Dollar, rechnet der Professor vor. Aus diesen finanziellen Gründen würde man mündliche Prüfungen in diesem Ausmaß nicht vornehmen.
Einschüchternde Stimme und umständliche Fragen
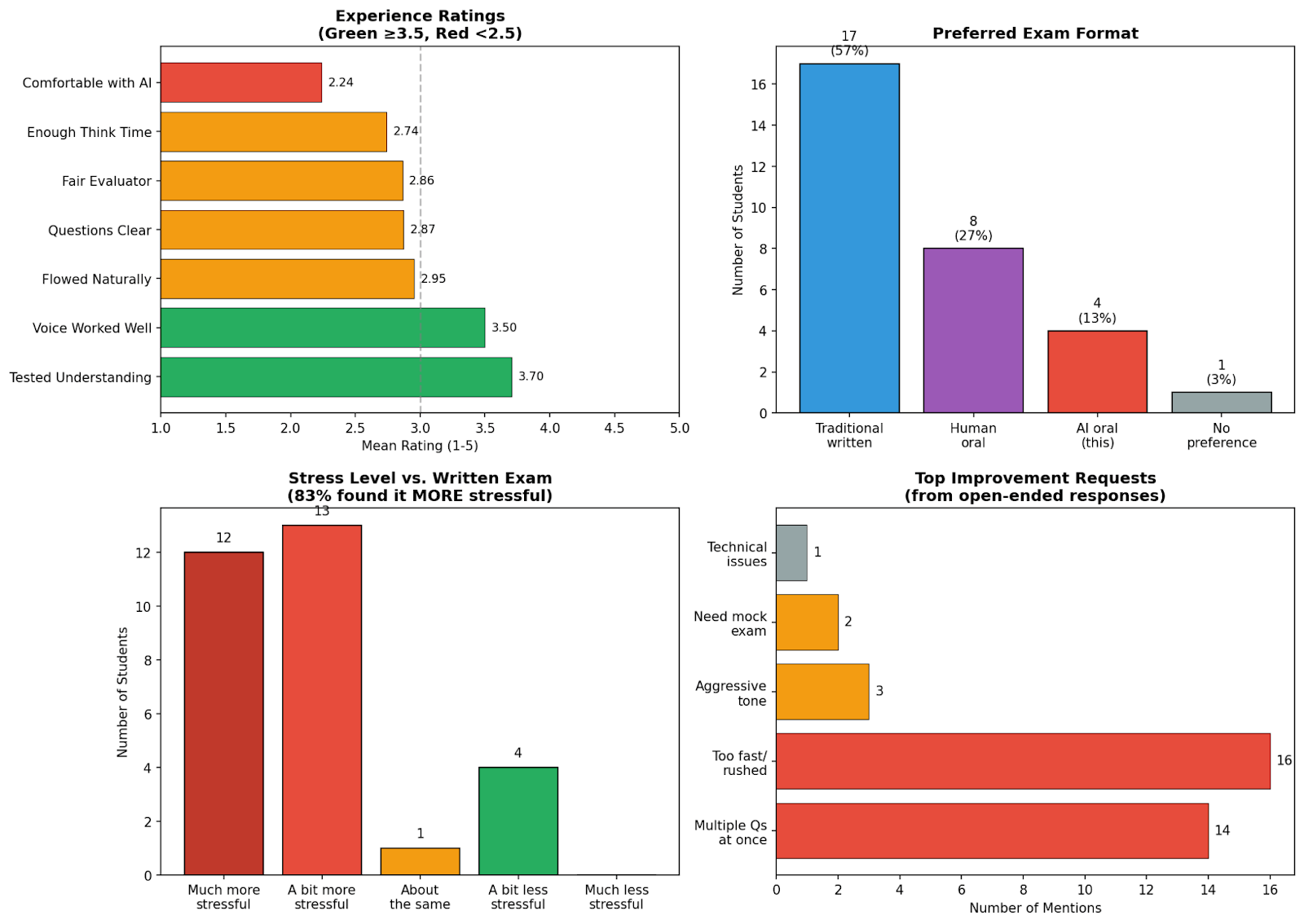
Die erste Version hatte laut Ipeirotis Probleme. Einige Studierende beschwerten sich über den strengen Ton des Agenten. Die Professoren hatten die Stimme eines Kollegen geklont, aber die Studierenden empfanden sie als "intensiv" und "herablassend". Ein Student schrieb per E-Mail, der Agent habe ihn "angeschrien".
Weitere Schwierigkeiten: Der Agent stellte mehrere Fragen auf einmal, paraphrasierte bei Wiederholungsbitten statt wörtlich zu wiederholen und füllte Denkpausen zu schnell.
Besonders problematisch war die Randomisierung: Als der Agent "zufällig" einen Case auswählen sollte, wählte er den Fall "Zillow" in 88 Prozent der Fälle. Nach dessen Entfernung aus dem Prompt landete er am nächsten Tag bei 16 von 21 Prüfungen auf dem Thema "Predictive Policing".
"Einen LLM zu bitten, 'zufällig auszuwählen', ist wie einen Menschen zu bitten, 'eine Zahl zwischen 1 und 10 zu nennen' - man bekommt viele 7er", so Ipeirotis. Er beschreibt hier ein gut dokumentiertes Phänomen, das letztlich auf menschlichem Bias in den Trainingsdaten beruht.
Drei KI-Modelle bewerten im Gremium
Die Bewertung erfolgte nach dem "Council of LLMs"-Ansatz von Andrej Karpathy. Drei Modelle, Claude, Gemini und ChatGPT, bewerteten jedes Transkript zunächst unabhängig, sahen dann die Bewertungen der anderen und revidierten ihre Einschätzung.
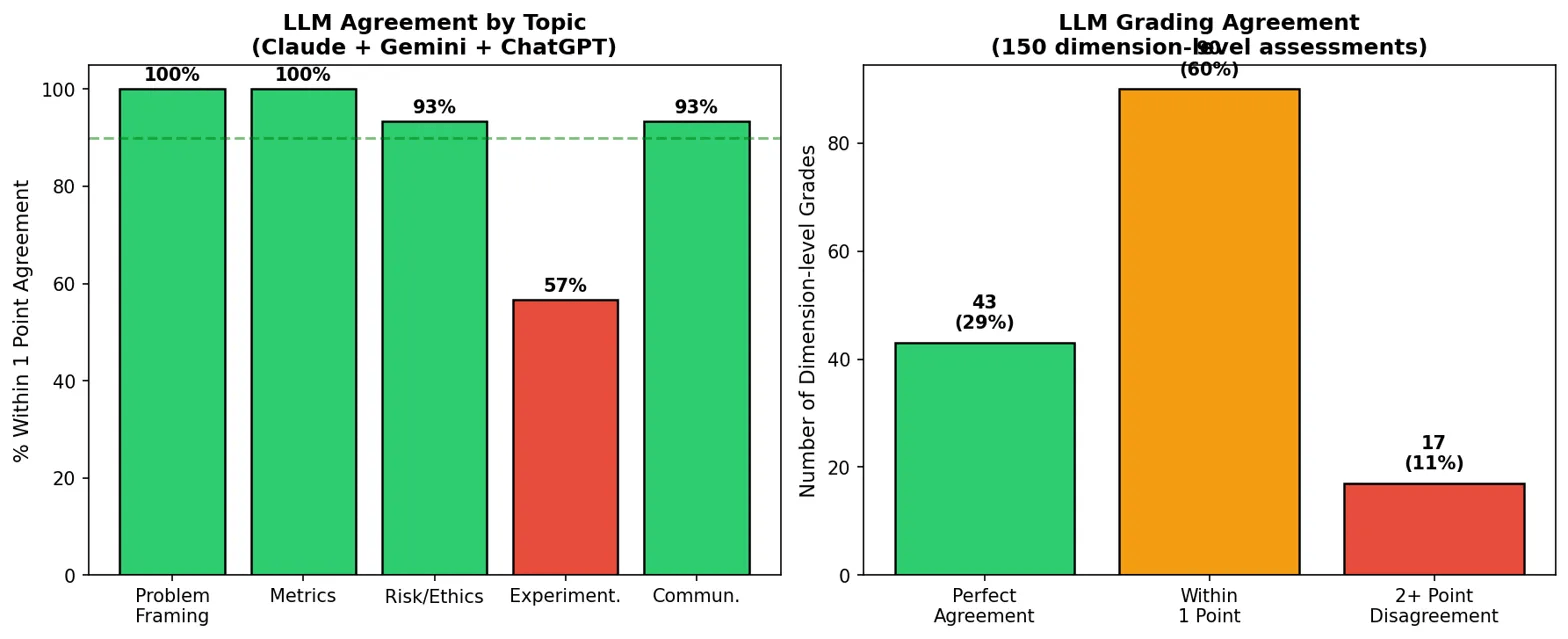
In der ersten Runde war die Übereinstimmung schlecht: Gemini vergab im Schnitt 17 von 20 Punkten, Claude nur 13,4. Nach der zusätzlichen, in den Prozess integrierten LLM-Konsultation lagen laut Grafik (siehe unten) 60 Prozent der Bewertungen innerhalb eines Punktes; 29 Prozent stimmten perfekt überein. Gemini senkte seine Noten um durchschnittlich zwei Punkte, nachdem es Claudes und OpenAIs Kritik an spezifischen Lücken gesehen hatte.
Das generierte Feedback übertraf laut Ipeirotis menschliche Bewerter: strukturierte Zusammenfassungen von Stärken und Schwächen mit wörtlichen Zitaten aus dem Prüfungsgespräch.
Die KI diagnostiziert Lehrlücken
Die thematische Analyse offenbarte auch eine unangenehme Wahrheit für die Dozenten selbst. Im Bereich "Experimentation" erreichten Studierende nur 1,94 von 4 Punkten im Schnitt, bei "Problem Framing" dagegen 3,39. Drei Studierende konnten das Thema überhaupt nicht diskutieren, keiner erreichte die volle Punktzahl.
Die A/B-Testing-Methodik sei im Kurs zu kurz gekommen, räumt Ipeirotis ein. "Der externe Bewerter machte es unmöglich, das zu ignorieren." Die Bewertungsausgabe wurde so zum Spiegel der eigenen Schwächen als Dozent. Ein weiterer Befund: Die Prüfungsdauer korrelierte nicht mit der Note. Die kürzeste Prüfung von neun Minuten führte zur höchsten Note, die längste von 64 Minuten zu einer mittelmäßigen Bewertung.
Stressiger, aber fairer
Eine Umfrage unter den Studierenden zeigte gemischte Reaktionen: Nur 13 Prozent bevorzugten das KI-Format, doppelt so viele eine mündliche Prüfung mit einem Menschen. 83 Prozent empfanden die KI-Prüfung als stressiger als schriftliche Prüfungen. Aber 70 Prozent stimmten zu, dass sie ihr tatsächliches Verständnis testete: der höchstbewertete Punkt in der Umfrage.
Mündliche Prüfungen waren Standard, bis sie nicht mehr skalierten, resümiert Ipeirotis. KI mache sie wieder praktikabel. Ein Vorteil gegenüber klassischen Prüfungen: Das Set-up kann Studierenden zum Üben gegeben werden, da die Fragen jedes Mal neu generiert werden. Durchgesickerte Prüfungsfragen sind kein Problem mehr.
Ipeirotis hat die Prompts für den Voice-Agenten und das Bewertungsgremium sowie einen Link zum Ausprobieren des Agenten veröffentlicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.