KI-Modelle sollen lernen, ihre eigenen Schwächen zu erkennen und zu beheben

- Chinesische Wissenschaftler haben mit UniCorn ein Framework entwickelt, das multimodalen KI-Modellen beibringen soll, ihre eigenen Schwächen zu erkennen und zu beheben.
Einige multimodale Modelle können mittlerweile Bilder verstehen und generieren, doch zwischen beiden Fähigkeiten klafft oft eine erstaunliche Lücke. Ein Modell erkennt etwa korrekt, dass auf einem Bild der Strand links und die Wellen rechts zu sehen sind - generiert aber selbst ein Bild mit entsprechendem Prompt mit vertauschter Anordnung.
Dieses Phänomen bezeichnen Forscher der University of Science and Technology of China (USTC) und weiterer chinesischer Universitäten in ihrer Studie als "Conduction Aphasia" - in Anlehnung an eine neurologische Störung, bei der Patienten Sprache verstehen, aber nicht korrekt wiedergeben können. Mit UniCorn haben sie nun ein Framework entwickelt, das diese Diskrepanz überbrücken soll.
KI-Modell spielt drei Rollen gleichzeitig
Der Kerngedanke von UniCorn ist simpel: Wenn ein Modell Bilder besser bewerten kann, als es sie generiert, sollte dieses Bewertungsvermögen die Generierung verbessern können. Die Forscher teilen dafür ein einzelnes multimodales Modell in drei kollaborierende Rollen auf, die innerhalb desselben Parameterraums agieren.
Der "Proposer" generiert zunächst diverse und herausfordernde Textbeschreibungen. Der "Solver" erstellt daraufhin mehrere Bildkandidaten zu jedem Prompt - konkret acht verschiedene Varianten mit unterschiedlichen Parametern. Anschließend bewertet der "Judge" die generierten Bilder auf einer Skala von 0 bis 10 und liefert eine detaillierte Begründung.
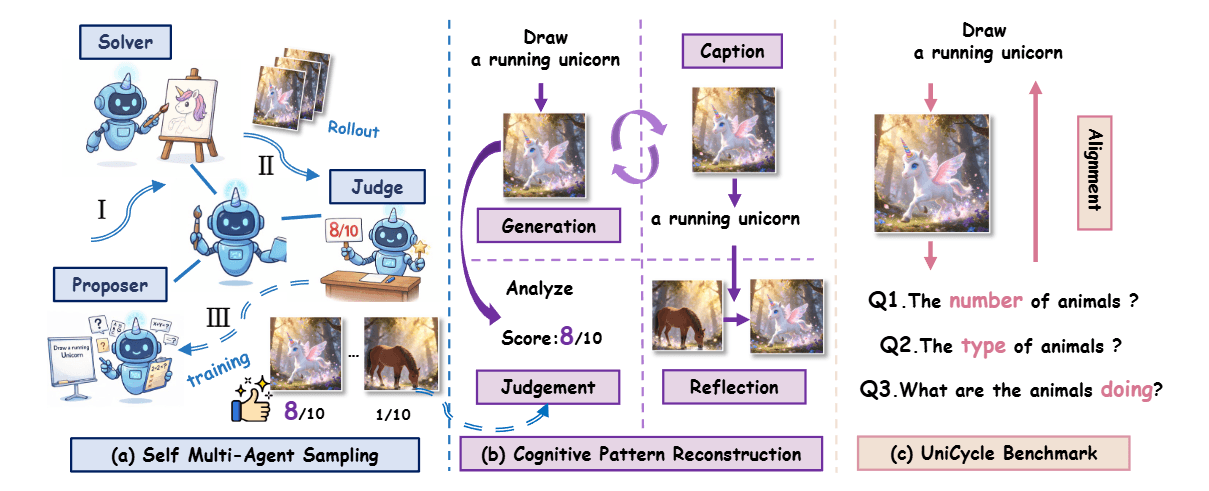
In der zweiten Phase findet das eigentliche Training statt. Die gesammelten Interaktionen werden in vier verschiedene Trainingsformate umgewandelt: Das Modell lernt, aus Prompts gute Bilder zu generieren, aber auch umgekehrt, seine eigenen Bilder zu beschreiben. Zusätzlich trainiert es darauf, Bild-Text-Paare zu bewerten und schlechte Ergebnisse in bessere zu verwandeln. Die Forscher betonen, dass alle drei Komponenten notwendig sind. Trainiert man nur mit Generierungsdaten, kollabieren die Verständnisfähigkeiten des Modells.
Das Fine-Tuning dauert laut den Forschern etwa sieben Stunden auf acht Nvidia H800 GPUs - vergleichsweise wenig für die erzielten Verbesserungen. Der gesamte Prozess kommt ohne externe Datensätze oder stärkere Lehrer-Modelle aus.
Neuer Benchmark prüft Zykluskonsistenz
Um zu messen, ob die Verbesserungen echte multimodale Intelligenz widerspiegeln oder nur aufgabenspezifische Optimierungen darstellen, haben die Forscher den UniCycle-Benchmark entwickelt. Dieser testet, ob ein Modell Schlüsselinformationen aus seinen eigenen generierten Bildern rekonstruieren kann.
Der Ablauf folgt einer Text-zu-Bild-zu-Text-Schleife: Das Modell generiert zunächst ein Bild aus einer Textbeschreibung und beantwortet dann Fragen zu diesem Bild. Ein externes Modell prüft anschliessend, ob die Antworten mit der ursprünglichen Beschreibung übereinstimmen. So kann festgestellt werden, ob das Modell wirklich versteht, was es generiert hat.
Deutliche Verbesserungen bei komplexen Aufgaben
In den Experimenten verwendeten die Forscher BAGEL als Basismodell und testeten UniCorn auf sechs verschiedenen Benchmarks. Die Ergebnisse zeigen durchgehend Verbesserungen gegenüber dem Basismodell. Ein Nano Banana Pro entsteht so freilich nicht, aber der deutliche Leistungssprung zeigt, dass die Methode funktioniert.
Besonders stark fallen die Gewinne bei Aufgaben aus, die strukturiertes Verständnis erfordern. Beim Zählen von Objekten und bei räumlichen 3D-Anordnungen verbessert sich das Modell deutlich. Auch bei wissensintensiven Aufgaben, die etwa kulturelles oder naturwissenschaftliches Hintergrundwissen erfordern, zeigt UniCorn klare Fortschritte.
Auf dem DPG-Benchmark, der die Fähigkeit zur Generierung komplexer Szenen mit mehreren Objekten und deren Attributen testet, übertrifft UniCorn sogar GPT-4o. Beim neuen UniCycle-Benchmark schneidet das Framework fast zehn Punkte besser ab als das Basismodell - laut dem Team ein Zeichen dafür, dass die Verbesserungen nicht nur oberflächlich sind, sondern tatsächlich die Kohärenz zwischen Verständnis und Generierung stärken.

Externes Lehrer-Modell bringt kaum Vorteile
Die Forscher testeten auch, ob ein stärkeres externes Modell als Judge bessere Ergebnisse liefert. Dafür setzten sie Qwen3-VL-235B ein, ein deutlich größeres Modell. Das Ergebnis überrascht: Die Leistung verbesserte sich kaum, auf dem UniCycle-Benchmark sank sie sogar.
Die Forscher vermuten, dass das Modell Schwierigkeiten hat, die komplexeren Bewertungsmuster eines stärkeren Lehrers zu übernehmen. Self-Play mit dem eigenen Modell ist zumindest in diesem Experiment effektiver als externe Supervision.
Schwächen bei Negation und Zählen bleiben bestehen
Die Forscher räumen ein, dass UniCorn bei bestimmten Aufgaben an Grenzen stößt. Besonders bei Negationen - also Anweisungen wie "ein Bett ohne Katze" - und beim präzisen Zählen von Objekten zeigt das Framework keine signifikanten Verbesserungen. Diese Aufgabentypen seien für multimodale Modelle grundsätzlich schwierig, und das Self-Play-Paradigma könne hier keine effektive Supervision liefern.
Zudem durchläuft das Modell den Verbesserungsprozess nur einmal: Es sammelt Daten, trainiert darauf - und das war es. Ein iteratives Vorgehen, bei dem das verbesserte Modell erneut Daten sammelt und sich weiter optimiert, haben die Forscher noch nicht umgesetzt. Sie planen dies für zukünftige Arbeiten, um Verständnis und Generierung gemeinsam weiterzuentwickeln.
Eine weitere Einschränkung betrifft die Verständnisfähigkeiten: Während die Bildgenerierung deutlich besser wird, bleiben die Scores bei reinen Verständnis-Benchmarks weitgehend stabil. UniCorn verbessert also primär die eine Seite der Medaille. Allerdings - und das betonen die Forscher als wichtigen Erfolg - kollabieren die Verständnisfähigkeiten auch nicht, was bei reinem Generierungstraining ohne die zusätzlichen Datenformate der Fall wäre.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.