X-Coder übertrifft deutlich größere KI-Modelle dank rein synthetischer Trainingsdaten
Forscher der Tsinghua University und Microsoft haben ein Verfahren entwickelt, um KI-Modelle für anspruchsvolles Programmieren ausschließlich mit generierten Daten zu trainieren. Ihr 7-Milliarden-Parameter-Modell X-Coder übertrifft auf dem LiveCodeBench-Benchmark doppelt so große Konkurrenten.
Die Experimente der Forschergruppe belegen einen klaren Zusammenhang zwischen Datenmenge und Benchmark-Ergebnissen: Mit 32.000 synthetischen Programmieraufgaben erreicht das Modell eine Pass-Rate von 43,7 Prozent. Bei 64.000 Aufgaben steigt der Wert auf 51,3 Prozent, bei 128.000 auf 57,2 Prozent und bei 192.000 schließlich auf 62,7 Prozent.
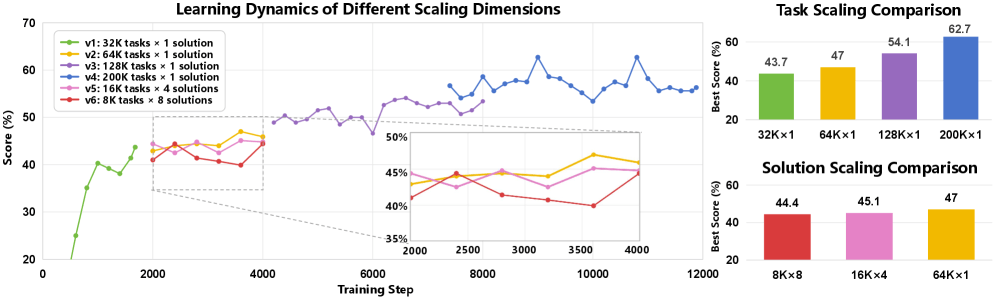
Bei gleichem Rechenbudget erweist sich die Vielfalt der Aufgaben als wichtiger als die Anzahl der Lösungen pro Aufgabe. Ein Datensatz mit 64.000 verschiedenen Aufgaben und jeweils einer Lösung schneidet besser ab als einer mit 16.000 Aufgaben und je vier Lösungen oder 8.000 Aufgaben mit je acht Lösungen.
Aufgaben entstehen aus kombinierten Bausteinen
Die Entwicklung leistungsfähiger Code-Modelle scheitert oft an begrenzten Trainingsdaten. Bestehende Sammlungen von Wettbewerbsaufgaben werden häufig wiederverwendet und reichen nicht aus, um weitere Verbesserungen zu erzielen. Bisherige synthetische Ansätze schreiben vorhandene Aufgaben lediglich um und bleiben dadurch in ihrer Vielfalt an die ursprünglichen Vorlagen gebunden.
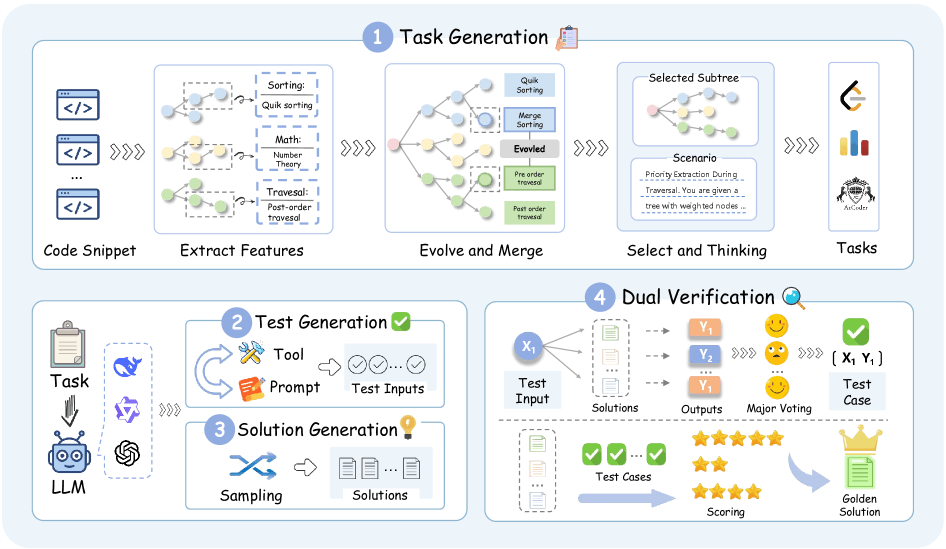
Die vorgestellte Pipeline namens SynthSmith generiert stattdessen Aufgaben, Lösungen und Testfälle vollständig neu. Der Prozess beginnt mit der Extraktion wettbewerbsrelevanter Merkmale aus 10.000 existierenden Code-Beispielen. Diese Merkmale umfassen Algorithmen, Datenstrukturen und Optimierungstechniken. Durch einen Evolutionsprozess erweitert das System den Pool von 27.400 auf knapp 177.000 Algorithmus-Einträge. Aus diesen Bausteinen kombiniert die Pipeline dann neue Programmieraufgaben in verschiedenen Stilen.
Die Qualitätssicherung erfolgt in zwei Stufen. Zunächst bestimmt das System durch Mehrheitsentscheidung über mehrere Kandidatenlösungen die korrekten Testausgaben. Anschließend validiert es die beste Lösung an einem zurückgehaltenen Testset, um Überanpassung zu vermeiden.
7B-Modell vor 14B-Konkurrenz
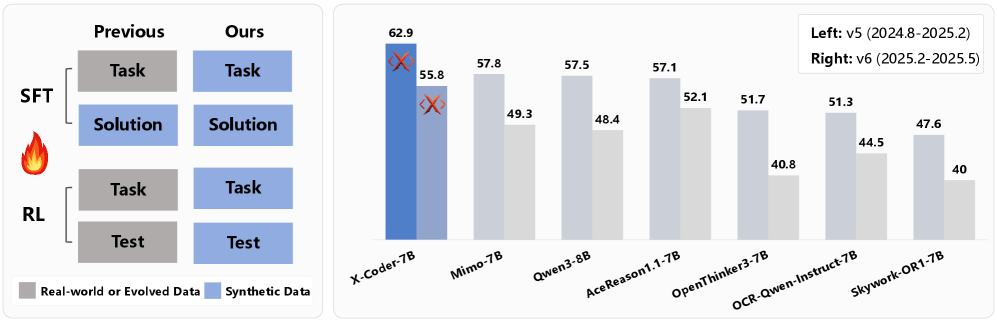
Das X-Coder-Modell mit 7 Milliarden Parametern erreicht auf LiveCodeBench v5 eine durchschnittliche Pass-Rate von 62,9 bei acht Versuchen. Auf der neueren Version v6 liegt der Wert bei 55,8. Das Modell übertrifft damit DeepCoder-14B-Preview und AReal-boba²-14B, die beide 14 Milliarden Parameter umfassen und auf einem stärkeren Basismodell aufbauen.
Im Vergleich mit dem derzeit größten öffentlichen Datensatz für Code-Reasoning erzielt SynthSmith einen Vorsprung von 6,7 Punkten. Die Forscher führen dies auf anspruchsvollere Aufgaben zurück, die längere Denkprozesse erfordern. Die durchschnittliche Länge der Reasoning-Ketten beträgt 17.700 Token gegenüber 8.000 Token beim Vergleichsdatensatz.
Eine zusätzliche Reinforcement-Learning-Phase bringt einen Gewinn von 4,6 Prozentpunkten. Das Training funktioniert auch mit fehlerbehafteten synthetischen Testfällen, die eine Fehlerrate von etwa fünf Prozent aufweisen. Laut Paper erforderte das Training 128 H20-GPUs über 220 Stunden für das überwachte Feintuning sowie 32 H200-GPUs über sieben Tage für das Reinforcement Learning.
Weniger Kontamination durch synthetische Daten
Ein Vorteil des synthetischen Ansatzes zeigt sich beim Vergleich älterer und neuerer Benchmarks. Das Referenzmodell Qwen3-8B erreichte auf einer älteren Version des LiveCodeBench einen Score von 88,1, fiel aber auf der neueren Version auf 57,5.
X-Coder zeigt mit Scores von 78,2 und 62,9 einen geringeren Rückgang von 17,2 Punkten. Da das Modell ausschließlich auf synthetischen Daten trainiert wurde, könne es keine Aufgaben aus älteren Benchmarks auswendig gelernt haben. Die Forscher wollen die Modellgewichte veröffentlichen, auf GitHub befindet sich bereits der Code zur Aufbereitung des Trainingsmaterials.
Das Interesse an synthetischen Trainingsdaten wächst in der KI-Branche. Vergangenes Jahr stellte das Start-up Datology AI mit BeyondWeb ein Framework vor, das bestehende Webdokumente umformuliert, um informationsdichtere Trainingsdaten zu erzeugen. Auch Nvidia setzt verstärkt auf synthetische Daten in der Robotik, um den Mangel an realen Trainingsdaten zu kompensieren. Das Unternehmen will auf diesem Weg ein Datenproblem in ein Rechenproblem verwandeln.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.