Ein Modell, viele Stimmen: Reasoning-KI simuliert interne Expertenteams – und wird dadurch präziser

Kurz & Knapp
- Eine neue Studie legt dar, dass Reasoning-Modelle komplexe Aufgaben lösen, indem sie intern eine Debatte zwischen verschiedenen simulierten Perspektiven führen.
- Anstatt linear zu antworten, erzeugen diese Systeme eine "Gesellschaft des Denkens", in der unterschiedliche interne Stimmen einander hinterfragen und korrigieren.
- Dieses Vorgehen soll zu besseren Ergebnissen führen als bei herkömmlichen Sprachmodellen.
Reasoning-Modelle wie Deepseek-R1 denken nicht einfach länger nach. Sie simulieren laut einer neuen Studie intern eine Art Debatte zwischen verschiedenen Perspektiven, die sich gegenseitig hinterfragen und korrigieren.
Forschende von Google, der University of Chicago und dem Santa Fe Institute haben untersucht, warum Reasoning-Modelle wie Deepseek-R1 und QwQ-32B bei komplexen Aufgaben deutlich besser abschneiden als herkömmliche Sprachmodelle. Demnach erzeugen diese Modelle in ihren Gedankenketten eine "Gesellschaft des Denkens". Dabei handele es sich um mehrere simulierte Stimmen mit unterschiedlichen Persönlichkeiten und Fachexpertisen, die miteinander diskutieren.
Reasoning-Modelle führen interne Debatten
Die Analyse von über 8000 Reasoning-Problemen zeigt laut der Studie deutliche Unterschiede zwischen Reasoning-Modellen und gewöhnlichen Instruction-tuned Modellen. Im Vergleich zu Deepseek-V3 zeigt Deepseek-R1 signifikant mehr Frage-Antwort-Sequenzen und häufigere Perspektivwechsel. Bei QwQ-32B treten zudem deutlich mehr explizite Konflikte zwischen verschiedenen Standpunkten auf als beim vergleichbaren Qwen-2.5-32B.
Die Forschenden identifizierten diese Muster mithilfe eines LLM-as-judge-Ansatzes, bei dem Gemini 2.5 Pro die Reasoning-Traces klassifizierte. Die Übereinstimmung mit menschlichen Bewertern war dabei substanziell.
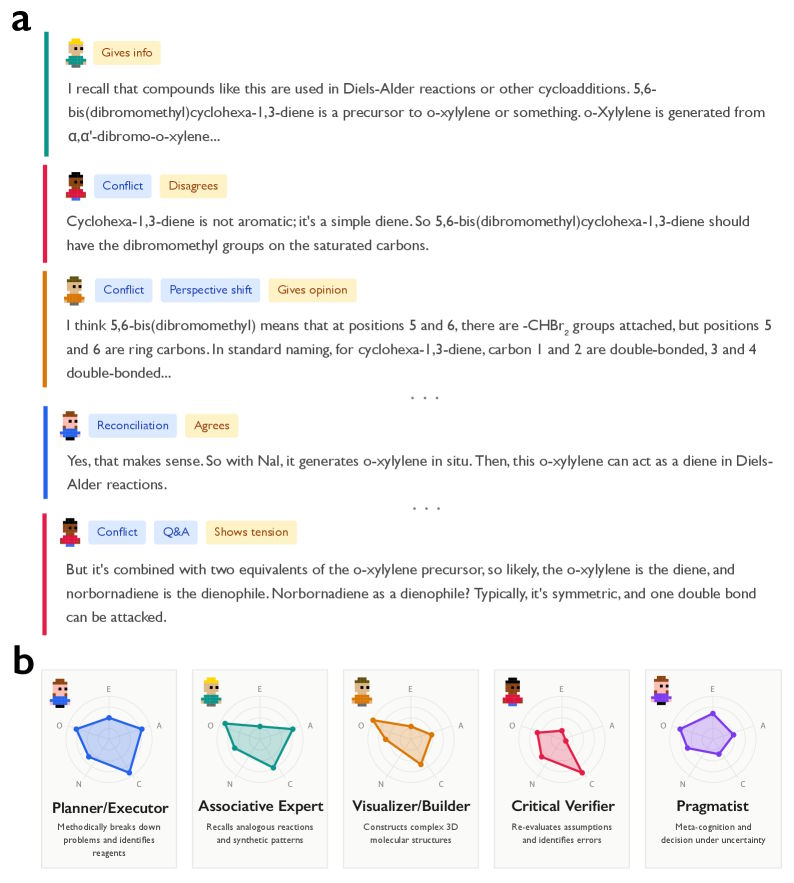
Ein Beispiel aus der Studie verdeutlicht den Unterschied: Bei einem komplexen Chemie-Problem zur mehrstufigen Diels-Alder-Synthese zeigte Deepseek-R1 Perspektivwechsel und Konflikte. Das Modell schrieb etwa "But here, it's cyclohexa-1,3-diene, not benzene" und hinterfragte damit seine eigenen Annahmen. Deepseek-V3 hingegen produzierte eine "lineare Kette von Meinungen" ohne Selbstkorrektur und kam zum falschen Ergebnis.
Verschiedene Persönlichkeiten im Reasoning-Verlauf
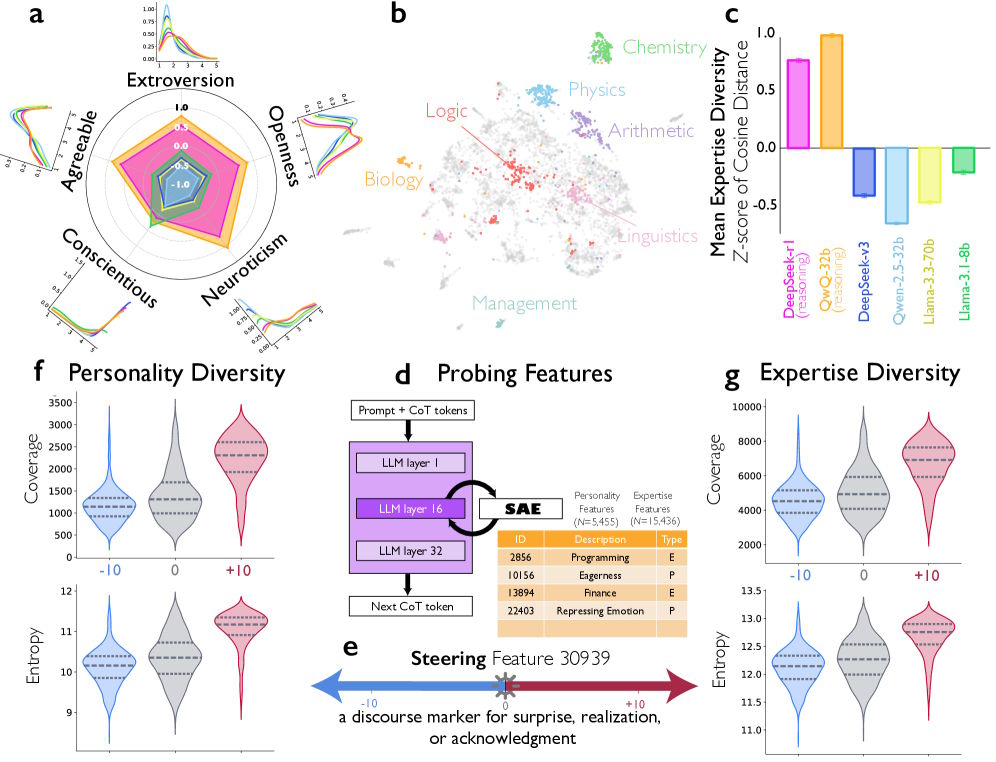
Die Forschenden gingen noch einen Schritt weiter und ließen die impliziten Perspektiven in den Reasoning-Verläufen charakterisieren. Dabei zeigte sich, dass Deepseek-R1 und QwQ-32B eine deutlich höhere Persönlichkeitsdiversität aufweisen als Instruction-tuned Modelle. Gemessen wurde dies an allen fünf Big-Five-Dimensionen: Extraversion, Verträglichkeit, Gewissenhaftigkeit, Neurotizismus und Offenheit.
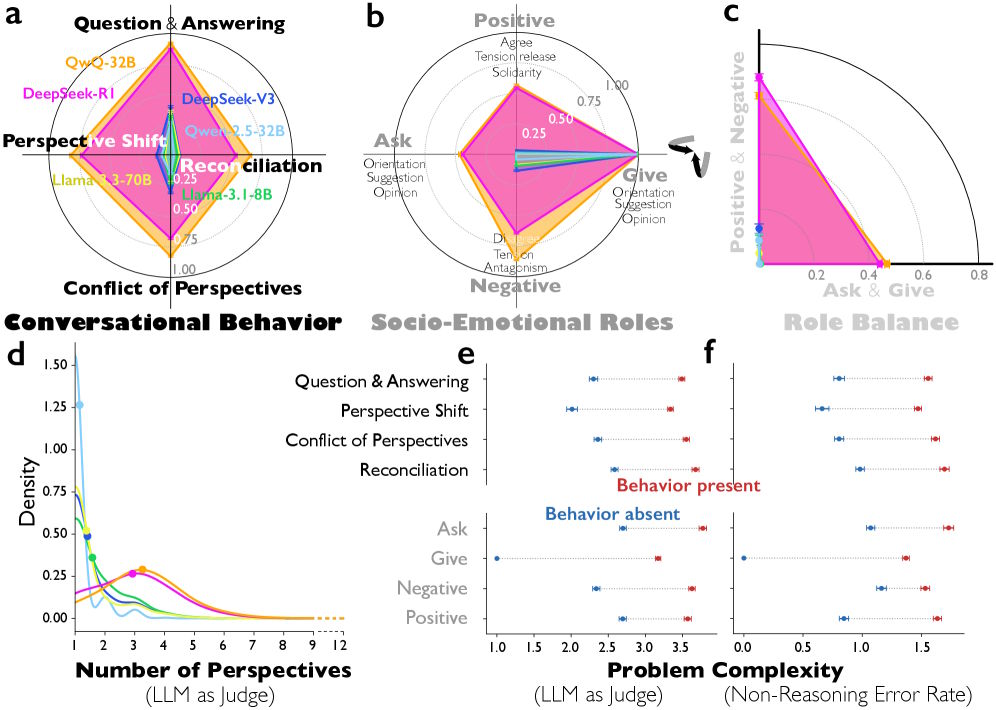
Interessanterweise war die Diversität bei Gewissenhaftigkeit geringer: Alle simulierten Stimmen wirkten diszipliniert und fleißig. Dieses Muster deckt sich laut den Autoren mit Erkenntnissen aus der Teamforschung. Demnach verbessert Variabilität bei sozial orientierten Eigenschaften wie Extraversion und Neurotizismus die Teamleistung, während sie bei aufgabenorientierten Eigenschaften wie Gewissenhaftigkeit eher schadet.
Bei einem kreativen Schreibproblem identifizierte der LLM-as-Judge in Deepseek-R1s Gedankenkette sieben verschiedene Perspektiven – darunter einen "kreativen Ideengeber" mit hoher Offenheit und einen "semantischen Treue-Prüfer" mit niedriger Verträglichkeit, der Einwände formuliert wie: "But that adds 'deep-seated' which wasn't in the original."
Feature Steering verdoppelt die Genauigkeit
Um zu prüfen, ob die konversationellen Muster tatsächlich ursächlich für besseres Reasoning sind, nutzten die Forschenden eine Methode aus der mechanistischen Interpretierbarkeit. Sie macht sichtbar, welche Merkmale ein Modell intern aktiviert.
Dabei fanden sie in Deepseek-R1-Llama-8B ein Merkmal, das für typische Gesprächssignale steht – etwa Überraschung, Erkenntnis oder Bestätigung, wie sie bei einem Sprecherwechsel auftreten.
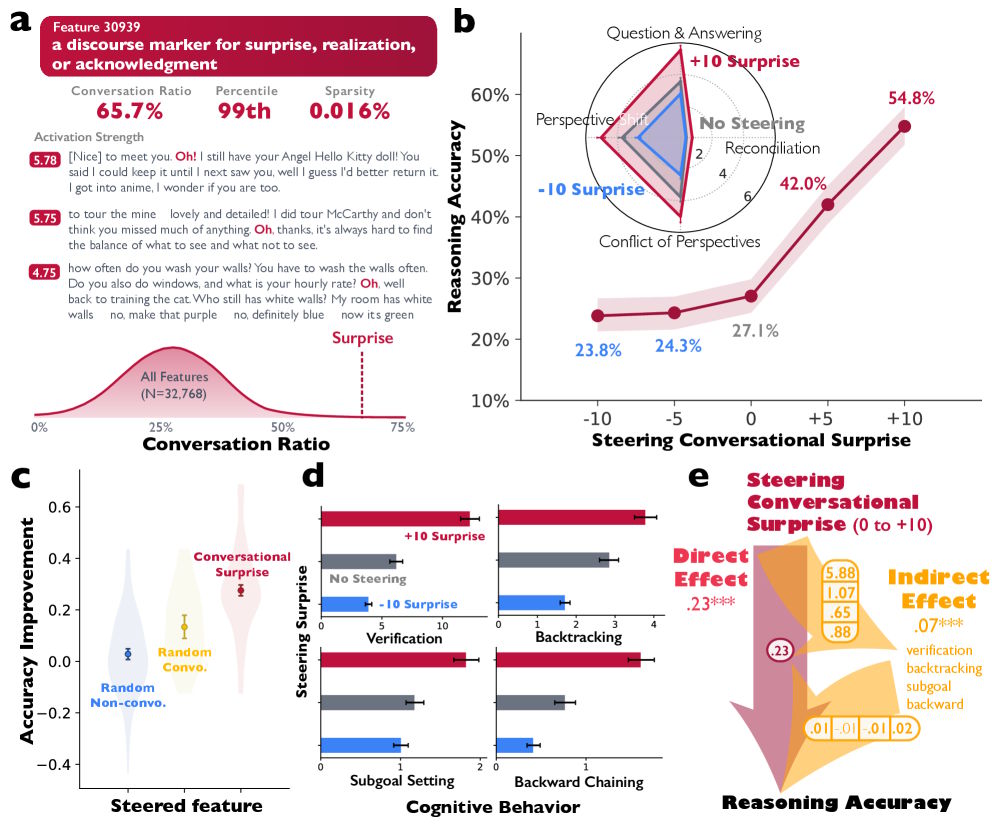
Als die Forschenden dieses Merkmal bei der Textgenerierung künstlich verstärkten, verdoppelte sich die Genauigkeit bei einer Rechenaufgabe von 27,1 auf 54,8 Prozent. Zugleich verhielten sich die Modelle stärker dialogartig: Sie überprüften Zwischenergebnisse häufiger und korrigierten Fehler eigenständig.
Soziales Reasoning entsteht spontan durch Reinforcement Learning
Die Forschenden führten auch kontrollierte Reinforcement-Learning-Experimente durch. Dabei zeigte sich, dass Basismodelle spontan gesprächige Verhaltensweisen entwickeln, wenn sie für Genauigkeit belohnt werden. Ein explizites Training für Dialogstrukturen war nicht nötig.
Noch deutlicher war der Effekt bei Modellen, die zuvor mit dialogartigen Denkverläufen trainiert wurden: Sie erreichten schneller hohe Genauigkeit als solche mit linearen, monologartigen Verläufen. Bei Qwen-2.5-3B etwa kamen dialogtrainierte Modelle nach 40 Trainingsschritten auf rund 38 Prozent Genauigkeit. Monologtrainierte Modelle stagnierten bei 28 Prozent.
Die dialogartige Denkstruktur übertrug sich zudem auf andere Aufgaben: Modelle, die bei Rechenaufgaben mit simulierten Diskussionen zwischen mehreren Perspektiven trainiert wurden, lernten selbst bei der Erkennung politischer Falschinformationen schneller.
Parallelen zur kollektiven Intelligenz
Die Autoren ziehen Parallelen zur Forschung über kollektive Intelligenz in menschlichen Gruppen. Merciers und Sperbers "Enigma of Reason"-Theorie geht davon aus, dass menschliches Denken primär als sozialer Prozess entstanden ist. Bakhtins Konzept des "dialogischen Selbst" beschreibt menschliches Denken als internalisiertes Gespräch zwischen verschiedenen Perspektiven.
Die Studie legt nahe, dass Reasoning-Modelle eine rechnerische Parallele zu dieser kollektiven Intelligenz bilden: Diversität ermöglicht demnach besseres Problemlösen, vorausgesetzt, sie wird systematisch strukturiert.
Die Forschenden betonen, dass sie keine Aussage darüber treffen, ob die Reasoning-Traces als Diskurs zwischen simulierten menschlichen Gruppen zu verstehen sind oder als Simulation eines Geistes, der seinerseits Multi-Agenten-Interaktion nachbildet. Die Übereinstimmungen mit Erkenntnissen über erfolgreiche menschliche Teams deuteten jedoch darauf hin, dass Prinzipien effektiver Gruppenarbeit wertvolle Hinweise für die Entwicklung von Reasoning in Sprachmodellen liefern könnten.
Im Sommer 2025 hatten Apple-Forscher grundlegende Zweifel an der "Denkfunktion" von Reasoning-Modellen geäußert. Ihre Untersuchung zeigte, dass Modelle wie DeepSeek-R1 bei steigender Problemkomplexität scheitern, und paradoxerweise auch weniger nachdenken. Die Apple-Forscher sahen darin eine "fundamentale Skalierungsgrenze". Auch andere Studien kamen zu diesem Ergebnis, das allerdings umstritten ist.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren