Nvidias offene Sprach-KI PersonaPlex kombiniert schnelle Reaktionen mit flexiblen Persönlichkeiten
Kurz & Knapp
- Nvidia stellt mit PersonaPlex ein Konversations-KI-Modell vor, das natürliche Echtzeitgespräche mit anpassbarer Stimme und frei definierbarer Rolle ermöglicht.
- Das Modell hört und spricht gleichzeitig, erreicht beim Sprecherwechsel eine Latenz von 0,07 Sekunden (Gemini Live: 1,3 Sekunden) und lernt natürliches Sprachverhalten wie Unterbrechungen oder bestätigende Laute.
- In Tests erzielte PersonaPlex einen Dialog-Natürlichkeitswert von 3,90 gegenüber 3,72 für Gemini Live sowie eine Erfolgsrate von 100 Prozent bei Nutzerunterbrechungen. Code und Modellgewichte sind unter offenen Lizenzen auf Hugging Face und GitHub verfügbar.
Nvidia stellt ein neues Konversations-KI-Modell vor, das einen grundlegenden Kompromiss bisheriger Systeme aufheben soll. PersonaPlex ermöglicht natürliche Echtzeitgespräche mit anpassbarer Stimme und frei definierbarer Rolle.
Klassische Sprachassistenten schalten Spracherkennung, Sprachmodell und Sprachsynthese hintereinander, was zwar die Anpassung von Stimme und Rolle erlaubt, aber zu roboterhaften Gesprächen mit unnatürlichen Pausen führt.
Neuere Systeme wie Moshi vom französischen KI-Labor Kyutai machten Gespräche natürlicher, sperrten Nutzer jedoch in eine einzige feste Stimme und Rolle. PersonaPlex soll laut Nvidia beide Vorteile vereinen. Nutzer können aus verschiedenen Stimmen wählen und beliebige Rollen durch Textprompts definieren, ob weiser Assistent, Kundenservice-Agent oder Fantasy-Charakter.
Hören und Sprechen zugleich
Im Unterschied zu herkömmlichen Systemen hört und spricht PersonaPlex gleichzeitig. Das Modell lernt dadurch neben Sprachinhalten auch das mit Sprache verbundene Verhalten, etwa wann es pausieren, wann unterbrechen und wann bestätigende Laute wie „uh-huh" einwerfen soll. Ein einziges Modell aktualisiert seinen internen Zustand, während der Nutzer spricht, und streamt die Antwort unmittelbar zurück.
Bei Tests erreichte PersonaPlex laut dem technischen Paper eine Latenz von 0,07 Sekunden beim Sprecherwechsel – verglichen mit 1,3 Sekunden bei Googles Gemini Live. Das Modell baut auf Moshi auf und umfasst 7 Milliarden Parameter bei einer Audio-Abtastrate von 24 kHz.
Hybride Prompts ermöglichen Stimm- und Rollenkontrolle
Die Kerninnovation liegt in einem hybriden System-Prompt, der zwei Eingaben kombiniert. Ein Voice-Prompt in Form eines kurzen Audiobeispiels erfasst Stimmcharakteristik und Sprechstil. Ein Text-Prompt beschreibt Rolle, Hintergrundinformationen und Konversationskontext. Beide werden gemeinsam verarbeitet, um eine kohärente Persona zu erzeugen.
Die Forscher demonstrieren das System anhand verschiedener Szenarien. In einem Kundenservice-Beispiel für eine Bank verifiziert das System die Kundenidentität, erklärt eine abgelehnte Transaktion und zeigt dabei Empathie sowie Akzentkontrolle. In einem Arztpraxis-Szenario erfasst es Patientendaten wie Name, Geburtsdatum und Medikamentenallergien.
In einem Weltraum-Notfall-Szenario spielt PersonaPlex einen Astronauten, während einer Reaktorkern-Schmelze auf einer Mars-Mission. Das Modell halte eine kohärente Persona aufrecht, zeige angemessene Töne von Stress und Dringlichkeit und handhabe technisches Krisenmanagement-Vokabular, obwohl nichts davon in den Trainingsdaten vorkam.
Training mit echten und synthetischen Gesprächen
Eine zentrale Herausforderung war der Mangel an Sprachdaten, die ein breites Themenspektrum und natürliches Verhalten wie Unterbrechungen abdecken. Die Forscher lösten dies durch eine Mischung aus echten und synthetischen Daten.
Das veröffentlichte Modell wurde mit 7.303 echten Gesprächen aus dem Fisher English Corpus trainiert, was 1.217 Stunden entspricht. Die wurden nachträglich mit Prompts unterschiedlicher Detailtiefe annotiert. Zusätzlich generierten die Forscher 39.322 synthetische Assistenten-Dialoge und 105.410 synthetische Kundenservice-Gespräche. Die Transkripte entstanden mit Alibabas Qwen3-32B und OpenAIs GPT-OSS-120B, die Sprache mit Chatterbox TTS von Resemble AI.
Die synthetischen Daten lieferten Aufgabenwissen und Instruktionsbefolgung, während die echten Aufnahmen natürliche Sprachmuster beisteuerten.
PersonaPlex übertrifft kommerzielle und Open-Source-Systeme
Zur Evaluation erweiterten die Forscher den bestehenden Full-Duplex-Bench-Benchmark um Service-Duplex-Bench mit 350 Kundenservice-Fragen in 50 Service-Rollen-Szenarien. In den Tests erreichte PersonaPlex einen Dialog Naturalness Mean Opinion Score von 3,90, verglichen mit 3,72 für Gemini Live, 3,70 für Qwen 2.5 Omni und 3,11 für Moshi.
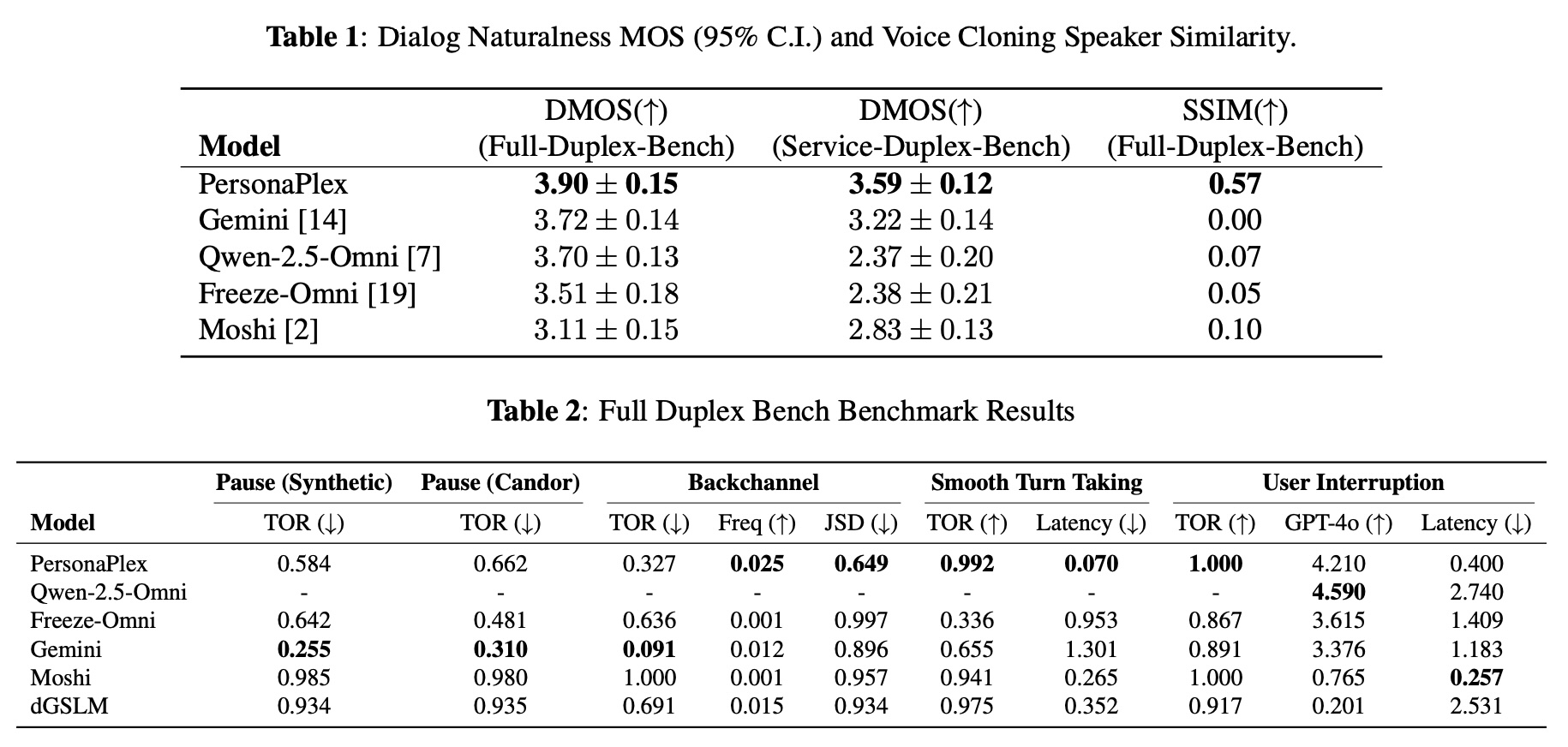
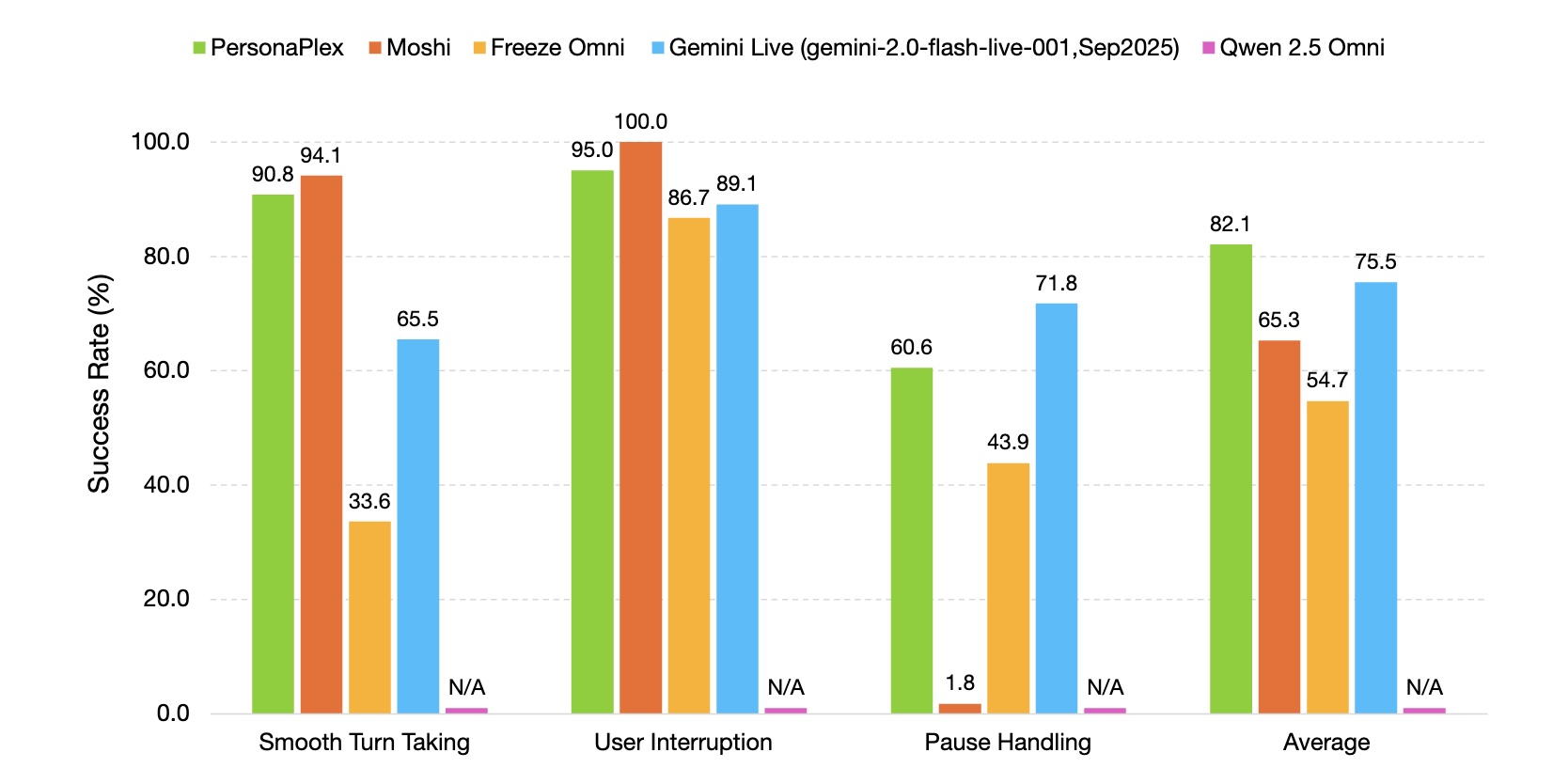
Bei der Sprecherähnlichkeit für Voice Cloning erzielte PersonaPlex einen Wert von 0,57, während Gemini, Qwen und Moshi nahe null lagen. Beim sanften Sprecherwechsel erreichte das Modell eine Erfolgsrate von 99,2 Prozent, bei Nutzerunterbrechungen 100 Prozent. Die Forscher bezeichnen PersonaPlex als nach ihrem Wissen erstes offenes Modell, das vergleichbare Natürlichkeit wie geschlossene kommerzielle Systeme erreicht.
Das Training dauerte sechs Stunden auf acht A100-GPUs. Code und Modellgewichte sind auf Hugging Face und GitHub unter MIT- bzw. Nvidias Open Model License verfügbar: Die Modelle dürfen kommerziell genutzt werden und Nvidia erhebt keine Rechte an den Outputs. Das Modell wurde ausschließlich auf englischen Daten trainiert. Künftig wollen die Forscher das Alignment nach dem Training in den Fokus rücken und externe Tools integrieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren