Tauben-Gurren für die Wal-Erkennung: Google Deepminds neue Bioakustik-KI zeigt die Stärke von Generalisierung

Kurz & Knapp
- Ein Bioakustik-Modell von Google Deepmind, das hauptsächlich mit Vogelstimmen trainiert wurde, übertrifft bei der Erkennung von Walgesängen spezialisierte Wal-Modelle.
- Die Forscher erklären den Transfer damit, dass Vogelklassifikation extrem feine akustische Unterscheidungen erfordert und Vögel und Meeressäuger evolutionär ähnliche Mechanismen der Schallerzeugung entwickelt haben.
- Auf Basis des Modells lassen sich innerhalb weniger Stunden Klassifikatoren für neu entdeckte Lauttypen trainieren. Das ist relevant, weil in der marinen Bioakustik neue Laute teils erst Jahrzehnte später einer Art zugeordnet werden.
Ein Bioakustik-Grundlagenmodell von Google Deepmind, das zum großen Teil mit Vogelstimmen trainiert wurde, übertrifft bei der Klassifikation von Unterwasser-Tierlauten sogar Modelle, die gezielt auf Wale trainiert wurden. Die Erklärung dafür reicht bis in die Evolutionsbiologie.
Weil Sichtkontakt unter Wasser oft unmöglich ist, lässt sich das Verhalten von Walen und Delfinen häufig nur über ihre Laute erfassen. Doch zuverlässige KI-Klassifikatoren für Unterwassergeräusche zu entwickeln, ist schwierig. Die Datenerhebung erfordert teure Spezialausrüstung, und neue Lauttypen werden laut den Forschern mitunter erst Jahrzehnte nach ihrer Aufnahme einer Spezies zugeordnet.
Ein Team von Google Deepmind und Google Research zeigt nun in einem Paper, dass ein ganz anderer Ansatz funktionieren könnte. Ihr Bioakustik-Grundlagenmodell Perch 2.0, das hauptsächlich mit Vogelstimmen trainiert wurde, übertrifft bei der Klassifikation von Walgesängen fast durchgehend alle Vergleichsmodelle, darunter auch ein speziell auf Wale trainiertes Google-Modell.
Ein Vogelmodell erkennt Wale
Das 101,8-Millionen-Parameter-Modell Perch 2.0 wurde auf mehr als 1,5 Millionen Aufnahmen von Tierlauten trainiert, die mindestens 14 500 Arten abdecken. Der Großteil davon sind Vögel, ergänzt um Insekten, Säugetiere und Amphibien. Unterwasseraufnahmen sind in den Trainingsdaten praktisch nicht enthalten. Laut dem Paper finden sich lediglich rund ein Dutzend Wal-Aufnahmen, die größtenteils mit Mobiltelefonen über Wasser aufgenommen wurden.
Um zu testen, wie gut das Vogelmodell trotzdem unter Wasser funktioniert, nutzten die Forscher drei marine Datensätze. Einer enthält verschiedene Bartenwalarten aus dem Pazifik (NOAA PIPAN), ein weiterer Riffgeräusche wie Knacken und Knurren (ReefSet) und ein dritter mehr als 200.000 annotierte Orca- und Buckelwal-Laute (DCLDE 2026).
Das Modell erzeugt für jede Aufnahme eine kompakte numerische Repräsentation, ein sogenanntes Embedding. Auf diesen Embeddings wird dann mit nur wenigen gelabelten Beispielen ein einfacher Klassifikator trainiert, der die Laute den richtigen Arten zuordnet.

Spezialisierte Wal-KI schneidet schlechter ab
Die Forscher verglichen Perch 2.0 mit sechs anderen Modellen, darunter das speziell auf Wale trainierte Google Multispecies Whale Model (GMWM). Die Leistung wurde mit dem AUC-ROC-Wert gemessen, einer Kennzahl für die Trennschärfe eines Klassifikators, bei der 1,0 perfekte Unterscheidung bedeutet.
Perch 2.0 ist bei fast jeder Aufgabe das beste oder zweitbeste Modell. Bei der Unterscheidung verschiedener Orca-Subpopulationen anhand ihrer Laute erreicht es 0,945, das Wal-Modell nur 0,821. Bei der Zuordnung von Unterwasserlauten liegt Perch 2.0 bei 0,977, das GMWM bei 0,914, wohlgemerkt mit jeweils nur 16 Trainingsbeispielen pro Kategorie.
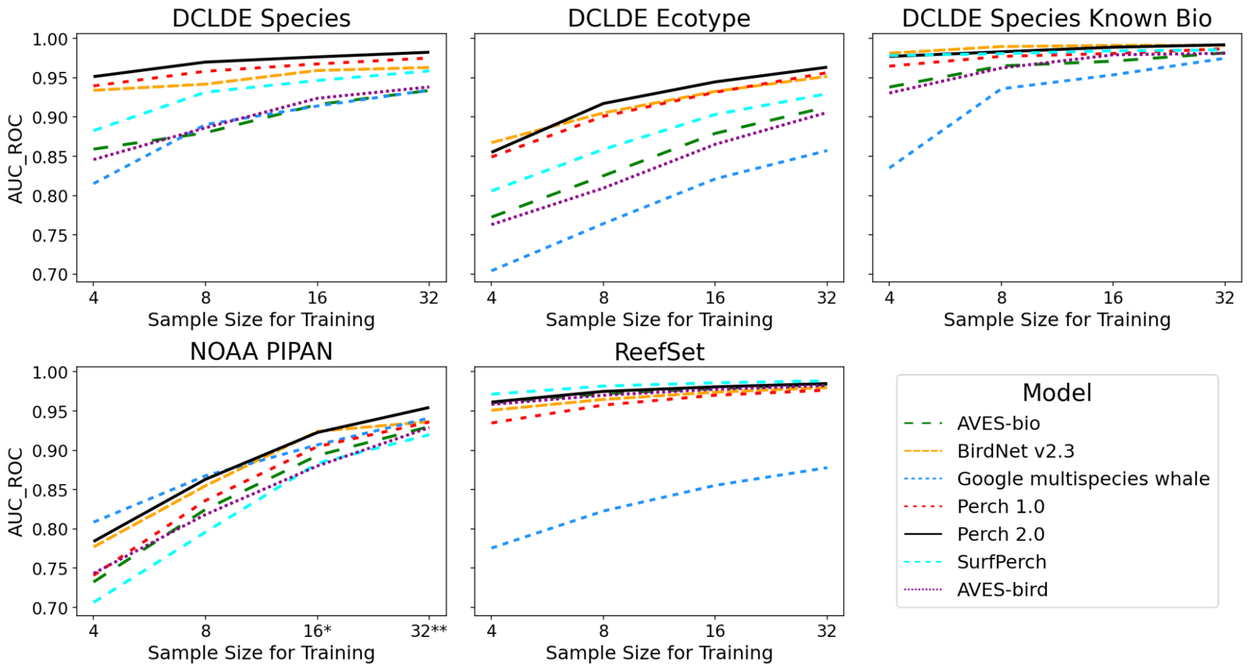
Noch deutlicher wird der Unterschied, wenn das GMWM nicht für Transfer Learning genutzt wird, sondern direkt als fertiger Klassifikator: Dann fällt seine Leistung auf 0,612. Die Forscher vermuten, dass sich das Modell zu stark an bestimmte Mikrofone oder andere Eigenschaften seiner Trainingsdaten angepasst hat. Insgesamt scheint Spezialisierung auf eine bestimmte Domäne die Generalisierungsfähigkeit einzuschränken.
Die "Bittern Lesson" der Bioakustik
Die Forscher bieten drei Erklärungen für den überraschenden Domänentransfer. Erstens greifen neurale Skalierungsgesetze: Größere Modelle mit mehr Trainingsdaten generalisieren besser, auch auf Aufgaben außerhalb ihrer Trainingsdomäne.
Zweitens die sogenannte "Bittern Lesson", ein Wortspiel aus der Vogelart Rohrdommel, zu Englisch "bittern", und der "Bitter Lesson": Vogelklassifikation sei besonders anspruchsvoll, weil die Unterschiede zwischen den Arten oft minimal sind. Allein in Nordamerika gebe es 14 Taubenarten mit jeweils subtil unterschiedlichem Gurren. Ein Modell, das diese feinen Unterschiede zuverlässig erkennt, lernt dabei akustische Merkmale, die sich auch für völlig andere Aufgaben als nützlich erweisen.
Drittens ein evolutionsbiologischer Zusammenhang: Vögel und Meeressäugetiere haben unabhängig voneinander ähnliche Mechanismen der Schallerzeugung entwickelt, den sogenannten myoelastisch-aerodynamischen Mechanismus. Diese gemeinsame physikalische Grundlage könnte erklären, warum akustische Merkmale so gut zwischen den Tiergruppen übertragbar sind.
Schnelle Klassifikatoren für neue Entdeckungen
Die praktische Bedeutung liegt im sogenannten "Agile Modeling": Passive akustische Daten werden in einer Vektor-Datenbank eingebettet, lineare Klassifikatoren auf vorberechneten Embeddings lassen sich innerhalb weniger Stunden trainieren. Das ist relevant, weil in der marinen Bioakustik ständig neue Lauttypen entdeckt werden. So wurde etwa das mysteriöse "Biotwang"-Geräusch den Bryde-Walen zugeordnet.
Google stellt ein End-to-End-Tutorial in Google Colab bereit und macht die Werkzeuge auf GitHub verfügbar.
Zuvor hatte Google bereits 2024 sein Multi-Species Whale Model veröffentlicht, das auf die Erkennung mehrerer Walarten spezialisiert war. Im August 2025 folgte Perch 2.0 als breiteres Bioakustik-Grundlagenmodell.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren