KI-Daten: Aktuelles Sprachmodell-Training verschenkt große Teile des Internets

Große Sprachmodelle lernen aus Webdaten. Doch welche Seiten im Trainingsdatensatz landen, hängt stark vom HTML-Extraktor ab. Forscher bei Apple, Stanford und der University of Washington zeigen, dass drei gängige Werkzeuge überraschend unterschiedliche Teile des Webs erschließen.
Große Sprachmodelle lernen Sprache, Fakten und Fähigkeiten insbesondere aus Texten, die aus dem Internet stammen. Common Crawl, ein frei verfügbares Archiv des Webs, bildet das Rückgrat der meisten Trainingsdatensätze.
Bevor diese Rohdaten in ein Modell fließen, muss der eigentliche Text aus dem HTML-Code jeder Seite herausgelöst werden. Navigationsleisten, versteckte Elemente, visuelles Styling werden dabei entfernt.
Dieser Schritt klingt trivial, ist aber laut einer neuen Studie von Forschern bei Apple, der Stanford University und der University of Washington ein erheblich unterschätzter Faktor für Qualität und Umfang von Trainingsdaten.
Obwohl es mehrere solcher Extraktions-Werkzeuge gibt, etwa das auf Geschwindigkeit optimierte resiliparse, das ausbalancierte trafilatura oder das Stoppwort-basierte jusText, wählt jedes führende Datensatz-Projekt genau eines davon aus und wendet es auf alle Webseiten an. Da Modelle bei Standard-Benchmarks mit jedem dieser Werkzeuge ähnliche Ergebnisse erzielten, galt die Wahl bisher als weitgehend beliebig.
Extraktoren-Kombination steigert Token-Ausbeute um bis zu 71 Prozent
Eine Studie stellt diese Annahme infrage. Die Forscher wendeten dieselbe Filterpipeline auf die Ausgaben aller drei Extraktoren an und verglichen, welche Webseiten jeweils die Filter passieren. Das Ergebnis: Nur 39 Prozent der Seiten wurden von mehr als einem Extraktor erfasst. Die übrigen 61 Prozent tauchten jeweils nur in der Ausgabe eines einzigen Tools auf. Jeder Extraktor erschließt also systematisch andere Bereiche des Webs. Wer nur eines der Werkzeuge einsetzt, verschenkt einen Großteil der verfügbaren Daten.
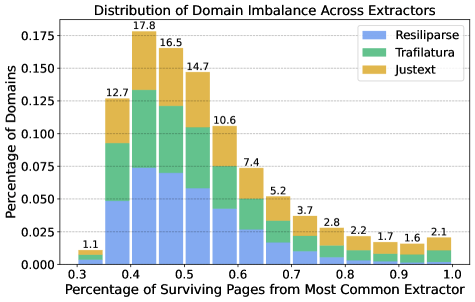
Nimmt man die Vereinigungsmenge aller drei Extraktoren, steigt die Token-Ausbeute laut der Studie um bis zu 71 Prozent – bei gleichbleibender Performance auf Standard-Benchmarks. Selbst nach erneuter Deduplizierung blieben 58 Prozent mehr Token übrig. Konkret wuchs der Datensatz für 7B-Modelle von 193 Milliarden Token (nur Resiliparse) auf 283 Milliarden.
Der kombinierte Ansatz schlug dabei auch das bloße Lockern der Filterschwellen eines einzelnen Extraktors: Strenge Filter über mehrere Werkzeuge hinweg lieferten qualitativ hochwertigere Seiten als großzügigere Schwellenwerte bei nur einem. Besonders deutlich zeigte sich der Vorteil in Simulationen datenknapper Szenarien, die die zunehmende Erschöpfung verfügbarer Internetdaten abbilden.

Bei Tabellen und Code versagen einzelne Extraktoren teilweise komplett
Bei allgemeinen Sprachaufgaben wirken die Extraktoren weitgehend austauschbar. Bei strukturierten Inhalten wie Tabellen und Code-Blöcken zeigen sich jedoch drastische Unterschiede: JusText entfernt Tabellen und Code häufig vollständig. Trafilatura versucht, Tabellen in Markdown umzuwandeln, verliert dabei aber Zellinhalte. Resiliparse erhält den Inhalt am zuverlässigsten.
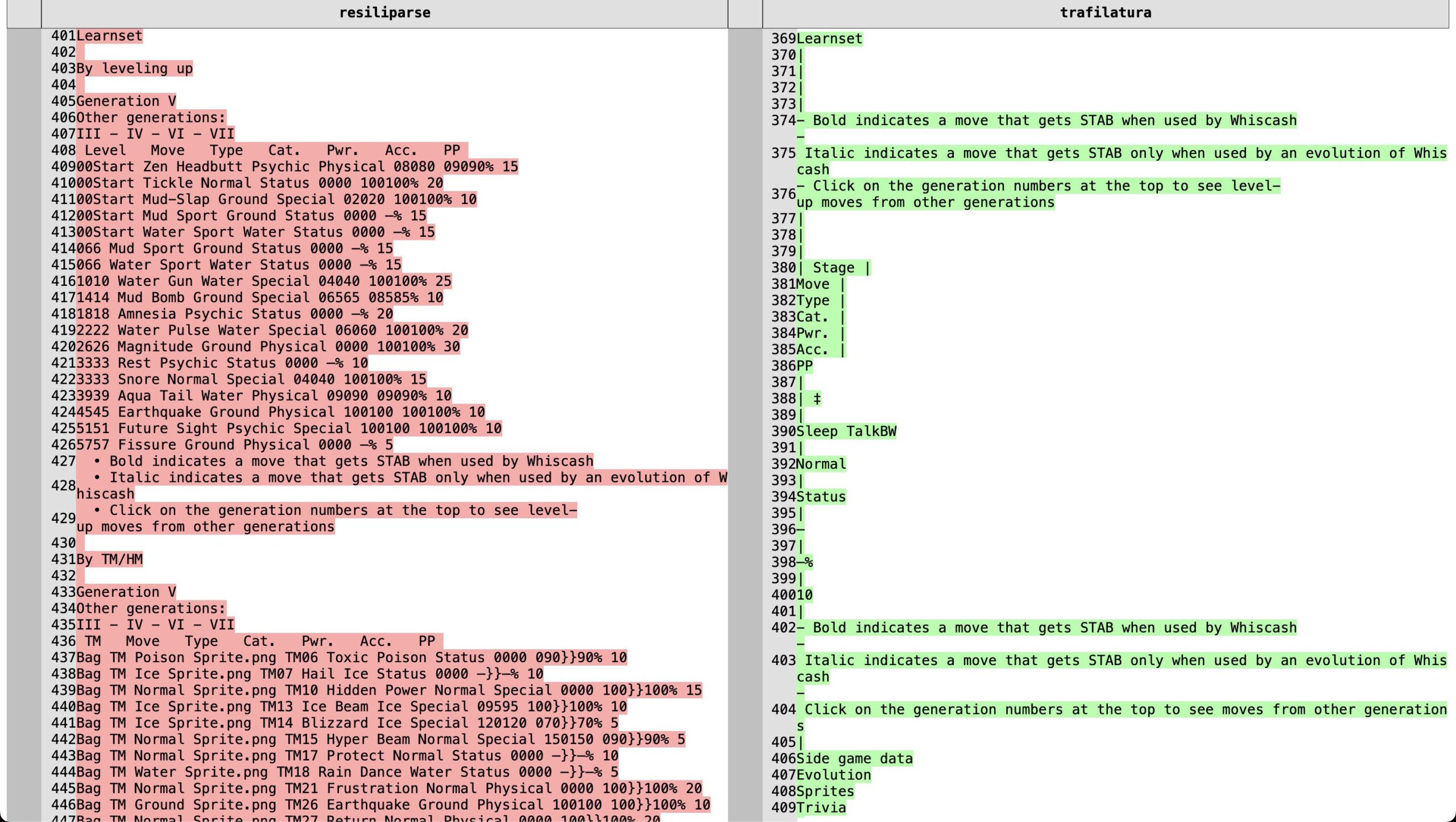
Auf dem Benchmark WikiTableQuestions erreichte ein mit Resiliparse trainiertes 7B-Modell 11,9 Punkte. Trafilatura kam auf 3,7, JusText auf nur 1,6 Punkte. Mit Resiliparse ließen sich so 73 Prozent der Lücke zwischen DCLM-7B-8k und Llama-3-8B beim Tabellenverständnis schließen, obwohl beide Modelle auf allgemeinen Benchmarks vergleichbar abschneiden.
Auch beim Code-Benchmark HumanEval fiel JusText mit bis zu 3,6 Prozentpunkten Rückstand ab, weil es Code-Blöcke häufig entfernt. Trafilatura wiederum zerstört die für Programmiersprachen entscheidende Whitespace-Formatierung.
Kleiner Schritt mit weitreichenden Folgen
Die Forscher wollen nach eigener Aussage keine neuen Extraktoren entwickeln, sondern zeigen, dass bestehende Werkzeuge durch parallelen Einsatz und inhaltsabhängige Auswahl deutlich mehr leisten. Ansätze, die möglicherweise weitere Bereiche des Webs erschließen könnten, wurden nicht getestet. Die Studie weist zudem auf Risiken hin: Eine effektivere Extraktion könnte Modelle auch stärker mit schädlichen oder urheberrechtlich geschützten Inhalten in Kontakt bringen.
Die Internetdaten, auf denen heutige Sprachmodelle basieren, sind eine endliche Ressource. Dass ein derart früher Verarbeitungsschritt darüber entscheidet, wie viel davon tatsächlich nutzbar ist, dürfte Entwickler von Trainingsdatensätzen dazu bringen, ihre Pipelines zu überdenken.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.