Google Deepmind veröffentlicht Gemini 3.1 Flash-Lite als schnellstes Modell der Reihe
Google DeepMind hat eine Vorschau von Gemini 3.1 Flash-Lite veröffentlicht, dem schnellsten und günstigsten Modell der Gemini-3-Reihe.
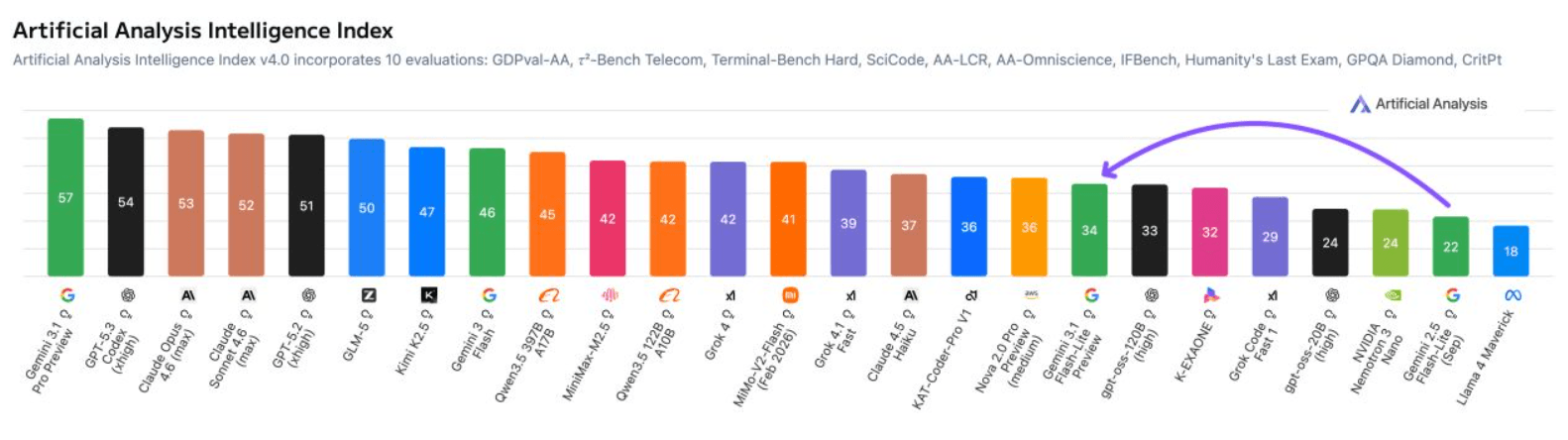
Laut der Analyseplattform Artificial Analysis erreicht das Modell 34 Punkte auf deren Intelligence Index, zwölf Punkte mehr als der Vorgänger Gemini 2.5 Flash-Lite. Mit mehr als 360 ausgegebenen Tokens pro Sekunde und einer durchschnittlichen Antwortzeit von 5,1 Sekunden bleibt das Modell so schnell wie sein Vorgänger.
Bei multimodalen Aufgaben schneidet es mit 78 Prozent auf dem Benchmark MMMU-Pro besser ab als Spitzenmodelle wie Claude Opus 4.6 und Kimi K2.5. Bei der Werkzeugnutzung zeigte das Modell laut Artificial Analysis kaum Verbesserungen. Das Kontextfenster bleibt bei einer Million Tokens.
Auf der Arena.ai-Rangliste, die Modelle anhand menschlicher Präferenzen in Blindvergleichen bewertet, erreicht es einen Elo-Wert von 1432 und übertrifft andere Modelle derselben Klasse bei logischem Denken und multimodalem Verständnis, darunter 86,9 % auf GPQA Diamond (wissenschaftliches Wissen) und 76,8 % auf MMMU Pro (multimodales Verständnis und Denken). Damit schlägt es sogar größere Gemini-Modelle früherer Generationen wie 2.5 Flash.
Laut Google ist es zudem 2,5-mal schneller beim ersten Antwort-Token und 45 Prozent schneller bei der Ausgabe als Gemini 2.5 Flash (nicht 2.5 Flash-Lite; Flash ist ein größeres Modell). Entwickler können einstellen, wie viel das Modell "nachdenkt". So lässt es sich sowohl für einfache Massenaufgaben wie Übersetzungen als auch für komplexere Aufgaben wie das Erstellen von Benutzeroberflächen anpassen.
Der Preis beim Output hat sich allerdings mehr als verdreifacht: Gemini 3.1 Flash-Lite kostet 0,25 Dollar pro Million Input-Tokens (2.5: 0,10 Dollar) und 1,50 Dollar pro Million Output-Tokens (2.5: 0,40 Dollar).
| Benchmark | Details | Gemini 3.1 Flash-Lite (High) | Gemini 2.5 Flash (Dynamic) | Gemini 2.5 Flash-Lite (Dynamic) | GPT-5 mini (High) | Claude 4.5 Haiku (Extended Thinking) | Grok 4.1 Fast (Reasoning) |
|---|---|---|---|---|---|---|---|
| Input price ($/1M tokens, no caching) | Lower is better | $0.25 | $0.30 | $0.10 | $0.25 | $1.00 | $0.20 |
| Output price ($/1M tokens) | Lower is better | $1.50 | $2.50 | $0.40 | $2.00 | $5.00 | $0.50 |
| Output speed (Tokens/s) | 363 | 249 | 366 | 71 | 108 | 145 | |
| Humanity's Last Exam (Academic reasoning, full set, text + MM) | No tools | 16.0% | 11.0% | 6.9% | 16.7% | 9.7% | 17.6% |
| GPQA Diamond (Scientific knowledge) | No tools | 86.9% | 82.8% | 66.7% | 82.3% | 73.0% | 84.3% |
| MMMU-Pro (Multimodal understanding and reasoning) | No tools | 76.8% | 66.7% | 51.0% | 74.1% | 58.0% | 63.0% |
| CharXiv Reasoning (Information synthesis from complex charts) | 73.2% | 63.7% | 55.5% | 75.5% (+ python) | 61.7% | 31.6% | |
| Video-MMMU (Knowledge acquisition from videos) | 84.8% | 79.2% | 60.7% | 82.5% | — | 74.6% | |
| SimpleQA Verified (Parametric knowledge) | 43.3% | 28.1% | 11.5% | 9.5% | 5.5% | 19.5% | |
| FACTS Benchmark Suite (Factuality across grounding, parametric, search, and MM) | 40.6% | 50.4% | 17.9% | 33.7% | 18.6% | 42.1% | |
| MMMLU (Multilingual Q&A) | 88.9% | 86.6% | 84.5% | 84.9% | 83.0% | 86.8% | |
| LiveCodeBench (Code generation, UI: 1/1/2025–5/1/2025) | 72.0% | 62.6% | 34.3% | 80.4% | 53.2% | 76.5% | |
| MRCR v2 (8-needle) (Long context performance) | 128k (average) | 60.1% | 54.3% | 30.6% | 52.5% | 35.3% | 54.6% |
| 1M (pointwise) | 12.3% | 21.0% | 5.4% | Not Supported | Not Supported | 6.1% |
Das Modell kann in Google AI Studio und Vertex AI getestet werden, Benchmark-Ergebnisse sind auf Artificial Analysis und der Arena.ai Leaderboard einsehbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren