KI-Agenten werden laut Studie an der realen Arbeitswelt vorbei entwickelt
Wie gut bilden KI-Agenten die tatsächliche Arbeitswelt ab? Eine großangelegte Studie legt offen, dass die Entwicklung von KI-Agenten fast ausschließlich auf Programmieraufgaben ausgerichtet ist und den Großteil des Arbeitsmarktes ignoriert.
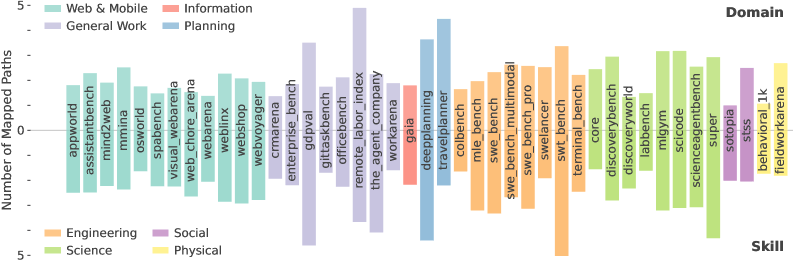
Ein Forscherteam der Carnegie Mellon University und der Stanford University hat 43 Agenten-Benchmarks mit insgesamt 72.342 Aufgaben systematisch mit dem US-Arbeitsmarkt abgeglichen. Dafür kartierten sie die Benchmark-Aufgaben auf 1.016 reale Berufe, gestützt auf die O*NET-Datenbank der US-Regierung, die berufliche Tätigkeiten auf mehreren Detailebenen katalogisiert.

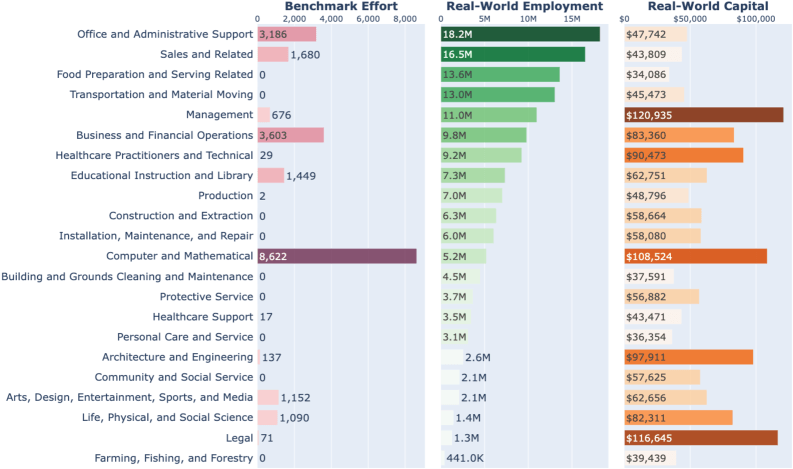
Die Studie zeigt ein deutliches Ungleichgewicht. Die aktuelle Agenten-Entwicklung zielt fast ausschließlich auf den Bereich Computer und Mathematik ab, der hauptsächlich Programmieraufgaben umfasst. Dieser Bereich macht jedoch nur 7,6 Prozent der Gesamtbeschäftigung in den USA aus.
Hochdigitalisierte Branchen werden kaum getestet
Die Analyse offenbart eine Reihe von Arbeitsbereichen, die zwar stark digitalisiert sind, aber in den bestehenden Benchmarks kaum vorkommen. Management weist laut der Studie einen Digitalisierungsgrad von 88 Prozent auf, wird aber nur in 1,4 Prozent aller analysierten Benchmark-Aufgaben abgebildet. Bei juristischen Tätigkeiten (70 Prozent digital) sind es 0,3 Prozent, bei Architektur und Ingenieurwesen (71 Prozent digital) lediglich 0,7 Prozent.
In genau diesen Bereichen könnten KI-Agenten nach Ansicht der Forscher kurzfristig Produktivitätsgewinne liefern. Zugleich stellen diese Domänen spezifische technische Herausforderungen, etwa mehrdeutige Ziele und Ergebnisse, die sich erst über lange Zeiträume verifizieren lassen.
Auch aus ökonomischer Perspektive klaffe eine Lücke. Betrachtet man die Kapitalverteilung, also das Gesamteinkommen pro Berufsfeld, bleiben gerade die wirtschaftlich wertvollsten Bereiche wie Management und Recht in den Benchmarks unterrepräsentiert. Gleichzeitig werden schlecht bezahlte, arbeitsintensive Bereiche wie persönliche Dienstleistungen und Pflege ebenfalls kaum berücksichtigt.
Agenten beherrschen weniger als fünf Prozent der gefragten Fähigkeiten
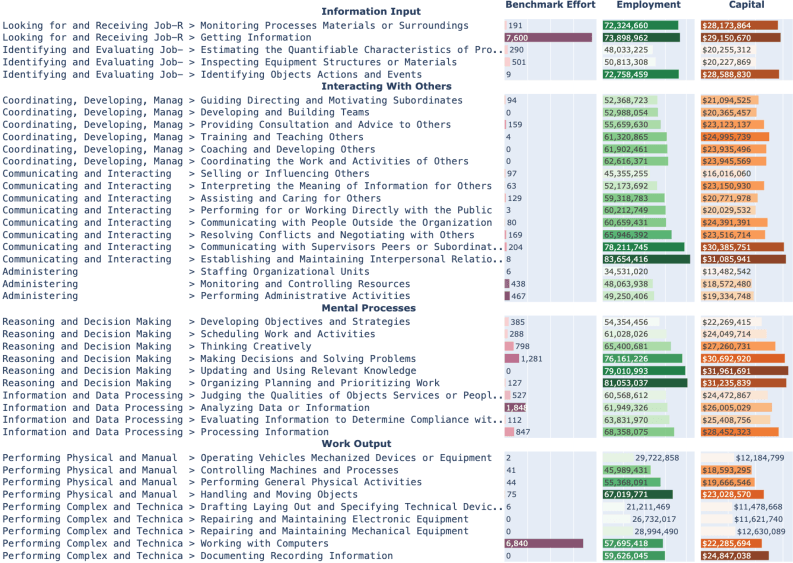
Die Schieflage zeigt sich auch auf der Ebene einzelner Fähigkeiten. Die Forscher entwickelten eine Taxonomie, die berufliche Kompetenzen in vier Kategorien aufteilt: Informationsaufnahme, mentale Prozesse, Interaktion mit anderen und Arbeitsergebnisse. In der realen Arbeitswelt verteilen sich die benötigten Fähigkeiten relativ gleichmäßig über alle Kategorien.
Die Agenten-Benchmarks konzentrieren sich dagegen auf zwei bestimmte Fähigkeiten: "Getting Information" und "Working with Computers". Zusammen decken diese weniger als fünf Prozent der US-Beschäftigung ab. Die Kategorie "Interacting with Others", die einen großen Teil realer Berufe durchzieht, kommt in den Benchmarks kaum vor.
Die Forscher führen diese Verzerrung auf methodische Bequemlichkeit zurück. Domänen mit leicht formulierbaren Aufgabenanweisungen und einfach überprüfbaren Ergebnissen würden überproportional bevorzugt. Während dies schnelle methodische Fortschritte in Nischenbereichen gebracht habe, riskiere es, die Agenten-Entwicklung von den Bereichen wegzulenken, in denen der gesellschaftliche und wirtschaftliche Nutzen am größten wäre.
Positiv heben die Forscher OpenAIs Benchmark GDPval hervor: Trotz seines vergleichsweise geringen Umfangs decke er die höchste Bandbreite an Berufsdomänen und Fähigkeiten ab. OpenAI hatte den Benchmark 2025 explizit ins Leben gerufen, um die Auswirkungen von KI-Agenten auf die reale Wissensarbeit möglichst domänenübergreifend besser messbar zu machen.
Autonomie sinkt mit steigender Aufgabenkomplexität rapide
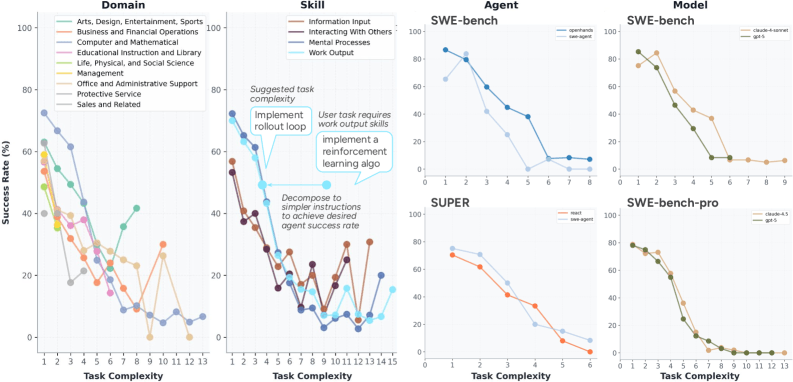
Um zu verstehen, wie selbstständig KI-Agenten innerhalb der abgedeckten Arbeitsbereiche tatsächlich agieren können, entwickelten die Forscher ein quantifizierbares Autonomiemaß. Sie definieren Autonomie als die maximale Aufgabenkomplexität, die ein Agent mit einer vordefinierten Erfolgsquote bewältigen kann. Die Komplexität einer Aufgabe bemessen sie anhand der Anzahl notwendiger Arbeitsschritte in einem hierarchischen Workflow.
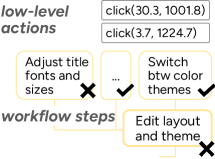
Selbst in der Softwareentwicklung, dem am stärksten vertretenen Bereich, fallen die Erfolgsraten mit steigender Aufgabenkomplexität steil ab. Agenten schneiden bei eigenständigen Tätigkeiten wie mentalen Prozessen und der Produktion von Arbeitsergebnissen am besten ab, scheitern aber beim Identifizieren und Abrufen von Informationen sowie bei der Koordination mit anderen, selbst bei vergleichsweise einfachen Aufgaben.
Auf den wenigen Benchmarks, auf denen kontrollierte Vergleiche möglich sind, etwa SWE-bench, zeigen sich laut der Studie Vorteile für das Framework OpenHands gegenüber SWE-agent und für Claude gegenüber GPT, insbesondere bei Aufgaben mittlerer Komplexität. Die Forscher weisen allerdings darauf hin, dass diese Trends sich in anderen Komplexitätsbereichen nicht unbedingt fortsetzen, und fordern eine breitere Veröffentlichung von Agenten-Trajektorien für systematischere Vergleiche.
Drei Prinzipien für bessere Benchmarks
Auf Basis ihrer Analyse formulieren die Forscher drei Gestaltungsprinzipien für zukünftige Benchmarks. Erstens sollten neue Benchmarks gezielt unterrepräsentierte, aber stark digitalisierte Domänen wie Management und Recht abdecken oder eine breite Abdeckung über Domänen und Fähigkeiten hinweg anstreben.
Zweitens sollten Benchmarks realistischer und komplexer werden. Viele automatisch synthetisierte Benchmarks bilden laut der Analyse nur vereinfachte Bruchstücke realer Arbeit ab. Von Menschen erstellte Aufgaben, etwa in den Benchmarks GDPval oder TheAgentCompany, beziehen dagegen diverse Domänen und Fähigkeiten ein. Wenn Synthese aus Skalierungsgründen notwendig sei, sollte die Aufgabengenerierung auf realistischen Domänen- und Fähigkeitskompositionen basieren.
Drittens plädieren die Forscher für eine feingliedrigere Evaluation. Wer nur misst, ob ein Agent eine Aufgabe am Ende vollständig gelöst hat, übersieht, wo genau er scheitert. Stattdessen schlagen die Forscher vor, aus menschlichen Demonstrationen automatisch Workflows abzuleiten und so Zwischencheckpoints zu erzeugen, die ein differenzierteres Bild der Agentenleistung liefern.
Die Studie stellt ein Framework und ergänzende Ressourcen bereit, die Benchmark-Designern helfen sollen, Lücken in der Arbeitsabdeckung zu identifizieren, Agenten-Entwicklern, Verbesserungsbereiche zu erkennen, und Nutzern, den passenden Autonomiegrad für ihre spezifische Aufgabe zu wählen.
Vor kurzem hatte bereits eine Analyse von Anthropic auf Basis von Millionen realer Mensch-Agent-Interaktionen gezeigt, dass knapp 50 Prozent aller agentischen Tool-Aufrufe über die öffentliche API auf Software-Entwicklung entfallen, während andere Branchen jeweils nur wenige Prozentpunkte ausmachen. Anthropic sprach von den "frühen Tagen der Agenten-Adoption".
Eine Studie der UC Berkeley und weiterer Partner kam Ende 2025 zu einem ähnlichen Befund: In der Praxis setzen Unternehmen KI-Agenten überwiegend als einfache, stark kontrollierte Werkzeuge mit wenigen autonomen Schritten ein. Die größte Hürde bleibt die Zuverlässigkeit der Systeme.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.