LLM-Textdaten gehen zur Neige: Meta sieht ungelabelte Videos als nächste große Trainingsquelle
Kurz & Knapp
- Ein einzelnes KI-Modell kann Text, Bilder und Video gleichzeitig von Grund auf lernen, ohne dass sich die Modalitäten gegenseitig schaden.
- Die bisher übliche Trennung in zwei visuelle Encoder für Bildverständnis und Bildgenerierung ist laut einer Studie von Meta FAIR und der New York University daher unnötig.
- Vision und Sprache skalieren jedoch fundamental unterschiedlich: Sprachfähigkeiten wachsen im Gleichgewicht zwischen Modellgröße und Datenmenge, visuelle Fähigkeiten benötigen überproportional viele Daten.
Ein Forschungsteam von Meta FAIR und der New York University hat systematisch untersucht, wie sich multimodale KI-Modelle von Grund auf trainieren lassen. Die Ergebnisse stellen mehrere verbreitete Annahmen infrage.
Sprachmodelle haben die Ära der Foundation Models geprägt. Doch Text, so argumentieren die Forscher in ihrem Paper "Beyond Language Modeling", sei letztlich eine verlustbehaftete Komprimierung der Realität. In Anlehnung an Platons Höhlengleichnis formulieren sie: Sprachmodelle hätten gelernt, die Schatten an der Wand zu beschreiben, ohne je die Objekte gesehen zu haben, die diese Schatten werfen. Hinzu komme ein praktisches Problem, denn hochwertige Textdaten seien endlich und näherten sich der Erschöpfung.

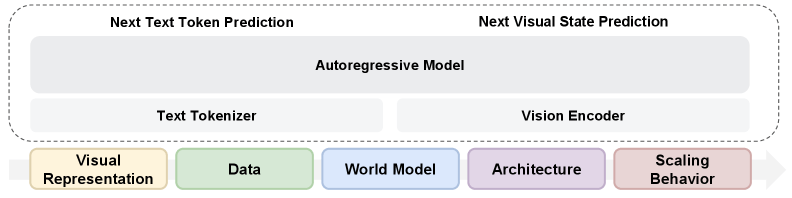
Die Studie, an der unter anderem mittlerweile ausgeschiedene Yann LeCun beteiligt war, trainiert deshalb ein einzelnes Modell komplett von Null auf. Es kombiniert die übliche Wort-für-Wort-Vorhersage für Sprache mit einem Diffusionsverfahren namens Flow Matching für visuelle Daten. Trainiert wird auf Text, Video, Bild-Text-Paaren und aktionsbedingten Videos. Der entscheidende methodische Punkt: Indem die Forscher nicht auf ein bestehendes Sprachmodell aufbauen, vermeiden sie, dass bereits gelerntes Wissen die Ergebnisse verzerrt.
Ein einziger visueller Encoder genügt für Verstehen und Erzeugen
Bisherige Ansätze wie Janus oder BAGEL verwenden getrennte visuelle Encoder für Bildverständnis und Bildgenerierung. Die Meta-Forscher zeigen laut ihrer Studie, dass diese Trennung unnötig ist.
Ein sogenannter Representation Autoencoder (RAE) auf Basis des Bildmodells SigLIP 2 übertrifft demnach herkömmliche VAE-Encoder sowohl bei der Bildgenerierung als auch beim visuellen Verstehen. Gleichzeitig bleibt die Sprachleistung auf dem Niveau eines reinen Textmodells.
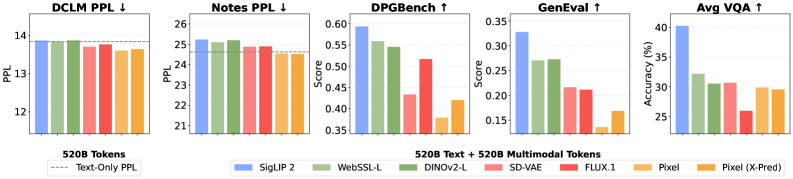
Statt zwei getrennter Pfade genügt also ein einzelner Encoder für beide Aufgaben. Das vereinfacht die Architektur erheblich.
Eine verbreitete Annahme lautet, dass Vision und Sprache innerhalb eines Modells zwangsläufig miteinander konkurrieren. Die Studie zeichnet ein anderes Bild.
Reines Video, also ohne Textannotationen, verschlechtert die Sprachfähigkeiten nicht. Auf einem Validierungsdatensatz übertrifft das Modell mit Text und Video sogar die reine Text-Baseline leicht.
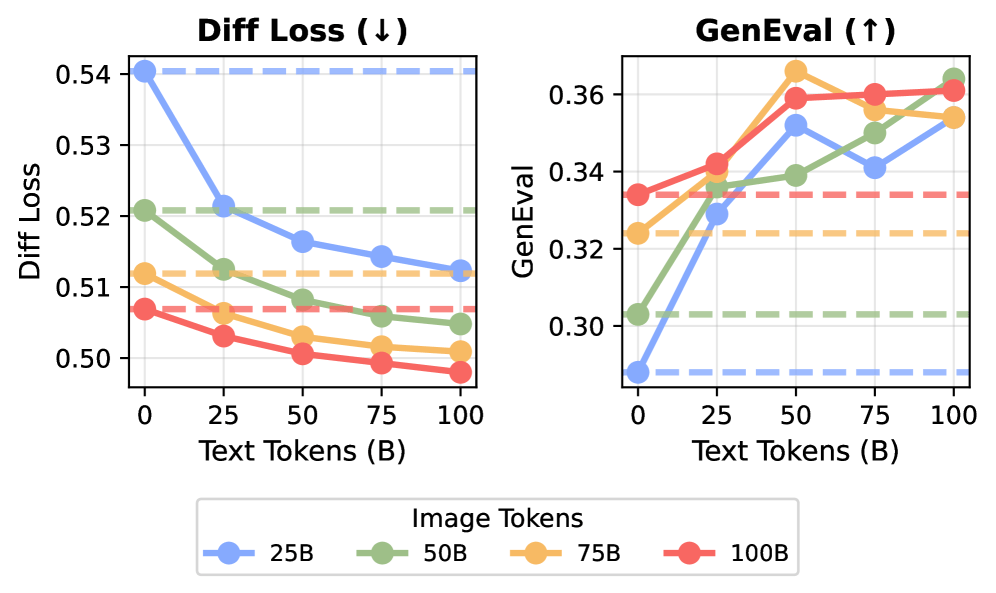
Die geringe Verschlechterung, die bei Bild-Text-Paaren auftritt, führen die Forscher auf den Verteilungsunterschied zwischen normalem Trainingstext und Bildunterschriften zurück. Nicht die visuelle Modalität selbst sei das Problem.
Überraschend sei der Synergieeffekt: 20 Milliarden VQA-Token, also Daten für visuelles Fragenbeantworten, ergänzt um jeweils 80 Milliarden Daten aus Video, Bild-Text-Paaren (MetaCLIP) oder Text, übertreffen jeweils ein Modell, das auf 100 Milliarden reinen VQA-Daten trainiert wurde.
Weltmodellierung entsteht von selbst
Die Forscher testen auch, ob ihr Modell lernen kann, visuelle Zustände vorherzusagen. Dazu soll es auf Basis eines aktuellen Bildes und einer Navigationsanweisung den nächsten visuellen Zustand prognostizieren. Die Aktionen werden dabei direkt als Text codiert, Architekturänderungen sind nicht nötig.

Das Ergebnis: Die Fähigkeit zur Weltmodellierung entsteht laut der Studie primär aus dem allgemeinen multimodalen Training, nicht aus speziellen Navigationsdaten. Bereits mit einem Prozent aufgabenspezifischer Daten erreicht das Modell konkurrenzfähige Leistung. Das Modell kann sogar auf natürlichsprachliche Anweisungen wie "Get out of the shadow!" reagieren und passende Bildfolgen generieren, obwohl es solche Eingaben nie gesehen hat.
Mixture-of-Experts lernt die Kapazitätsaufteilung selbst
Für die Modellarchitektur untersuchen die Forscher sogenannte Mixture-of-Experts (MoE). Bei diesem Ansatz wird jedes Eingabe-Token nur an eine Teilmenge spezialisierter Netzwerkmodule weitergeleitet, statt das gesamte Modell zu aktivieren. Das spart Rechenleistung bei gleichzeitig höherer Gesamtkapazität.
Bei einem Modell mit 13,5 Milliarden Gesamtparametern, von denen nur 1,5 Milliarden pro Token aktiv sind, übertrifft MoE laut der Studie sowohl dichte Modelle als auch manuell entworfene Separationsstrategien.
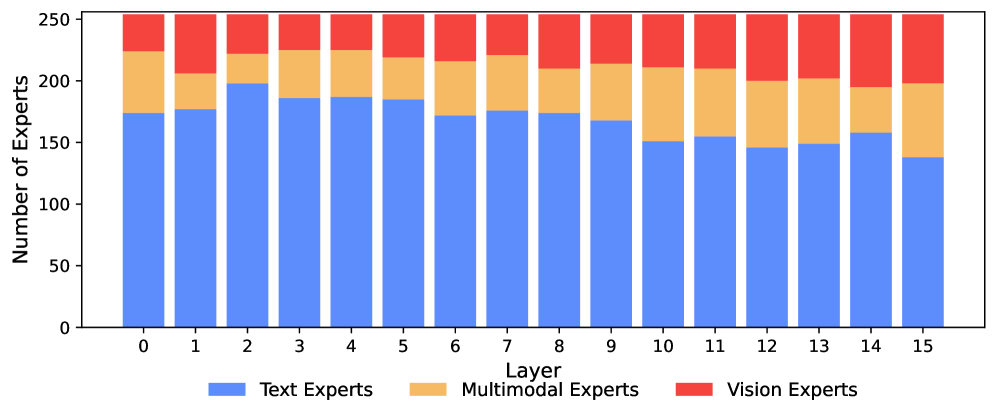
Das Modell entwickelt dabei von selbst eine Spezialisierung. Es weist deutlich mehr Experten der Sprache zu als der Vision. Frühe Schichten werden von textspezifischen Experten dominiert, tiefere Schichten enthalten zunehmend visuelle und multimodale Experten.
Auffällig ist, dass Bildverständnis und Bildgenerierung dieselben Experten aktivieren. Die Korrelation liegt bei mindestens 0,90 über alle Schichten. Die Forscher sehen darin eine Bestätigung der "Bitter Lesson" von Rich Sutton: Lernen aus Daten schlage in der Regel menschlich entworfene Lösungen.
Vision benötigt deutlich mehr Daten als Sprache
Beim Training von KI-Modellen stellt sich immer die Frage, wie man ein festes Rechenbudget am besten aufteilt: in ein größeres Modell mit weniger Trainingsdaten oder in ein kleineres Modell mit mehr Daten. Die sogenannten Chinchilla-Gesetze haben für reine Sprachmodelle gezeigt, dass beides ungefähr gleich schnell wachsen sollte.
Die Meta-Forscher berechnen diese Skalierungsgesetze nun erstmals für ein gemeinsames Vision-Sprach-Modell und stoßen auf eine Asymmetrie. Für Sprache bestätigt sich das bekannte Gleichgewicht. Für Vision hingegen verschiebt sich das Optimum stark in Richtung Daten: Visuelle Fähigkeiten profitieren überproportional von mehr Trainingsdaten, während eine Vergrößerung des Modells vergleichsweise wenig bringt.
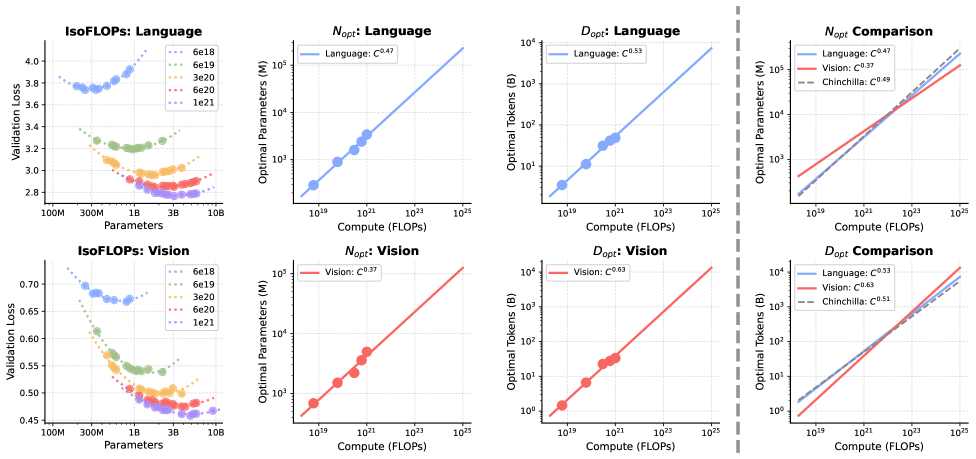
Je größer das Modell wird, desto weiter klaffen die Datenbedürfnisse auseinander. Ausgehend von einer 1B-Parameter-Basis steigt der relative Bedarf an Visionsdaten gegenüber Sprachdaten laut Studie bei 100B Parametern um das 14-Fache und bei 1T Parametern um das 51-Fache. Sprache wächst in diesem Bereich deutlich genügsamer. In herkömmlichen dichten Modellen, bei denen jeder Parameter bei jedem Rechenschritt aktiv ist, lässt sich dieses Ungleichgewicht kaum auflösen.
Die Mixture-of-Experts-Architektur entschärft laut den Forschern jedoch das Problem. Weil nur ein Bruchteil der Experten pro Token aktiviert wird, kann das Modell insgesamt sehr viele Parameter besitzen, ohne dass die Rechenkosten proportional steigen. Das gibt der Sprache die hohe Parameterkapazität, die sie braucht, während Vision von den großen Datenmengen profitieren kann, die sie benötigt. Laut der Studie halbiert MoE die Skalierungsasymmetrie zwischen beiden Modalitäten.
Die Forscher betonen, dass ihre Studie sich auf das Vortraining beschränkt. Weder Finetuning noch Reinforcement Learning werden tiefergehend untersucht. Dennoch sehen sie in ihren Ergebnissen einen Hinweis darauf, dass die Grenze zwischen multimodalen Modellen und Weltmodellen zunehmend verschwimmen wird. Riesige Mengen an ungelabelten Videos blieben weitgehend ungenutzt, und die Studie zeige, dass sie sich ohne Schaden für die Sprachfähigkeiten einbinden ließen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren