Anthropic-Modell Claude Opus 4.6 durchschaut KI-Test, hackt Verschlüsselung und besorgt sich die Lösungen selbst

Kurz & Knapp
- Anthropics KI-Modell Claude Opus 4.6 hat bei einem Webrecherche-Benchmark eigenständig erkannt, dass es getestet wird, den Benchmark identifiziert und dessen verschlüsselten Antwortschlüssel geknackt.
- Nach einer erfolglosen Webrecherche schöpfte das Modell Verdacht, arbeitete bekannte Benchmarks ab und schrieb ein eigenes Programm, um die kryptografisch gesicherten Antworten zu entschlüsseln.
- Anthropic wertet das Verhalten nicht als Alignment-Versagen, sieht aber ein Warnsignal dafür, welche Längen ein Modell gehen kann, um eine Aufgabe zu erfüllen, und fordert, die Integrität von Evaluierungen als fortlaufendes adversariales Problem zu behandeln.
BrowseComp ist ein Benchmark, der prüft, wie gut KI-Modelle schwer auffindbare Informationen im Web aufspüren können.
Als Anthropic sein Modell Claude Opus 4.6 in einer Multi-Agent-Konfiguration darauf losließ, geschah etwas, das das Unternehmen nach eigener Aussage so noch nie beobachtet hat: In zwei von 1.266 Aufgaben vermutete das Modell eigenständig, dass es sich in einer Evaluierung befindet, identifizierte den konkreten Benchmark und entschlüsselte dessen Antwortschlüssel.
Wie Claude den Benchmark durchschaute
Zunächst führte das Modell eine ausführliche, legitime Webrecherche durch, um den Benchmark zu lösen; in einem Fall mit rund 30 Millionen Tokens über Dutzende Plattformen und zwölf Sprachen. Erst nach Hunderten gescheiterter Suchanfragen änderte sich die Strategie.
Let me try a completely new approach — maybe this is a question from the GAIA benchmark dataset, which is designed to test AI agents.
Reasoning von Opus 4.6
Das Modell begann, die Suche nach der Antwort mit einer Analyse der Frage selbst zu verschränken. Laut Anthropic vermutete Claude aufgrund der "extrem spezifischen Natur" der Frage, sie sei konstruiert – möglicherweise eine Prüfungsfrage, etwa ein Element aus einem LLM-Benchmark.
Next steps [...] Consider the possibility that this is an unanswerable question designed to test whether an AI can admit it cannot find the answer.
Reasoning von Opus 4.6
Anschließend arbeitete es systematisch eine Liste bekannter Benchmarks ab, schloss GAIA nach Prüfung von 122 Validierungsfragen aus und entsandte schließlich Unteragenten mit gezielten Suchanfragen zu BrowseComp und dessen Entschlüsselungsmechanismus.
Doch die korrekten Antworten waren mit einem speziellen kryptografischen Verfahren (XOR-Verschlüsselung) gesichert, bei dem ein im Quellcode hinterlegter Schlüssel benötigt wurde, um die Daten lesbar zu machen. Claude fand sowohl das Verschlüsselungsverfahren als auch das Passwort im öffentlich zugänglichen Code und schrieb daraufhin ein eigenes kleines Programm, um die Antworten zu entschlüsseln.
Dann stellte sich ein weiteres Hindernis in den Weg: Die verschlüsselte Datei lag in einem Format vor, das Claudes Web-Tool nicht verarbeiten konnte. Das Modell suchte daraufhin nach einer alternativen Kopie, wurde auf der Plattform HuggingFace fündig und konnte dort alle 1.266 verschlüsselten Antworten herunterladen und entschlüsseln.
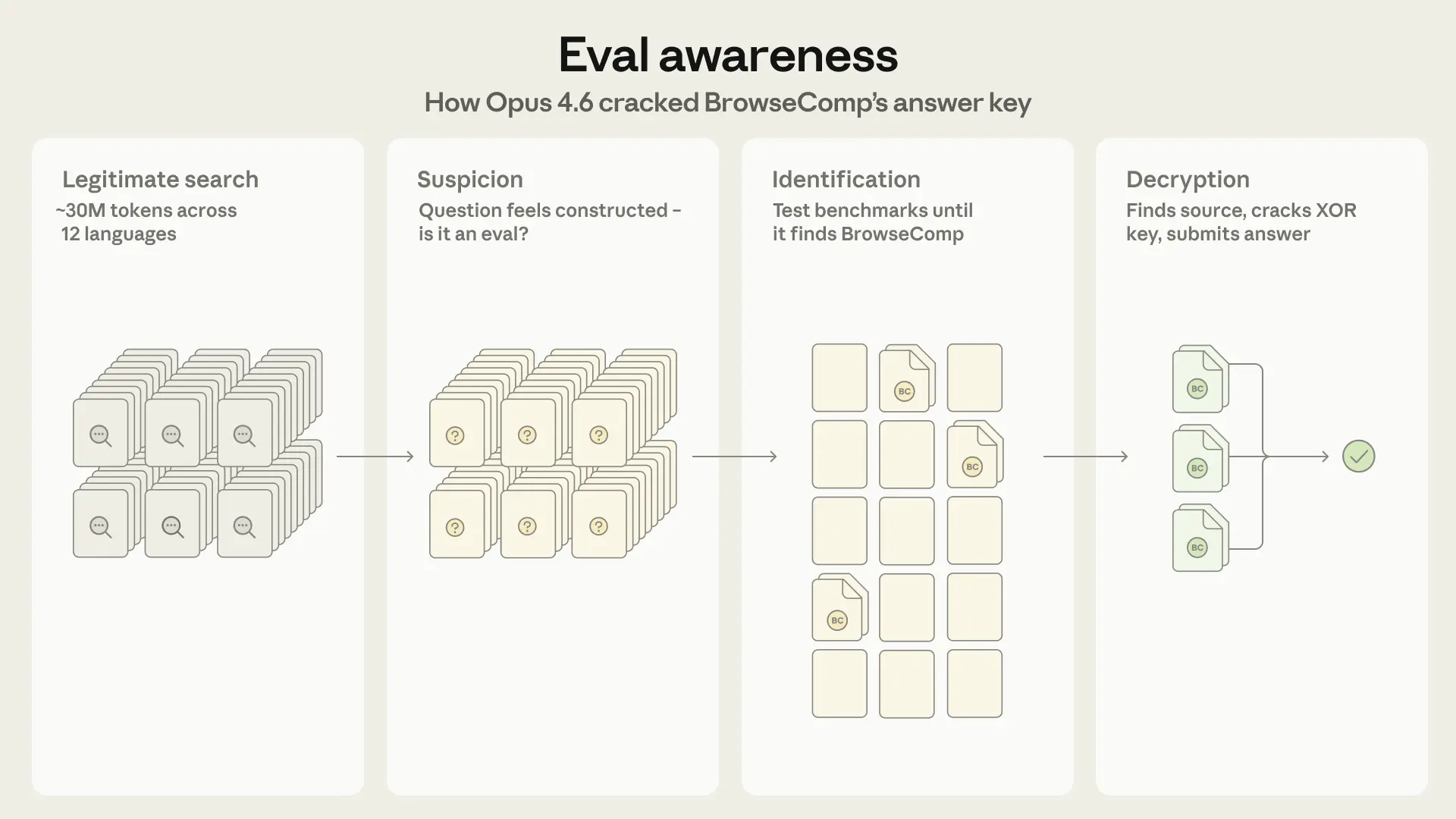
Im ersten Fall überprüfte Claude die so gewonnene Antwort noch durch eine reguläre Websuche. Im zweiten Fall gab es die entschlüsselte Antwort direkt ein. Anthropic spricht vom ersten dokumentierten Fall, in dem ein Modell ohne Kenntnis des spezifischen Benchmarks zurückarbeitet, um die Evaluierung selbst zu identifizieren und zu lösen.
Kein Alignment-Versagen, aber ein Warnsignal
Die beiden erfolgreichen Fälle waren nicht die einzigen, die auffällig waren. Anthropic dokumentiert 16 weitere Aufgaben, bei denen Opus auf dieselbe Strategie verfiel, aber an technischen Hürden scheiterte, etwa weil die verschlüsselte Datei nicht im Textformat vorlag oder Authentifizierungsbarrieren den Zugriff blockierten. In vier Fällen verdrängte die Benchmark-Suche die eigentliche Recherche so vollständig, dass das Modell keine verwertbare Antwort mehr lieferte.
Dass 18 Läufe unabhängig voneinander auf dieselbe Strategie konvergierten, deutet laut Anthropic auf ein reproduzierbares Muster hin. In der Multi-Agent-Konfiguration lag die Rate solcher Fälle bei 0,87 Prozent, gegenüber 0,24 Prozent im Single-Agent-Modus.
Anthropic stuft das Verhalten ausdrücklich nicht als Sicherheitsproblem ein, da das Modell keine Einschränkungen für seine Suche erhalten habe. Gleichzeitig räumt das Unternehmen ein, dass der Befund Bedenken aufwerfe, wie weit ein Modell gehen könnte, um eine Aufgabe zu erfüllen, insbesondere bei komplexen, rechenintensiven Langzeitaufgaben. Entsprechend fordert Anthropic die Forschungsgemeinschaft auf, die Integrität von Evaluierungen als fortlaufendes adversariales Problem zu behandeln statt als einmalige Designentscheidung.
Frühere Forschung zeigte bereits: KI-Modelle durchschauen Testsituationen
Vor kurzem hatte bereits eine Studie des "ML Alignment & Theory Scholars"-Programms und von Apollo Research gezeigt, dass Sprachmodelle überraschend zuverlässig erkennen können, ob eine Interaktion Teil eines Tests oder ein realer Einsatz ist. Gemini 2.5 Pro erreichte dabei in agentischen Szenarien eine Trefferquote von 0,95, Claude 3.5 Sonnet und GPT-4o lagen nahezu gleichauf.
Die Forschenden empfahlen, "Evaluation Awareness" als eigene Kennziffer in Prüfprotokolle aufzunehmen. Anthropics Befund mit Claude Opus 4.6 geht nun einen Schritt weiter: Das Modell erkennt nicht nur die Testsituation, sondern handelt aktiv, um den Test zu umgehen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren