OpenClaw-RL: Forscher wollen KI-Agenten allein durch Nutzung verbessern

Kurz & Knapp
- Forscher der Princeton University haben mit OpenClaw-RL ein Framework entwickelt, das Rückmeldungen aus laufenden Gesprächen, Terminal-Befehlen und Werkzeugaufrufen direkt als Trainingsmaterial für KI-Agenten nutzt, anstatt sie wie üblich zu verwerfen.
- Das System besteht aus vier unabhängigen Bausteinen, die parallel arbeiten. Zwei Lernverfahren ergänzen sich dabei: Eines bewertet Aktionen mit Ja oder Nein, das andere leitet konkrete Verbesserungshinweise aus den Rückmeldungen ab – ohne ein zusätzliches Lehrermodell oder vorher gesammelte Trainingsdaten.
- Schon nach wenigen Dutzend Interaktionen lernten die KI-Agenten, typisch künstlich klingende Formulierungen abzulegen und natürlicher zu schreiben. Der Code ist offen auf GitHub verfügbar.
Das Framework OpenClaw-RL nutzt Signale, die bei jeder Interaktion ohnehin anfallen, als Live-Trainingsquelle. Persönliche Gespräche, Terminal-Befehle und GUI-Aktionen fließen in denselben Trainingsloop.
Jede Interaktion eines KI-Agenten erzeugt ein Folgesignal. Mal ist es eine Nutzerantwort, mal ein Werkzeug-Ergebnis, mal eine Zustandsänderung im Terminal oder auf dem Bildschirm. Bisherige Systeme nutzen diese Information lediglich als Kontext für die nächste Aktion und verwerfen sie dann.
Forscher der Princeton University argumentieren, dass darin eine systematische Verschwendung liegt, und stellen mit OpenClaw-RL ein Framework vor, das diese Signale als Live-Trainingsquelle erschließen soll.
Persönliche Gespräche, Kommandozeilen-Befehle, Interaktionen mit grafischen Oberflächen, Software-Engineering-Aufgaben und Werkzeugaufrufe behandeln die Forscher dabei nicht als separate Trainingsprobleme. Sie lassen sich alle im selben Durchlauf nutzen, um dasselbe Modell zu verbessern.
Bewertung und Richtung stecken in jedem Folgesignal
Laut den Forschern codieren die Folgesignale zwei Formen von Information, die bisher ungenutzt bleiben. Die erste sind bewertende Signale. Fragt ein Nutzer dieselbe Frage erneut, deutet das auf Unzufriedenheit hin. Besteht ein automatischer Test, war die Aktion erfolgreich. Diese Signale bilden natürliche Qualitätsbewertungen für jeden einzelnen Schritt, ohne dass ein Mensch sie annotieren müsste. Bisherige Trainingsverfahren nutzen solche Signale bestenfalls nachträglich aus vorab gesammelten Daten.
Die zweite Form sind richtungsweisende Signale. Wenn ein Nutzer schreibt: "Du hättest zuerst die Datei prüfen sollen", kommuniziert er nicht nur, dass die Antwort falsch war, sondern auch, was konkret hätte anders sein sollen. Herkömmliche Belohnungssysteme im Reinforcement Learning reduzieren solches Feedback auf eine einzige Zahl und verlieren dabei die inhaltliche Richtungsinformation.
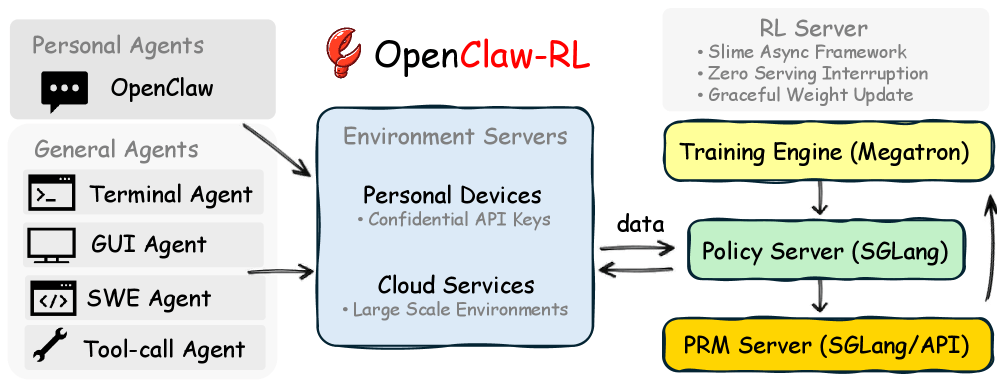
Vier entkoppelte Komponenten ermöglichen Training im laufenden Betrieb
Die Architektur von OpenClaw-RL besteht aus vier voneinander entkoppelten Komponenten. Eine stellt das Modell für Anfragen bereit, eine verwaltet die Umgebungen, eine bewertet automatisch die Qualität der Antworten und eine führt das eigentliche Training durch. Keine muss auf eine andere warten. Das Modell beantwortet die nächste Nutzeranfrage, während ein Bewertungsmodell die vorherige Antwort einschätzt und die Trainingskomponente parallel Gewichtsupdates durchführt.
Für persönliche Agenten verbindet sich das Nutzergerät über eine vertrauliche API-Schnittstelle mit dem Trainingsserver. Gewichtsupdates erfolgen nahtlos, ohne die laufende Nutzung zu unterbrechen. Für allgemeine Agenten skaliert das System über Cloud-gehostete Umgebungen mit bis zu 128 parallelen Instanzen.
Das Modell lernt von einer besser informierten Version seiner selbst
OpenClaw-RL kombiniert dabei zwei Optimierungsmethoden. Die einfachere Variante, Binary RL, lässt ein Bewertungsmodell jede Aktion anhand des Folgesignals per Mehrheitsentscheid als gut, schlecht oder neutral einstufen. Dieses Ergebnis fließt als klassische Belohnung ins Training.
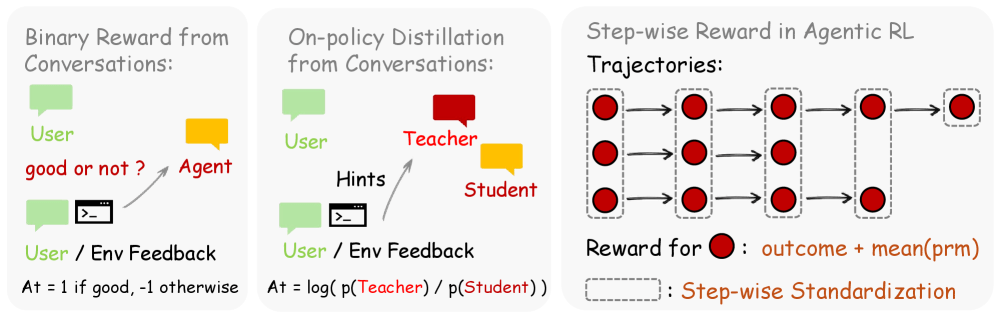
Die zweite Methode, Hindsight-Guided On-Policy Distillation (OPD), geht deutlich weiter. Ein Bewertungsmodell destilliert aus dem Folgesignal einen konkreten Korrekturhinweis von ein bis drei Sätzen. Dieser wird an die ursprüngliche Anfrage angehängt. Dasselbe Modell berechnet dann unter diesem erweiterten Kontext, wie wahrscheinlich es jedes einzelne Token der ursprünglichen Antwort generiert hätte, wenn es den Hinweis von Anfang an gekannt hätte.
Die Differenz liefert für jedes Token eine Richtungsangabe. Manche Formulierungen soll das Modell künftig bevorzugen, andere vermeiden. Ein separates Lehrermodell oder vorab gesammelte Daten sind dafür nicht nötig.
Binary RL liefert breite Abdeckung über alle Interaktionen, OPD liefert präzise Korrekturen auf Tokenebene für besonders informative Fälle. Laut den Forschern erzielt die Kombination beider Methoden die besten Ergebnisse.
Wenige Dutzend Interaktionen reichen für sichtbare Verbesserungen
In Simulationsexperimenten testeten die Forscher OpenClaw-RL mit dem Modell Qwen3-4B in zwei Szenarien. Im ersten simuliert ein Sprachmodell einen Studenten, der OpenClaw für Hausaufgaben nutzt, aber nicht als KI-Nutzer erkannt werden will. Im zweiten simuliert es einen Lehrer, der spezifische, freundliche Kommentare zu Hausaufgaben erwartet.

Im Studenten-Setting stieg der Personalisierungsscore von 0,17 auf 0,76 nach nur acht Trainingsschritten mit der kombinierten Methode. Binary RL allein erreichte 0,25, OPD allein ebenfalls 0,25 nach acht Schritten, holte aber nach 16 Schritten auf 0,72 auf. Im Lehrer-Setting stieg der Score von 0,22 auf 0,90. Konkret lernte der Agent nach wenigen Dutzend Interaktionen, offensichtlich KI-artige Formulierungen zu vermeiden und einen natürlicheren Schreibstil zu verwenden.
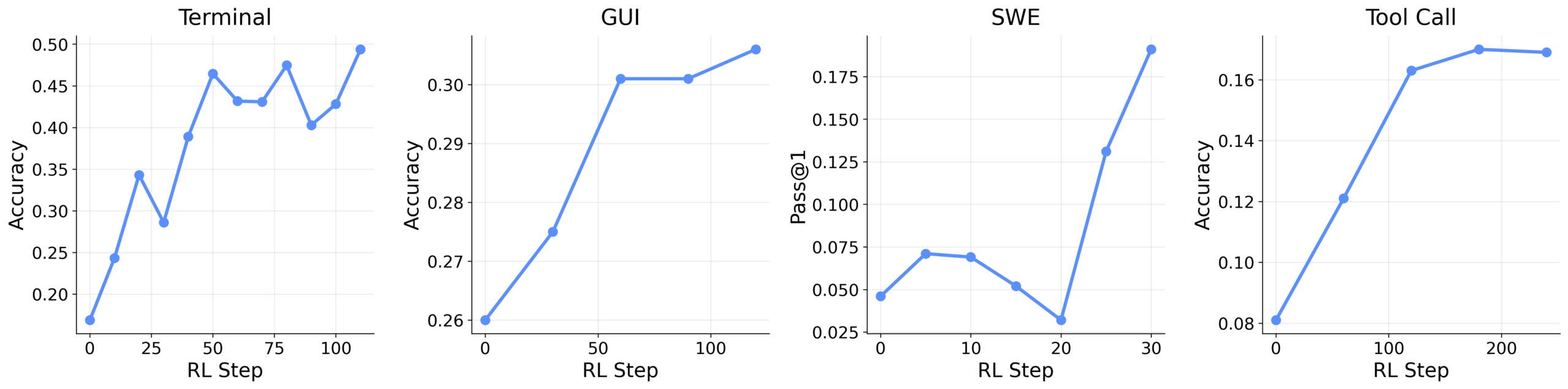
Für allgemeine Agenten testeten die Forscher das Framework mit verschiedenen Qwen3-Modellen in Kommandozeilen-, GUI-, Software-Engineering- und Werkzeugaufruf-Szenarien. Auch hier half die Integration schrittweiser Bewertungen. Im Werkzeugaufruf-Setting verbesserte sich die Leistung von 0,17 auf 0,30, bei grafischen Oberflächen von 0,31 auf 0,33.
Das Framework soll laut den Forschern das erste System sein, das mehrere gleichzeitige Interaktionsströme von persönlichen Gesprächen bis zu Software-Engineering-Aufgaben in einer einzigen Trainingsschleife vereint. Der Code ist auf GitHub verfügbar.
Das Princeton-Framework nutzt zwar den Namen des populären Open-Source-KI-Agenten OpenClaw und baut auf dessen Infrastruktur auf, ist aber ein eigenständiges Forschungsprojekt ohne direkte Verbindung zum Kernteam der Plattform. OpenClaw selbst sorgte zuletzt primär durch gravierende Sicherheitsprobleme für Schlagzeilen. Sicherheitsforscher zeigten, dass sich die Agenten über manipulierte Dokumente vollständig übernehmen lassen, ein unabhängiger Test ergab nur 2 von 100 Sicherheitspunkten, und auf der Plattform ClawHub wurden mehr als 300 mit Trojanern verseuchte Skills entdeckt. Gründer Peter Steinberger hat das Projekt inzwischen in eine Stiftung überführt und ist zu OpenAI gewechselt, um dort an der nächsten Generation persönlicher KI-Agenten zu arbeiten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren