xAIs Grok 4.20 hängt in Benchmarks zurück und glänzt dennoch mit niedrigster Halluzinationsrate
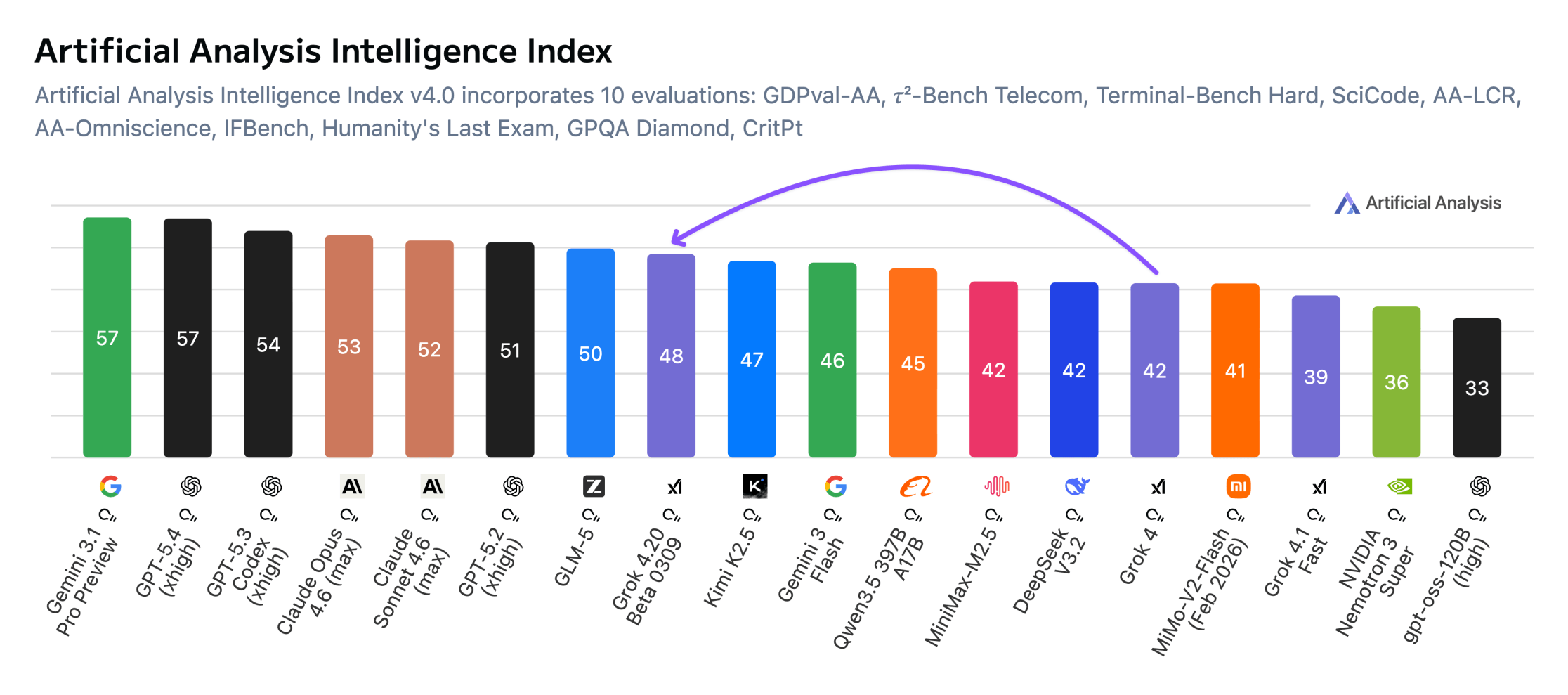
xAIs aktuelles KI-Modell Grok 4.20 hängt in Benchmarks deutlich hinterher. Das zeigt die Auswertung von Artificial Analysis, einem unabhängigen Bewertungsdienst für KI-Modelle. Grok 4.20 Beta erreicht mit aktiviertem Reasoning-Modus 48 Punkte im Artificial Analysis Intelligence Index – die Spitzenmodelle Gemini 3.1 Pro Preview und GPT-5.4 liegen bei 57 Punkten. Gegenüber dem Vorgänger Grok 4 ist das dennoch ein Plus von 6 Punkten.
xAI veröffentlichte drei Varianten in der API: mit Reasoning, ohne Reasoning und einen Multi-Agenten-Modus. Das Modell bietet ein Kontextfenster von 2 Millionen Token und ist mit 2 bzw. 6 Dollar pro Million Token günstiger als Grok 4 und recht günstig für westliche Modelle.
Eine Stärke hat das Modell allerdings: Es erfindet so selten falsche Antworten wie kein anderes getestetes Modell. Im AA-Omniscience-Test erreicht Grok 4.20 eine Nicht-Halluzinationsrate von 78 Prozent, laut Artificial Analysis ein Rekordwert. Der Test prüft, wie oft ein Modell etwas Falsches behauptet, wenn es die Antwort eigentlich nicht kennt. Grok 4.20 gibt in solchen Fällen nur etwa bei jeder fünften Frage trotzdem eine (falsche) Antwort.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren