KI-Agent "MetaClaw" checkt erst deinen Google-Kalender, bevor er trainiert

Kurz & Knapp
- MetaClaw ist ein Framework, das KI-Agenten im laufenden Betrieb aus eigenen Fehlern lernen lässt. Scheitert der Agent an einer Aufgabe, wird automatisch eine Verhaltensregel abgeleitet und sofort in den Prompt eingefügt. Parallel werden die Modellgewichte per Reinforcement Learning in Ruhephasen aktualisiert.
- Damit das Training nicht stört, prüft ein Hintergrundprozess den Google-Kalender, Tastaturaktivität und Schlafenszeiten des Nutzers. Sitzt dieser etwa in einem Meeting, startet das System ein Trainingsfenster.
- Im Test hebt das Framework ein schwächeres Sprachmodell fast auf das Niveau eines deutlich stärkeren. Die Forscher räumen aber ein, dass der Benchmark simuliert ist und sich nicht direkt auf den Produktionseinsatz übertragen lässt.
Forscher aus vier US-Universitäten stellen ein Framework vor, das KI-Agenten im laufenden Betrieb verbessert. Dafür nutzt es den Google-Kalender des Nutzers.
Die meisten KI-Agenten auf Basis großer Sprachmodelle werden einmal trainiert und dann unverändert eingesetzt. Die Aufgaben und Anforderungen der Nutzer verändern sich aber ständig, das Modell passt sich nicht an.
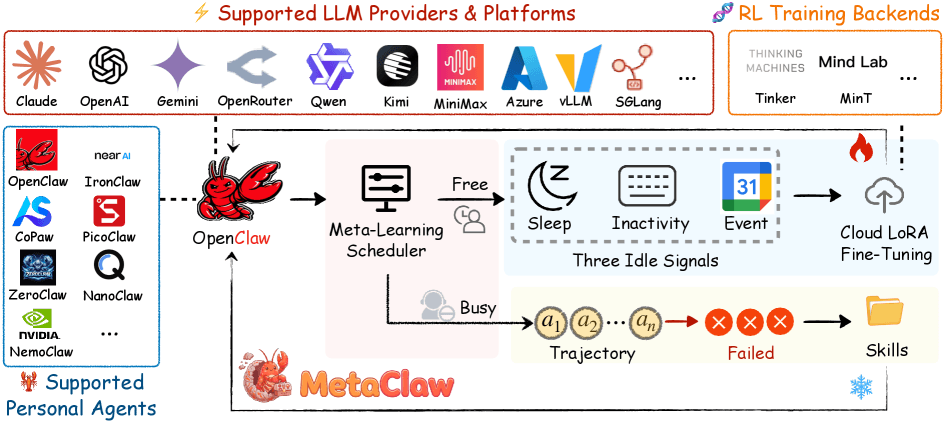
Forscher der UNC-Chapel Hill, Carnegie Mellon University, UC Santa Cruz und UC Berkeley wollen dieses Problem mit MetaClaw lösen, einem Framework, das einen KI-Agenten kontinuierlich aus seinen eigenen Fehlern verbessert, größtenteils ohne dass der Nutzer etwas davon mitbekommt oder der Service unerreichbar ist.
Aus Fehlern werden neue Verhaltensregeln
Der erste Mechanismus greift, sobald der Agent an einer Aufgabe scheitert. Dann analysiert ein separates Sprachmodell die gescheiterte Interaktion und leitet daraus eine kompakte Verhaltensregel ab. Diese wird direkt in den System-Prompt des Agenten eingefügt und gilt ab sofort für alle folgenden Aufgaben. Das Modell selbst wird dabei nicht verändert, es gibt keine Unterbrechung des Dienstes.
Laut dem Paper entstehen so vor allem drei Typen von Regeln: Zeitformate korrekt normalisieren, vor zerstörerischen Dateioperationen ein Backup anlegen und Namenskonventionen einhalten. Weil solche Regeln nicht an eine einzelne Aufgabe gebunden sind, kann ein einziger Fehler Verbesserungen bei strukturell ganz anderen Folgeaufgaben bewirken.
System checkt freie Zeitfenster
Der zweite Mechanismus aktualisiert die Modellgewichte per Reinforcement-Learning über Cloud-basiertes LoRA-Feintuning. Da ein solches Update den Agenten kurzzeitig unterbricht, darf es nicht während aktiver Nutzung laufen.
Dafür haben die Forscher einen Hintergrundprozess namens OMLS (Opportunistic Meta-Learning Scheduler) entwickelt, der drei Signale überwacht: konfigurierbare Schlafenszeiten, Tastatur- und Maus-Inaktivität auf Betriebssystemebene sowie die Belegung des Google-Kalenders. Sitzt der Nutzer laut Kalender in einem Meeting, öffnet sich ein Trainingsfenster. Der Trainer kann pausieren und fortsetzen, sodass auch kurze Inaktivitätsphasen nutzbar sind.
Das System unterscheidet strikt zwischen Daten, die vor einer Regelanpassung gesammelt wurden, und solchen danach. Nur letztere fließen ins Training ein. Andernfalls würde das Modell für Fehler bestraft, die die neue Verhaltensregel bereits behoben hat.
Beide Mechanismen verstärken sich laut den Forschern gegenseitig: Ein besseres Modell produziert aufschlussreichere Fehler, aus denen sich bessere Regeln ableiten lassen. Bessere Regeln wiederum erzeugen hochwertigere Trainingsdaten für die nächste Gewichtsaktualisierung.
Schwächeres Modell schließt fast zum stärkeren auf
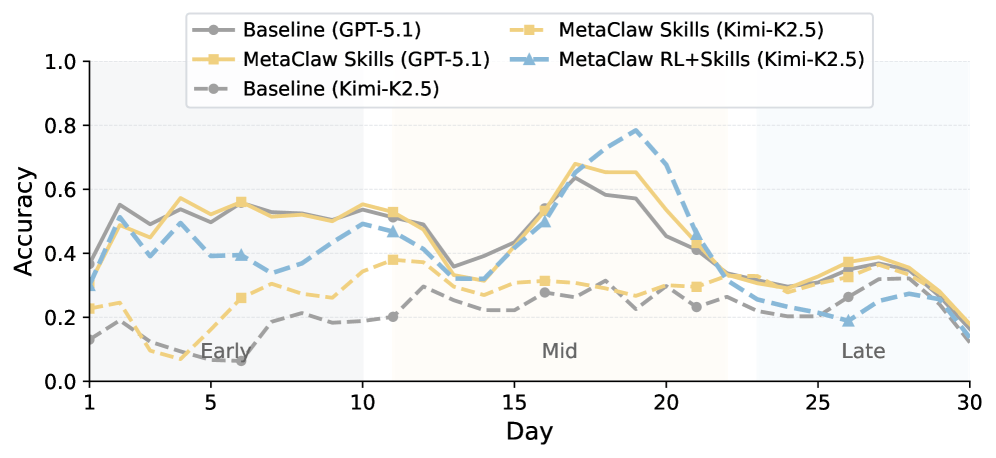
Die Forscher evaluieren MetaClaw auf einem eigens entwickelten Benchmark mit 934 Fragen über 44 simulierte Arbeitstage, getestet mit GPT-5.2 und Kimi-K2.5. Die Verhaltensregeln allein verbessern die Genauigkeit von Kimi-K2.5 um bis zu 32 Prozent relativ. Das vollständige Framework hebt Kimi-K2.5 von 21,4 auf 40,6 Prozent und erreicht damit fast das GPT-5.2-Ausgangsniveau von 41,1 Prozent. Die Rate vollständig gelöster Aufgaben steigt um den Faktor 8,25.
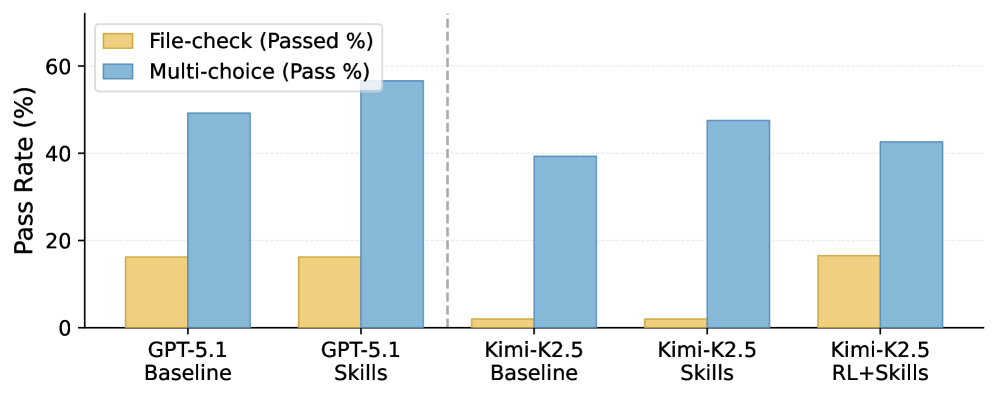
Das Muster ist laut dem Paper konsistent: Schwächere Modelle profitieren deutlich stärker, weil ihnen prozedurales Wissen fehlt, das die Regel-Bibliothek explizit bereitstellt. GPT-5.2 startet bereits von einem höheren Niveau und hat weniger Spielraum nach oben.
Um zu prüfen, ob MetaClaw auch außerhalb von CLI-Aufgaben funktioniert, setzen die Forscher das Framework zusätzlich in AutoResearchClaw ein. Diese Pipeline durchläuft autonom 23 Schritte, von der Literaturrecherche über Experimente bis zum fertigen Paper. Allein durch die eingespeisten Verhaltensregeln, ohne jedes Modell-Training, sinkt die Wiederholungsrate einzelner Schritte um 24,8 Prozent und die Zahl der Verfeinerungszyklen um 40 Prozent.
Simulierter Benchmark mit Einschränkungen
Die Forscher räumen ein, dass ihr Benchmark eine Simulation ist und keine echten Nutzersitzungen abbildet. Die absoluten Zahlen seien daher nicht direkt auf Produktionsumgebungen übertragbar. Zudem hängt die Erkennung inaktiver Zeitfenster von der Konfiguration des Nutzers ab. Der Code ist auf GitHub verfügbar. MetaClaw benötigt keine lokale GPU und arbeitet über eine Proxy-Architektur mit Cloud-Endpunkten.
Erst kürzlich stellten Forscher der Princeton University mit OpenClaw-RL ein verwandtes Framework vor, das ebenfalls KI-Agenten im laufenden Betrieb verbessern soll. OpenClaw-RL nutzt dafür Folgesignale aus jeder Interaktion, etwa Nutzerantworten oder Testergebnisse, als Live-Trainingsquelle. MetaClaw baut auf der OpenClaw-Infrastruktur auf, verfolgt aber einen anderen Ansatz: Statt alle Interaktionssignale direkt ins Training einfließen zu lassen, trennt es explizit zwischen schneller Regelanpassung im Prompt und verzögerter Gewichtsoptimierung in inaktiven Zeitfenstern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren