Benchmark zeigt: Wenn KI-Modellen visuelle Daten fehlen, wird einfach geraten

ProactiveBench testet, ob multimodale Sprachmodelle bei unzureichenden visuellen Informationen um Nutzerunterstützung bitten. 22 getestete Modelle zeigen kaum proaktives Verhalten, doch ein einfaches Reinforcement-Learning-Training weist einen möglichen Ausweg.
Wenn ein Mensch ein verdecktes Objekt identifizieren soll, bittet er jemanden, das Hindernis wegzuräumen. Multimodale Sprachmodelle tun das nicht. Stattdessen halluzinieren sie eine falsche Antwort oder verweigern jede Aussage. Der neue Benchmark ProactiveBench untersucht systematisch, ob aktuelle KI-Modelle in solchen Situationen gezielt um Hilfe bitten können.
Der Benchmark nutzt sieben bestehende Datensätze und verwandelt sie in Testszenarien, die ohne menschliche Hilfe nicht lösbar sind. Die Modelle sollen etwa verdeckte Objekte identifizieren, verrauschte Bilder verbessern, grobe Skizzen interpretieren oder Kamerawinkel ändern. Insgesamt umfasst ProactiveBench mehr als 108.000 Bilder in 18.000 Samples. Ein Filtermechanismus entfernt Aufgaben, die Modelle schon im ersten Anlauf lösen können. Wer bestehen will, muss proaktiv nach zusätzlichen Informationen fragen.

Größere Modelle sind nicht proaktiver
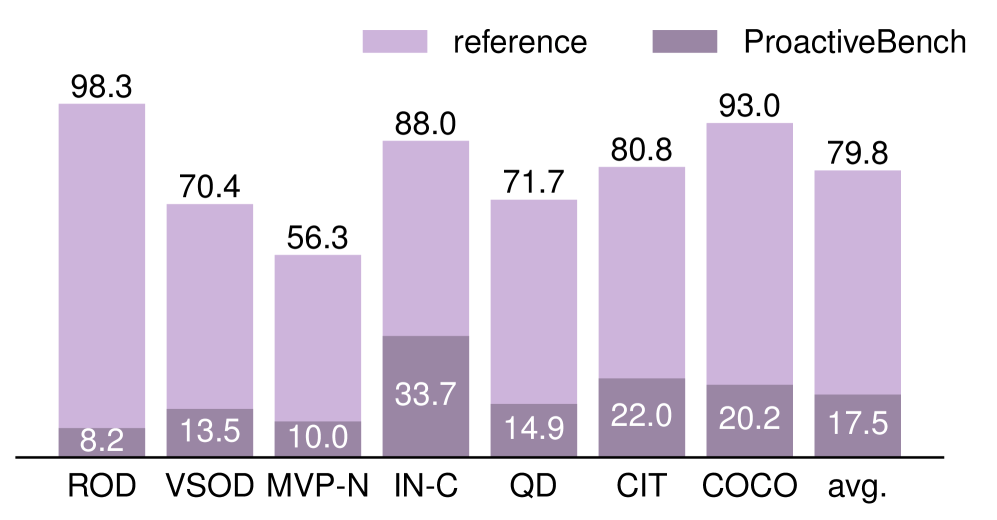
Die Forscher evaluierten laut dem Paper 22 multimodale Sprachmodelle, darunter LLaVA-OV, Qwen2.5-VL, InternVL3 sowie GPT-4.1, GPT-5.2 und o4-mini. Im Referenz-Setting mit eindeutig sichtbaren Objekten lösen die Modelle durchschnittlich 79,8 Prozent der Aufgaben. In ProactiveBench bricht die Leistung gegenüber dem Referenz-Setting um mehr als 60 Prozent ein.
Am deutlichsten zeigt sich die Kluft beim ROD-Datensatz, bei dem Objekte hinter Blöcken versteckt sind: 98,3 Prozent im Referenz-Setting stehen 8,2 Prozent gegenüber. Die Modelle erkennen die Objekte, wenn sie sichtbar sind, fragen aber nicht danach, sie freizulegen.
Einen Zusammenhang zwischen Modellgröße und Proaktivität fanden die Forscher nicht. InternVL3-1B übertrifft InternVL3-8B mit 27,1 gegenüber 12,7 Prozent. Das ältere LLaVA-1.5-7B schlägt das neuere LLaVA-OV-72B mit 24,8 gegenüber 13 Prozent. Auch das zugrunde liegende Sprachmodell macht einen Unterschied. LLaVA-NeXT mit Vicuna erreicht 19,3 Prozent, mit Mistral nur 4,5 Prozent. Geschlossene Modelle wie GPT-4.1 zeigen die beste Genauigkeit. Ihre auffällig starken COCO-Werte werten die Forscher allerdings als mögliche Datenkontamination.
Scheinbare Proaktivität ist oft nur Ratebereitschaft
Einige Modelle wirken proaktiver als andere. Die Forscher überprüften das, indem sie gültige proaktive Vorschläge durch ungültige ersetzten, etwa "Spule das Video zurück" für eine Skizzen-Aufgabe. Modelle, die zuvor proaktiv erschienen, wählen auch die sinnlosen Vorschläge. LLaVA-NeXT Vicuna erhöht die Wahrscheinlichkeit dafür sogar von 37 auf 49 Prozent. Die scheinbare Proaktivität spiegelt laut den Forschern eine geringere Neigung zur Enthaltung wider, kein tieferes Verständnis.

Auch explizite Hinweise in den Prompts und Konversationshistorien lösen das Problem nicht. Hinweise erhöhen zwar die Rate proaktiver Vorschläge, doch die Genauigkeit steigt zwar auf 25,8 Prozent, übertrifft das Zufallsniveau im Durchschnitt aber nicht. In 16 Prozent der Fälle wählen die Modelle blind proaktive Vorschläge bis zum Maximum erlaubter Schritte. Konversationshistorien verschlechtern die Ergebnisse sogar: Die Modelle wiederholen die proaktiven Aktionen aus der Historie, statt aus ihnen zu lernen.
Reinforcement Learning lehrt Modelle, um Hilfe zu bitten
Dass Proaktivität durch Training aber erlernbar ist, zeigen die Forscher in einem weiteren Experiment. Sie trainierten LLaVA-NeXT-Mistral-7B und Qwen2.5-VL-3B mittels Group-Relative Policy Optimization (GRPO) auf etwa 27.000 Beispielen. Die Belohnungsfunktion setzt korrekte Vorhersagen höher an als proaktive Vorschläge, damit das Modell nur bei echter Unsicherheit nach Hilfe fragt.
Beide Modelle übertrafen nach dem Training alle zuvor evaluierten MLLMs, einschließlich o4-mini (37,4 bzw. 38,6 vs. 34,0 Prozent). Die gelernte Proaktivität generalisiert auf Szenarien außerhalb des Trainings: Bei ChangeIt stieg die Genauigkeit von Qwen2.5-VL-3B von 12,4 auf 55,6 Prozent. Wird die Belohnung für proaktive Vorschläge aber auf das gleiche Niveau wie für korrekte Vorhersagen gesetzt, kippt das Verhalten: Das Modell generiert fast nur noch proaktive Vorschläge und fällt auf 5,4 Prozent zurück.
Trotz der Fortschritte bleibt eine deutliche Lücke zum Referenz-Setting (40,7 vs. 75,1 Prozent). Die Forscher veröffentlichen ProactiveBench als Open Source und sehen darin einen ersten Schritt hin zu Modellen, die erkennen, wann ihnen Informationen fehlen, und nach Unterstützung fragen, statt falsche Antworten zu generieren.
Modelle wissen nicht, was sie nicht wissen
ProactiveBench adressiert ein Problem, das sich auch in anderen aktuellen Studien zeigt: Multimodale Sprachmodelle scheitern systematisch am Umgang mit Unsicherheit. Der WorldVQA-Benchmark von Moonshot AI zeigte kürzlich, dass selbst die besten Modelle bei der visuellen Objekterkennung an der 50-Prozent-Marke scheitern und dabei systematisches Übervertrauen zeigen.
Eine Stanford-Studie zum sogenannten Mirage-Effekt ging noch weiter. Multimodale Modelle wie GPT-5 oder Gemini 3 Pro beschrieben dort selbstbewusst visuelle Details und stellten medizinische Diagnosen, obwohl gar kein Bild vorlag. Auf etablierten Benchmarks erreichten sie 70 bis 80 Prozent ihrer Leistung allein aus Textmustern und Vorwissen. Die Modelle tun also so, als hätten sie etwas gesehen, und merken nicht, dass die visuelle Grundlage fehlt.
Forscher der Sapienza Universität Rom wiesen mit ihrer "Spilled Energy"-Methode nach, dass Halluzinationen messbare Spuren in den Berechnungen eines Modells hinterlassen. Eine Studie zur Schwierigkeitseinschätzung von Prüfungsfragen ergab zudem, dass Sprachmodelle ihre eigenen Grenzen nicht zuverlässig erkennen. Das gemeinsame Muster: Aktuelle KI-Modelle wissen nicht, was sie nicht wissen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.