ARC-AGI-3: Top-KI-Modelle schaffen unter 1 Prozent bei Aufgaben, die Menschen einfach lösen
Der neue Benchmark ARC-AGI-3 lässt KI-Systeme in interaktiven Spielumgebungen antreten, die Menschen mühelos meistern. Kein Frontier-Modell knackt die 1-Prozent-Marke - auch weil der Benchmark ihnen ihre größten Vorteile nimmt.
Die ARC Prize Foundation hat mit ARC‑AGI‑3 ihren neuen Benchmark veröffentlicht, der KI-Systeme in interaktiven, rundenbasierten Spielumgebungen testet. Statt wie bei den Vorgängern statische Muster aus Eingabe-Ausgabe-Paaren abzuleiten, müssen KI-Agenten nun eigenständig Umgebungen erkunden, Hypothesen bilden, Ziele ableiten und Handlungspläne umsetzen. Anweisungen oder Hinweise auf das Spielziel erhalten sie nicht. Eine frühe Version wurde im Sommer 2025 vorgestellt.
Laut dem begleitenden technischen Report wurden alle 135 Umgebungen von Menschen ohne Vorwissen und ohne Anleitung gelöst. Alle getesteten Frontier-Modelle erreichen dagegen weniger als 1 Prozent: Gemini 3.1 Pro Preview kommt auf 0,37 Prozent, GPT 5.4 auf 0,26 Prozent, Opus 4.6 auf 0,25 Prozent, Grok-4.20 auf 0,00 Prozent.
Wichtig: Maschinen und Menschen werden nicht gleich gemessen.
Quadratische Effizienz statt simpler Trefferquote
ARC-AGI-3 verwendet eine Metrik namens RHAE (Relative Human Action Efficiency). Gemessen wird nicht einfach, ob ein Modell eine Aufgabe löst, sondern wie viele Aktionen es dafür im Vergleich zu einem Menschen benötigt. Als Aktion zählt dabei nur eine Interaktion, die den Spielzustand tatsächlich verändert. Interne Rechenschritte oder Reasoning-Ketten bleiben außen vor. Die Scores von ARC-AGI-1/2 und ARC-AGI-3 daher nicht vergleichbar.
Die menschliche Baseline ist der zweitbeste von zehn Erstspielern pro Umgebung. Der beste Spieler wird laut der Scoring-Dokumentation bewusst ausgeschlossen, um Ausreißerleistungen herauszufiltern und gleichzeitig eine realistische Referenz für kompetentes menschliches Spielen zu erhalten. Pro Level wird die Effizienz quadratisch berechnet: (menschliche Aktionen / KI-Aktionen)^2. Braucht ein Mensch also 10 Aktionen und die KI 100, ergibt das nicht 10 Prozent, sondern nur 1 Prozent für die KI. Diese quadratische Bestrafung soll Brute-Force-Strategien entwerten. Schneller als der Mensch zu sein bringt keinen Bonus, der Score pro Level ist bei 1,0 gedeckelt. Spätere Level werden stärker gewichtet, da sie tieferes Verständnis erfordern. Aus Kostengründen will das Team die maximale Anzahl von Versuchen für Agenten auf das 5-fache menschlicher Versuche reduzieren.
Gerüste helfen, beweisen aber keine allgemeine Intelligenz
Auf dem offiziellen Leaderboard werden außerdem nur Modelle via API ohne speziell angefertigte Hilfsgerüste (Harnesses) getestet, mit identischem System-Prompt.
Die ARC Prize Foundation begründet diese Entscheidung im Paper damit, dass der Benchmark nicht die menschliche Intelligenz messen soll, die in den Bau eines aufgabenspezifischen Systems geflossen ist, sondern die allgemeine Intelligenz des KI-Modells selbst. Künftige AGI-Systeme sollten keine externe Hilfestellung benötigen, um sich neuen Aufgaben zu nähern.
Laut dem Paper zeigte sich bei Tests mit der Duke University eine bimodale Leistung: Opus 4.6 erreichte mit einem handgefertigten Harness 97,1 Prozent auf einer bekannten Umgebung, aber 0 Prozent auf einer unbekannten. Das belege, dass die Wahrnehmung der Spielumgebung und das API-Format nicht die limitierenden Faktoren seien. Vielmehr übertrügen sich speziell konstruierte Strategien schlicht nicht auf ungesehene Umgebungen. Chollet argumentiert bei X, echte AGI dürfe keine aufgabenspezifische menschliche Anleitung benötigen, wenn normale Menschen die Aufgaben ohne Hilfe bewältigen.
Für Harness-getriebene Ergebnisse gibt es aber weiter ein separates Community-Leaderboard, auf dem Scores selbst gemeldet werden. Die Foundation warnt ausdrücklich davor, diese Ergebnisse als Beleg für AGI-Fortschritt zu interpretieren. Sie erwartet jedoch, dass die besten Ideen aus der Harness-Forschung langfristig in die Modelle selbst einfließen, so wie Chain-of-Thought-Prompting einst als externer Ansatz begann und schließlich als Modell-Feature in OpenAIs o1 landete.
Chollet reagiert bei X auf den naheliegenden Einwand, die niedrigen Scores seien nur dem Fehlen von Harnesses und dem simplen Prompt geschuldet: Das G in AGI stehe für "general". Allgemeine Intelligenz bedeute nicht, für eine große Bandbreite von Aufgaben speziell trainiert worden zu sein, sondern sich jeder neuen Aufgabe zu stellen und sie selbst zu lösen. Wenn normale Menschen das ohne Anleitung und ohne Werkzeuge schafften, warum solle AGI dann spezielles Handholding und handgefertigte Instruktionen benötigen? Entweder man glaube, dass AGI möglich sei, dann werde ein echtes AGI-System ARC-AGI-3 lösen können, weil normale Menschen es auch könnten. Oder man glaube, dass KI lediglich ein Automatisierungswerkzeug sei, das bei jeder neuen Aufgabe menschliche Intervention erfordere.
Auf der Arc-Prize-Webseite können die Aufnahmen der jüngsten Modelltests abgespielt werden.
Frühwarnsystem für KI-Fortschritt
Die Vorgänger-Benchmarks haben wiederholt Wendepunkte in der KI-Entwicklung der letzten Jahre angezeigt. ARC-AGI-1 war wohl der erste Benchmark, der den Durchbruch von Frontier-KI-Reasoning-Systemen wie OpenAIs o3 präzise identifizierte, als andere Benchmarks bereits gesättigt waren. ARC-AGI-2 zeigte dann den raschen Fortschritt moderner Reasoning-Modelle und den Einsatz von Hilfsgerüsten, die inzwischen etwa in Coding-Tools wie Claude Code und Codex produktiv eingesetzt werden. Mittlerweile sind beide Benchmarks praktisch auch durch den Einsatz solcher Gerüste gesättigt.
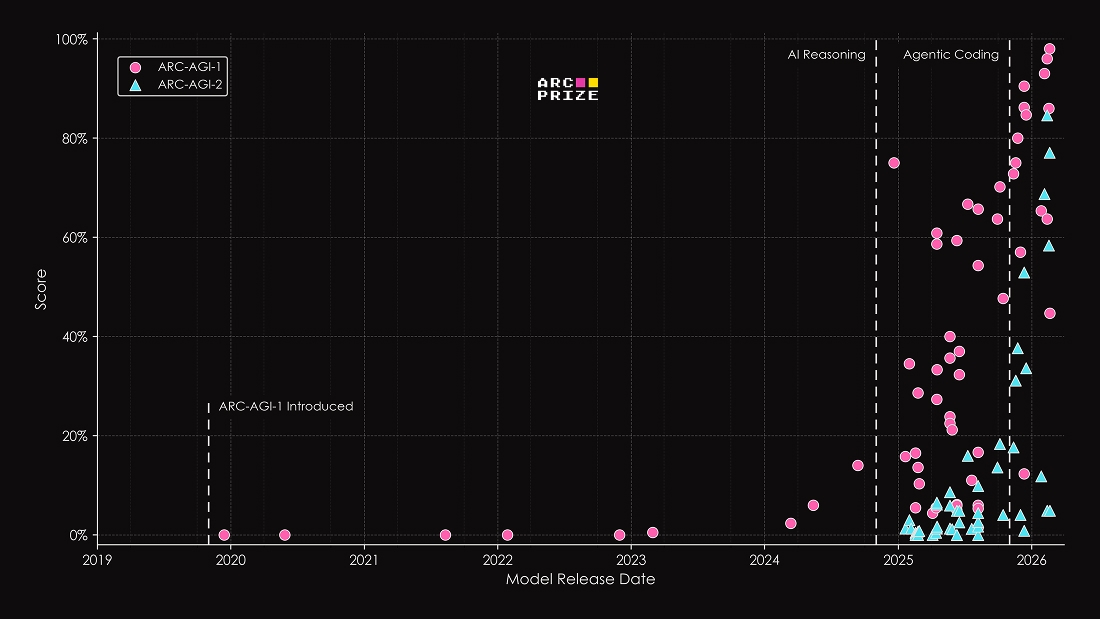
ARC-AGI-3 soll die nächste offene Lücke vermessen: agentische Intelligenz, also die Fähigkeit, sich in völlig unbekannten Umgebungen ohne spezifisches Training zurechtzufinden. Dass alle aktuellen Frontier-Modelle hier unter 1 Prozent liegen, zeigt laut den Machern, wie weit KI-Systeme von menschenähnlicher Anpassungsfähigkeit entfernt bleiben.
Die ARC Prize Foundation stellt 25 Umgebungen öffentlich zum Spielen bereit und veranstaltet den ARC Prize 2026 auf Kaggle mit 2 Millionen Dollar Preisgeld.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.