AlphaZero: Googles Sprungbrett zur allgemeinen Künstlichen Intelligenz?

All your Brettspiele are belong to us. Und bald noch mehr?
Vor rund einem Jahr stellte die Google-Schwester Deepmind die Super-KI AlphaZero vor (wir berichteten). Innerhalb weniger Stunden und Tage lernte die Maschine, die Brettspiele Go, Schach und Shogi (japanisches Schach) auf laut Deepmind "übermenschlichem Niveau" zu spielen - eben so gut, dass sie von einem Menschen nicht mehr geschlagen werden kann.
Die Besonderheit an AlphaZero ist, dass die KI ihr Training weitgehend ohne den Menschen erledigen kann. Denn AlphaZero greift nicht auf menschliche Spielzüge zurück, um das Spiel zu lernen. Daher trägt die KI auch die englische Null im Namen.
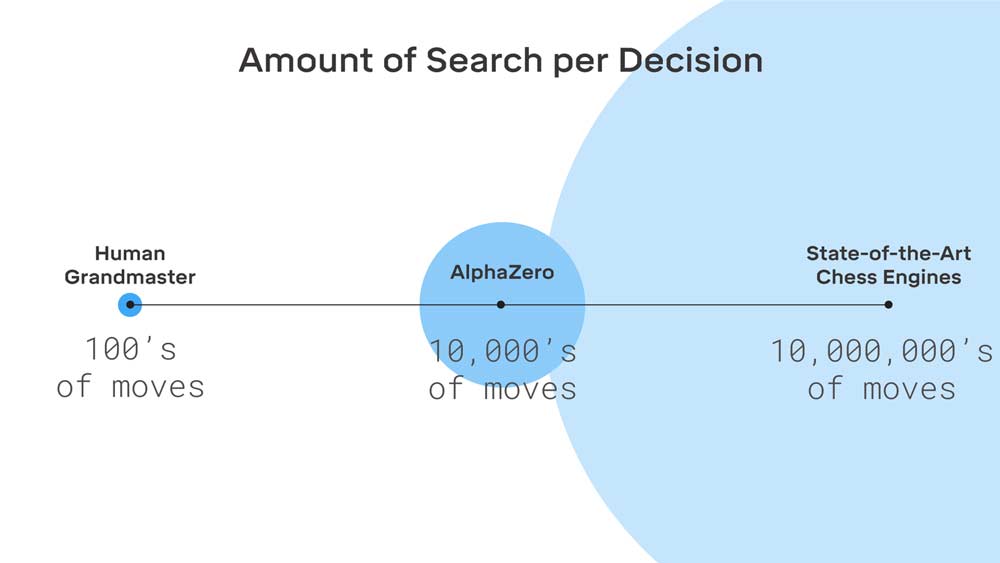
Stattdessen werden AlphaZero nur die Spielregeln beigebracht. Das eigentliche Spiel lernt sie, indem sie in Simulationen millionenfach gegen sich selbst antritt. Das einfache Schach meisterte sie so in circa neun Stunden, das komplexere Go beherrschte die KI nach circa 13 Tagen.
Die Fachwelt erkennt Deepminds Leistung an
Als Deepmind die KI vor einem Jahr vorstellte, hatte sie noch keine Verifikation durch die wissenschaftliche Fachgemeinde. Die bekommt Deepmind jetzt, die Forschungsarbeit zu AlphaZero schafft es auf das Titelblatt des bekannten wissenschaftlichen Fachjournals "Science".
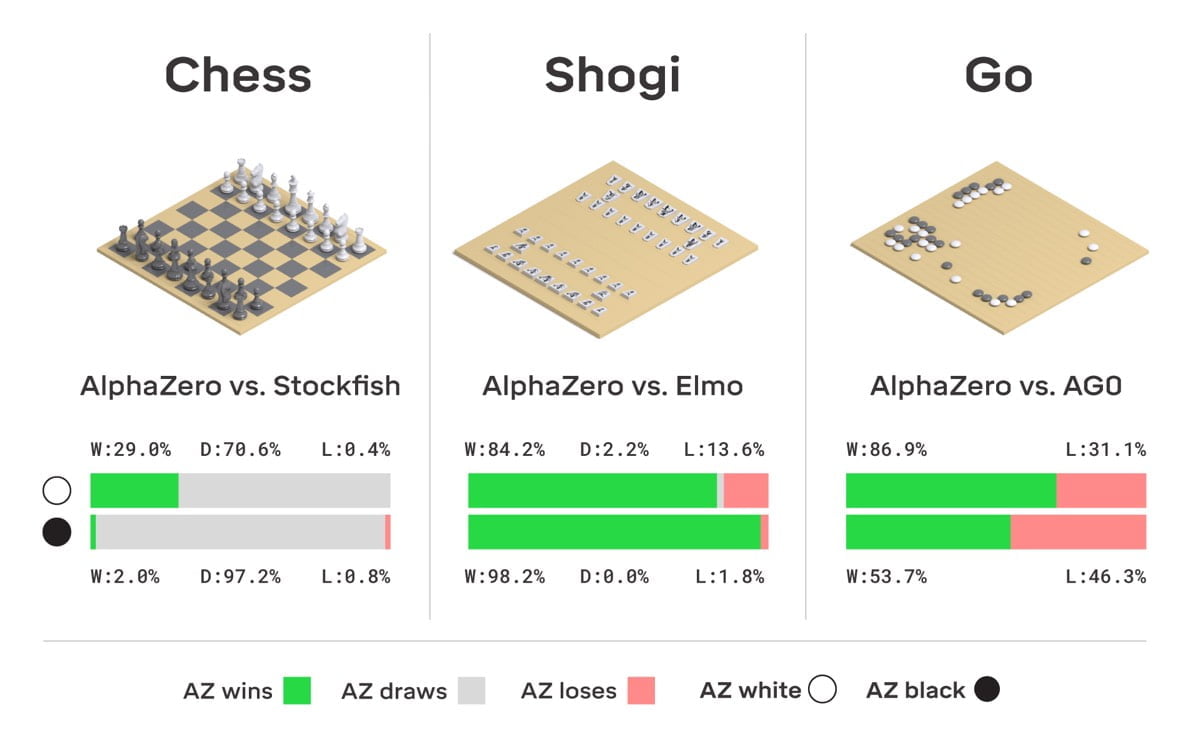
Deepmind nutzte das Jahr, um zu beweisen, dass AlphaZero nicht nur übermenschlich agiert, sondern im Grunde auch schon übermaschinell. Denn sie lässt auch anderen Schach-, Shogi- und Go-Computern keine Chance.
Zum Beispiel schlug sie die etablierte Schach-Software Stockfish in 1.000 Matches 155 Mal bei nur sechs verlorenen Partien. Die Vorgänger-KI AlphaZero Go muss sich bei Go in 61 Prozent der Tests geschlagen geben. Die Shogi-Software Elmo war im Grunde chancenlos.
AlphaZero spielt mit Gefühl
Viel spannender als die reine Erkenntnis, dass Deepmind einen verdammt guten Brettspielsimulator entwickelt hat, ist, wie sich Schachgroßmeister über die Spielzüge der Künstlichen Intelligenz äußern.
"Anstatt menschliche Anweisungen und Wissen mit enormer Geschwindigkeit zu verarbeiten, wie alle früheren Schachmaschinen, generiert AlphaZero sein eigenes Wissen", sagt Garry Kasparov. "Das gelingt in nur wenigen Stunden, und die Ergebnisse haben alle bekannten Menschen oder Maschinen übertroffen."
"Nachdem ich viele Monate damit verbracht habe, die Schachpartien von AlphaZero zu erforschen, habe ich das Gefühl, dass meine Vorstellung und mein Verständnis vom Spiel verändert und bereichert worden sind", sagt die internationale Schachmeisterin Natasha Regan. "AlphaZero hat all das gelernt, was wir Menschen uns über das Schachspiel beigebracht haben, und es könnte ein mächtiges Lehrmittel für die ganze Gemeinschaft sein."
Der britische Schach-Champion Matthew Sadler meint: "Herkömmliche Schachcomputer sind außergewöhnlich stark und machen nur wenige offensichtliche Fehler, können aber abdriften, wenn sie mit Positionen ohne konkrete und kalkulierbare Lösung konfrontiert werden ... Beeindruckend ist, dass es AlphaZero gelingt, den eigenen Spielstil über ein sehr breites Spektrum von Positionen und Spieleröffnungen durchzusetzen."
Gerade in solchen Positionen, in denen laut Sadler "Gefühl", "Einsicht" oder "Intuition" gefragt sind, glänze AlphaZero. Die KI spiele wie ein leidenschaftlicher Mensch. "Es ist ein sehr schöner Stil", sagt Sadler.
Die Macht der Belohnung
Deepmind setzt beim Training von AlphaZero auf sogenanntes bestärkendes Lernen: Die KI wird belohnt, wenn sie gewinnt, so ähnlich wie der Hund, der ein Leckerli bekommt, wenn er Sitz macht.
Das Verfahren gilt als mächtig und soll unabhängigere KIs erschaffen, die besser generalisieren können. Dass dieses Potenzial vorhanden ist, beweist AlphaZero.
Aktuelle Lackmustests zeigen jedoch, dass nach diesem Prinzip trainierte KIs Probleme haben könnten, ihr in einfachen Simulationen antrainiertes Wissen auf die deutlich komplexere Realität zu übertragen.
Deepmind-Gründer Demis Hassabis bezeichnet AlphaZero zumindest als Sprungbrett hin zur allgemeinen Künstlichen Intelligenz, also einer maschinellen Intelligenz, die wie ein Mensch denken, agieren und sich eigenständig verbessern kann.
"Der Grund, warum wir uns selbst und all diese Spiele testen, ist ... dass sie ein sehr bequemes Testfeld für uns sind, um unsere Algorithmen zu entwickeln ... Letztendlich entwickeln wir Algorithmen, die in die reale Welt übersetzt werden können, um an wirklich schwierigen Problemen zu arbeiten ... und Experten in diesen Bereichen zu helfen", sagt Hassabis.
Im eigenen Blog schreibt Deepmind:
"Um intelligente Systeme zu schaffen, die in der Lage sind, eine Vielzahl von realen Problemen zu lösen, müssen sie flexibel sein und sich an neue Situationen anpassen. [...] Die Fähigkeit von AlphaZero, drei unterschiedliche, komplexe Spiele zu beherrschen - und möglicherweise jedes perfekte Informationsspiel - ist ein wichtiger Schritt. Er zeigt, dass ein einzelner Algorithmus lernen kann, wie man in einer Reihe von Situationen neues Wissen entdeckt."
Titelbild: Deepmind
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.