Gemma 4: Google stellt neue Open-Source-Modelle unter Apache-2.0-Lizenz vor
Kurz & Knapp
- Google veröffentlicht mit Gemma 4 eine Familie aus vier offenen KI-Modellen (2B, 4B, 26B, 31B Parameter), die auf derselben Technologie wie das proprietäre Gemini 3 basieren.
- Die Modelle stehen erstmals unter der kommerziell permissiven Apache-2.0-Lizenz, ein klarer Kurswechsel gegenüber früheren, restriktiveren Gemma-Lizenzen.
- Die Modelle decken ein breites Hardware-Spektrum ab: Die kleineren E2B- und E4B-Varianten laufen auf Smartphones, Raspberry Pi oder Jetson Orin Nano. Die größeren 26B- und 31B-Modelle sind für Workstations und Server konzipiert.
Google veröffentlicht mit Gemma 4 seine bisher leistungsfähigste offene Modellfamilie. Die vier neuen Modelle sollen auf Hardware vom Smartphone bis zur Workstation laufen und stehen erstmals unter einer vollständig offenen Lizenz.
Die Modelle basieren laut Google auf derselben Technologie wie das proprietäre Gemini 3. Sie werden unter der kommerziell permissiven Apache-2.0-Lizenz veröffentlicht, die Entwicklern volle Kontrolle über Daten, Infrastruktur und Modelle gibt. Das ist ein deutlicher Kurswechsel. Frühere Gemma-Versionen standen unter einer restriktiveren Google-eigenen Lizenz.
Alle Gemma-4-Modelle bringen laut Google deutliche Verbesserungen bei mehrstufigem Reasoning und mathematischen Aufgaben. Für agentische Workflows unterstützen sie nativ Function-Calling, strukturierten JSON-Output und System-Instruktionen. Autonome Agenten können damit verschiedene Tools und APIs ansprechen.
Vier Modelle für unterschiedliche Einsatzzwecke
Gemma 4 umfasst vier Größen: Effective 2B (E2B), Effective 4B (E4B), ein 26B Mixture-of-Experts-Modell (MoE) sowie ein 31B Dense-Modell. Alle Varianten sollen über einfache Chat-Funktionen hinausgehen und komplexe Logik sowie agentische Workflows beherrschen.
| E2B | E4B | 26B MoE | 31B Dense | |
|---|---|---|---|---|
| Aktive Parameter | "effektive" 2 Mrd. | "effektive" 4 Mrd. | 3,8 Mrd. aktiv | — |
| Architektur | — | — | MoE | Dense |
| Kontextfenster | 128K Token | 128K Token | bis zu 256K Token | bis zu 256K Token |
| Ziel-Hardware | Smartphones, Raspberry Pi, Jetson Orin Nano | Smartphones, Raspberry Pi, Jetson Orin Nano | Personal Computers, Consumer-GPUs (quantisiert), Workstations, Accelerators | Personal Computers, Consumer-GPUs (quantisiert), Workstations, Accelerators |
| Offline-Betrieb | ✅ | ✅ | ✅ | ✅ |
| Vision (Bilder/Video) | ✅ | ✅ | ✅ | ✅ |
| Audio-Input | ✅ | ✅ | — | — |
| Quantisiert auf Consumer-GPU | — | — | ✅ | ✅ |
| Arena-AI-Ranking (offen) | — | — | #6 | #3 |
| Besonderheit | Compute- und Speichereffizienz auf Edge-Geräten | Compute- und Speichereffizienz auf Edge-Geräten | Fokus auf Latenz, 3,8 Mrd. aktive Parameter, schnelle Token-Generierung | maximale Qualität, Basis für Fine-Tuning |
Auf dem Arena-AI-Text-Leaderboard belegt das 31B-Modell laut Google derzeit Platz 3 unter allen offenen Modellen weltweit, das 26B-MoE-Modell Platz 6. Dabei soll Gemma 4 Modelle übertreffen, die 20-mal so groß sind. Für Entwickler bedeutet das: leistungsstarke Ergebnisse bei deutlich geringerem Hardware-Aufwand.
| Benchmark | Gemma 4 31B IT Thinking | Gemma 4 26B A4B IT Thinking | Gemma 4 E4B IT Thinking | Gemma 4 E2B IT Thinking | Gemma 3 27B IT | |
|---|---|---|---|---|---|---|
| Arena AI (text) (As of 4/2/26) | 1452 | 1441 | - | - | 1365 | |
| MMLU (Multilingual Q&A) | No tools | 85.2% | 82.6% | 69.4% | 60.0% | 67.6% |
| MMMU Pro (Multimodal reasoning) | 76.9% | 73.8% | 52.6% | 44.2% | 49.7% | |
| AIME 2026 (Mathematics) | No tools | 89.2% | 88.3% | 42.5% | 37.5% | 20.8% |
| LiveCodeBench v6 (Competitive coding problems) | 80.0% | 77.1% | 52.0% | 44.0% | 29.1% | |
| GPQA Diamond (Scientific knowledge) | No tools | 84.3% | 82.3% | 58.6% | 43.4% | 42.4% |
| τ2-bench (Agentic tool use) | Retail | 86.4% | 85.5% | 57.5% | 29.4% | 6.6% |
Die beiden größeren Modelle sind für Workstations und Server konzipiert. Die unquantisierten bfloat16-Gewichte des 31B-Modells passen laut Google auf eine einzelne 80-GB-NVIDIA-H100-GPU. Quantisierte Versionen sollen auch auf Consumer-Grafikkarten laufen.
Das 26B-MoE-Modell aktiviert bei der Inferenz nur 3,8 Milliarden seiner Parameter und soll dadurch besonders schnelle Token-Generierung ermöglichen. Das 31B-Dense-Modell zielt dagegen auf maximale Qualität und soll eine solide Grundlage für Fine-Tuning bieten.
Die kleineren E2B- und E4B-Modelle wurden speziell für den Einsatz auf mobilen Geräten und IoT-Hardware entwickelt. Sie aktivieren bei der Inferenz nur zwei beziehungsweise vier Milliarden Parameter, um Arbeitsspeicher und Akku zu schonen.
Beide Edge-Modelle verarbeiten nativ Bilder und Video sowie Audio-Eingaben für Spracherkennung. Ihr Kontextfenster umfasst 128.000 Token, während die größeren Modelle bis zu 256.000 Token verarbeiten können.
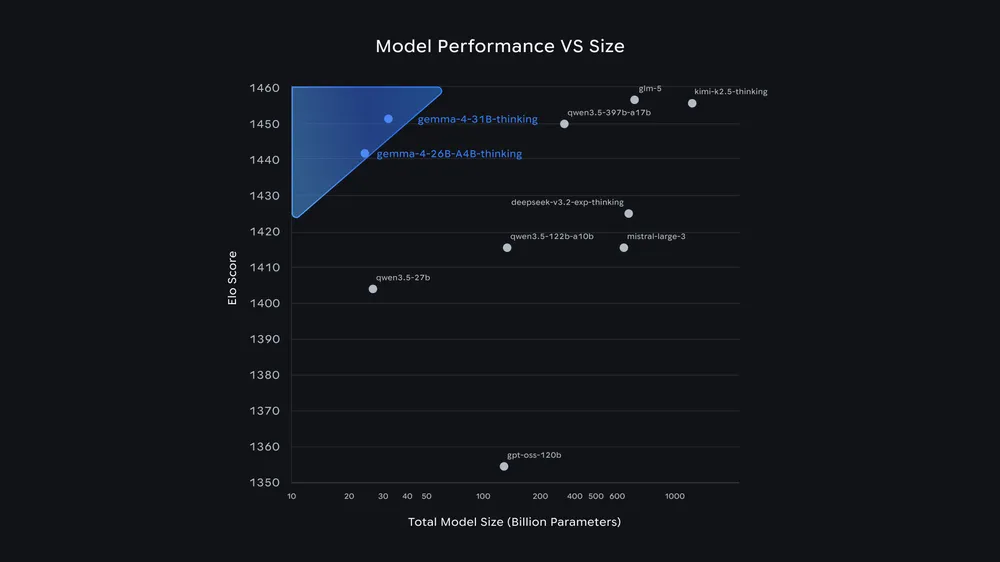
Unabhängige Benchmarks von Artificial Analysis bestätigen die gute Leistung der größeren Gemma-4-Modelle im Verhältnis zu ihrer Parameterzahl. Auf dem GPQA-Diamond-Benchmark für wissenschaftliches Reasoning erreicht Gemma 4 31B im Reasoning-Modus 85,7 Prozent.
Das ist laut Artificial Analysis das zweitbeste Ergebnis aller offenen Modelle mit weniger als 40 Milliarden Parametern, knapp hinter Qwen3.5 27B (85,8 Prozent). Dabei benötigt Gemma 4 31B mit rund 1,2 Millionen Output-Tokens weniger Rechenaufwand als Qwen3.5 27B (1,5 Millionen) und Qwen3.5 35B A3B (1,6 Millionen).
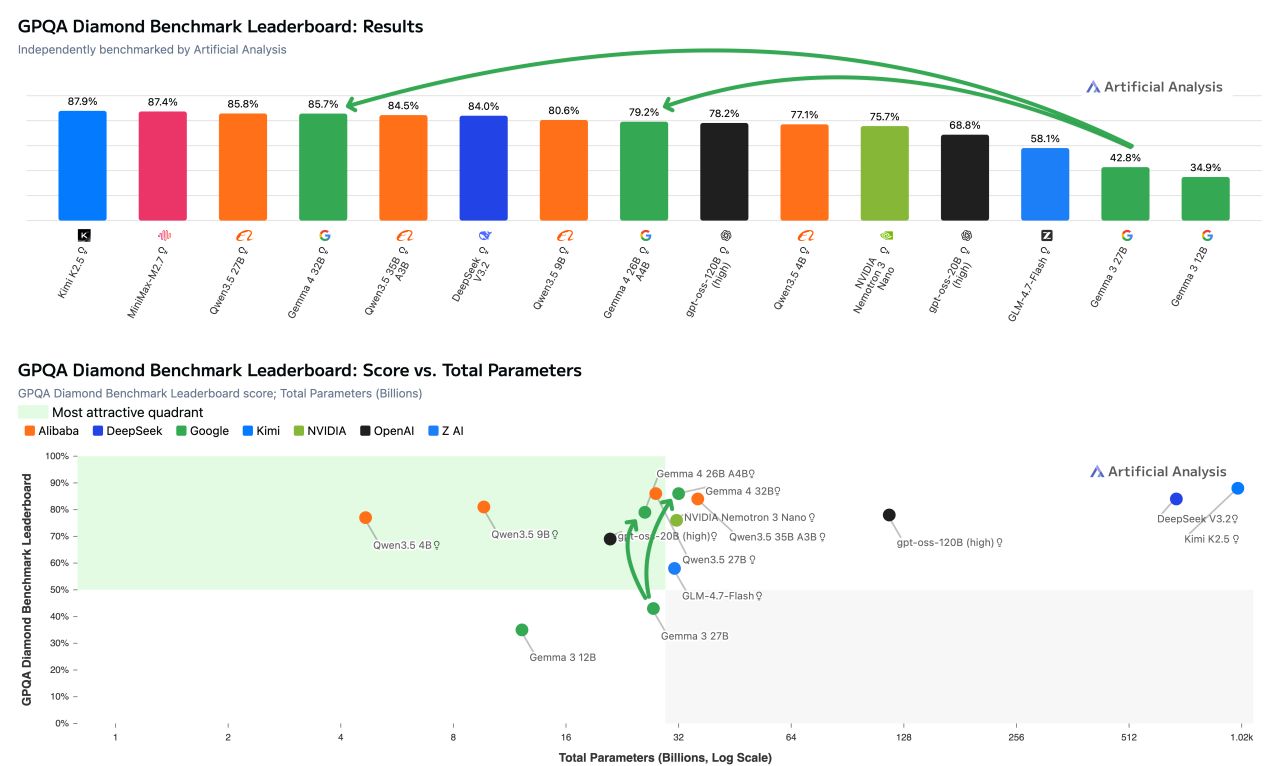
Das 26B-MoE-Modell erzielt im selben Benchmark 79,2 Prozent. Damit liegt es vor OpenAIs gpt-oss-120B mit 76,2 Prozent, aber hinter Qwen3.5 9B mit 80,6 Prozent. Beide evaluierten Modelle laufen laut Artificial Analysis auf einer einzelnen H100-GPU. Die vollständige Auswertung aller vier Gemma-4-Modelle im Artificial Analysis Intelligence Index steht noch aus. Wie immer gilt zudem, dass Benchmark-Ergebnisse nur Indikatoren für die Leistung bei echten Aufgaben sind.
Verfügbarkeit und unterstützte Plattformen
Gemma 4 ist ab sofort über Hugging Face, Kaggle und Ollama verfügbar. Google AI Studio unterstützt die 31B- und 26B-Modelle, die Google AI Edge Gallery die E4B- und E2B-Varianten.
Zum Start gibt es Unterstützung durch zahlreiche Frameworks und Plattformen, darunter Hugging Face Transformers, vLLM, llama.cpp, MLX, Ollama, NVIDIA NIM und NeMo, LM Studio, Unsloth, SGLang, Keras und weitere. Fine-Tuning ist über Google Colab, Vertex AI oder lokale Gaming-GPUs möglich. Für den Produktionseinsatz lassen sich die Modelle über Vertex AI, Cloud Run und GKE auf Google Cloud skalieren.
Auf der Hardware-Seite unterstützt Gemma 4 laut Google NVIDIA-Hardware von Jetson Orin Nano bis Blackwell-GPUs, AMD-GPUs über den ROCm-Stack sowie Googles eigene Trillium- und Ironwood-TPUs.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren