Alibabas Qwen-Team bringt KI-Modelle mit neuem Algorithmus zum tieferen Nachdenken

Kurz & Knapp
- Alibabas Qwen-Team hat einen Algorithmus entwickelt, der beim Training von Reasoning-Modellen nicht alle Tokens gleich belohnt, sondern jeden Schritt danach gewichtet, wie stark er die weitere Argumentationskette beeinflusst.
- Das Modell lernte dadurch deutlich längere Denkprozesse und begann eigenständig, seine Zwischenergebnisse zu hinterfragen und über alternative Lösungswege gegenzuprüfen.
- Der Algorithmus wurde bislang nur auf mathematischen Aufgaben getestet. Ob sich die Methode auf andere Bereiche übertragen lässt, ist offen. Das Trainingssystem soll als Open Source erscheinen.
Reinforcement Learning stößt bei Reasoning-Modellen an eine Grenze, weil alle Tokens gleich belohnt werden. Ein neuer Algorithmus von Alibabas Qwen-Team gewichtet stattdessen jeden Schritt danach, wie stark er die nachfolgende Argumentationskette beeinflusst. Er verdoppelt so die Länge der Denkprozesse.
Wenn ein großes Sprachmodell per Reinforcement Learning das Denken lernen soll, steht am Ende einer generierten Antwort typischerweise ein binäres Urteil: richtig oder falsch. Diese Belohnung wird dann gleichmäßig auf jeden einzelnen Token der Sequenz verteilt. Ob ein Token den entscheidenden logischen Wendepunkt markiert oder bloß ein Komma ist, spielt keine Rolle.
Laut dem Qwen-Team ist diese grobe Kreditvergabe ein zentraler Grund, warum Reasoning-Modelle bei gängigen Trainingsmethoden wie GRPO (Group Relative Policy Optimization) an eine Leistungsdecke stoßen. Die Denkketten wachsen bis zu einer mittleren Länge und stagnieren dann.
Mit Future-KL Influenced Policy Optimization (FIPO) will das Team diesen Flaschenhals überwinden. Der Algorithmus bewertet jeden Token nicht isoliert, sondern schaut voraus: Wie verändert sich das Verhalten des Modells in der restlichen Sequenz, nachdem dieser Token generiert wurde?
FIPO berechnet dafür die kumulative Wahrscheinlichkeitsverschiebung aller nachfolgenden Tokens und nutzt dieses Signal, um die Belohnung feiner zu verteilen. Tokens, die eine produktive Argumentationskette anstoßen, bekommen mehr Gewicht. Tokens, nach denen das Modell in eine Sackgasse läuft, bekommen weniger.
Vergleichbare Ergebnisse ohne separates Hilfsmodell
Bisherige Versuche, das Problem der gleichförmigen Belohnung zu lösen, griffen meist auf PPO-basierte Methoden zurück. Diese verwenden ein separates Value-Modell, das für jeden Token einen individuellen Vorteilswert schätzt.
Dieses Hilfsmodell muss in der Regel selbst mit langen Chain-of-Thought-Daten vortrainiert werden. Dadurch fließt externes Wissen ein. Ob die Leistungsgewinne dann vom Algorithmus selbst stammen oder vom vortrainierten Hilfsmodell geerbt werden, lässt sich laut den Forschern kaum beantworten. FIPO kommt ohne ein solches Modell aus und erreicht trotzdem vergleichbare Ergebnisse.
Damit das Training stabil bleibt, baut FIPO mehrere Sicherheitsmechanismen ein. Ein Discount-Faktor sorgt dafür, dass nahe Tokens stärker gewichtet werden als weit entfernte. Deren Einfluss auf die Argumentationskette ist ohnehin schwer vorhersagbar.
Zusätzlich werden Tokens herausgefiltert, bei denen sich das Modell zwischen zwei Trainingsschritten zu stark verändert hat. Ohne diese Filterung beobachteten die Forscher schwere Instabilitäten. Das Training entgleiste und die Antwortlängen brachen abrupt ein.
Doppelt so lange Denkprozesse, höhere Genauigkeit
Getestet wurde FIPO auf Qwen2.5-32B-Base, einem Modell, das zuvor keinerlei Kontakt mit synthetischen Long-CoT-Daten hatte. Trainiert wurde ausschließlich auf dem öffentlich verfügbaren Datensatz von DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization), einer verbreiteten Open-Source-Variante des GRPO-Trainings, um einen fairen Vergleich zu gewährleisten.
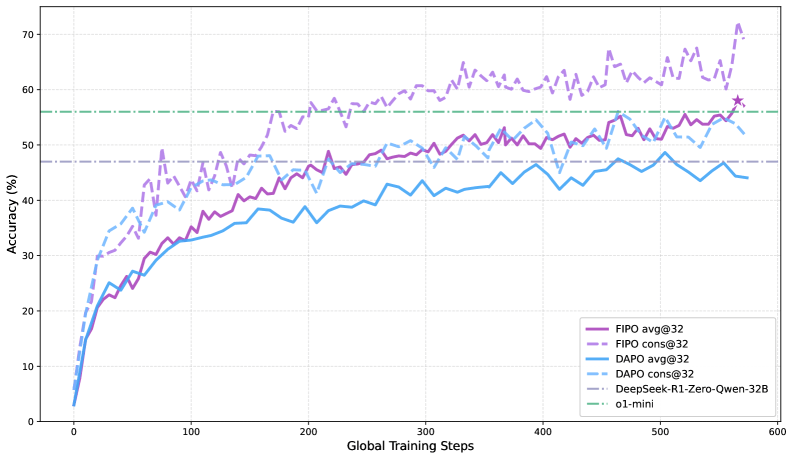
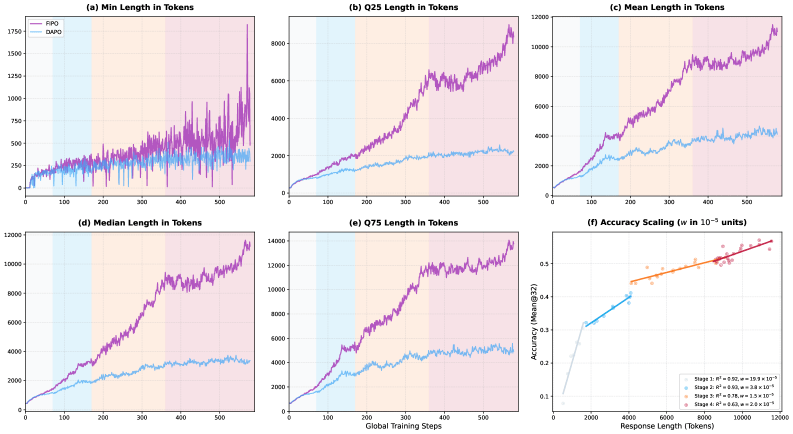
Die Ergebnisse fallen deutlich aus. Während die durchschnittliche Chain-of-Thought-Länge bei DAPO bei rund 4.000 Tokens stagniert, treibt FIPO sie auf über 10.000. Auf dem Mathematik-Benchmark AIME 2024 steigt die Genauigkeit von 50 auf 56 Prozent, mit einer Spitze von 58 Prozent. Damit übertrifft FIPO sowohl DeepSeek-R1-Zero-Math-32B mit etwa 47 Prozent als auch OpenAIs o1-mini mit rund 56 Prozent. Auf dem schwierigeren AIME 2025 verbessert sich der Wert von 38 auf 43 Prozent.
Laut den Forschern werden dabei nicht nur einzelne Ausreißer länger. Die gesamte Verteilung der Antwortlängen verschiebt sich nach oben, von den kürzesten bis zu den längsten Antworten. Das deute auf einen grundlegenden Strategiewechsel des Modells hin.
Das Modell lernt von selbst, sich zu hinterfragen
Das Paper beschreibt vier Phasen, die das Modell im Trainingsverlauf durchläuft: Am Anfang produziert es nur oberflächliche Planungsschablonen, eine Art Gliederung ohne echte Rechnung, die in einer halluzinierten Antwort endet. In der zweiten Phase, in der DAPO für den Rest des Trainings verharrt, führt das Modell eine saubere lineare Argumentationskette aus und stoppt beim ersten Ergebnis.
Ab der dritten Phase passiert bei FIPO etwas Neues. Das Modell beginnt spontan, seine eigenen Zwischenergebnisse zu überprüfen. Es leitet ein Ergebnis ab, wechselt dann aber den Lösungsweg, etwa von algebraischer Manipulation zu geometrischer Interpretation, um die Antwort gegenzuprüfen. In der vierten Phase schließlich setzt das Modell auf systematische Mehrfachverifikation, rechnet große Quadratzahlen Schritt für Schritt nach und durchläuft die gesamte Ableitung mehrfach.
Dieses Verhalten erinnert laut dem Paper an die Inference-Time-Scaling-Strategien von OpenAIs o-Serie und Deepseek-R1, entsteht bei FIPO aber rein durch Reinforcement-Learning, ohne dass dafür Long-CoT-Synthetikdaten vorausgesetzt werden.
Nur Mathematik, nur ein Datensatz, nur Vanilla-Modelle
Die Forscher benennen die Grenzen ihrer Arbeit offen: FIPO wurde ausschließlich auf mathematischen Benchmarks evaluiert, trainiert auf einem einzigen Datensatz und nur auf Basismodellen ohne Long-CoT-Vortraining getestet. Die längeren Sequenzen treiben zudem die Rechenkosten nach oben.
Ob sich die Ergebnisse auf andere Domänen wie Code oder symbolische Logik übertragen lassen, bleibt offen. Auch gegenüber der Distillation von größeren Lehrermodellen besteht weiterhin eine Leistungslücke, da ein Modell durch reines Reinforcement-Learning weniger lernt als durch die direkte Anleitung eines stärkeren Modells.
Laut dem Paper soll das Trainingssystem zusammen mit den vollständigen Konfigurationen als Open Source veröffentlicht werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren