Studie kartografiert Frust über KI-generierten "Slop" in der Softwareentwicklung

Eine qualitative Studie untersucht gezielt, wie Entwickler minderwertige KI-Inhalte ("Slop") in der Softwareentwicklung wahrnehmen und kritisieren. Die Kritiker zeichnen eine "Tragödie der Allmende", bei der individuelle Produktivitätsgewinne auf Kosten von Reviewern und der Open-Source-Gemeinschaft gehen.
Wie Entwickler, die KI-Inhalte als Problem erleben, ihre Kritik begründen und strukturieren, haben Forscher der Universität Heidelberg, der University of Melbourne und der Singapore Management University in einer qualitativen Studie untersucht. Sebastian Baltes, Marc Cheong und Christoph Treude analysierten dafür 1154 Beiträge aus 15 Diskussionsthreads auf Reddit und Hacker News.
Die Forscher suchten dabei gezielt nach Threads, die den Begriff "ai slop" enthalten. Das Corpus erfasst damit primär Stimmen von Entwicklern, die das Phänomen bereits negativ rahmen. Positive oder neutrale Erfahrungen mit KI-gestützter Codegenerierung sind methodisch weitgehend ausgeschlossen. Die Studie bildet also nicht die Gesamtmeinung der Entwicklerschaft zu KI-Tools ab, sondern kartografiert die Argumentationsstrukturen einer kritischen Teilgruppe.
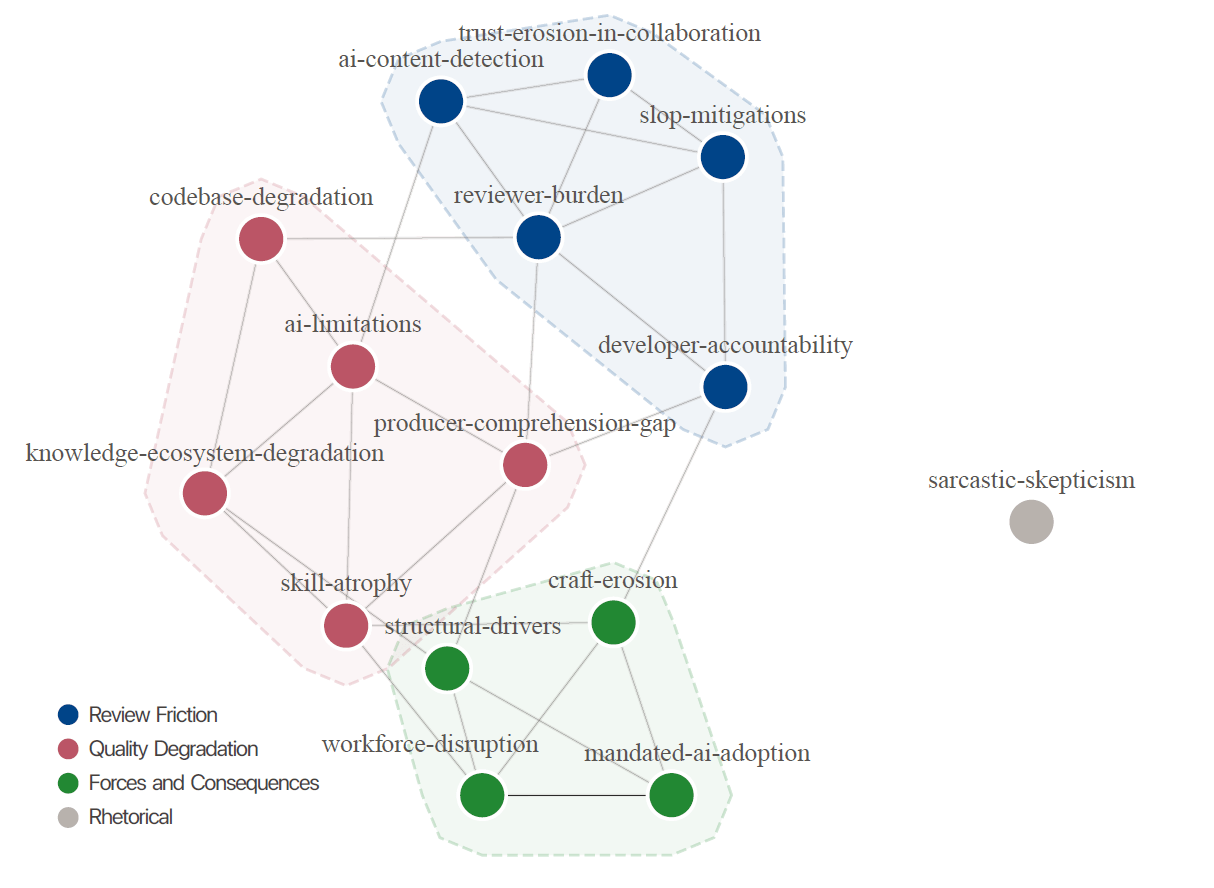
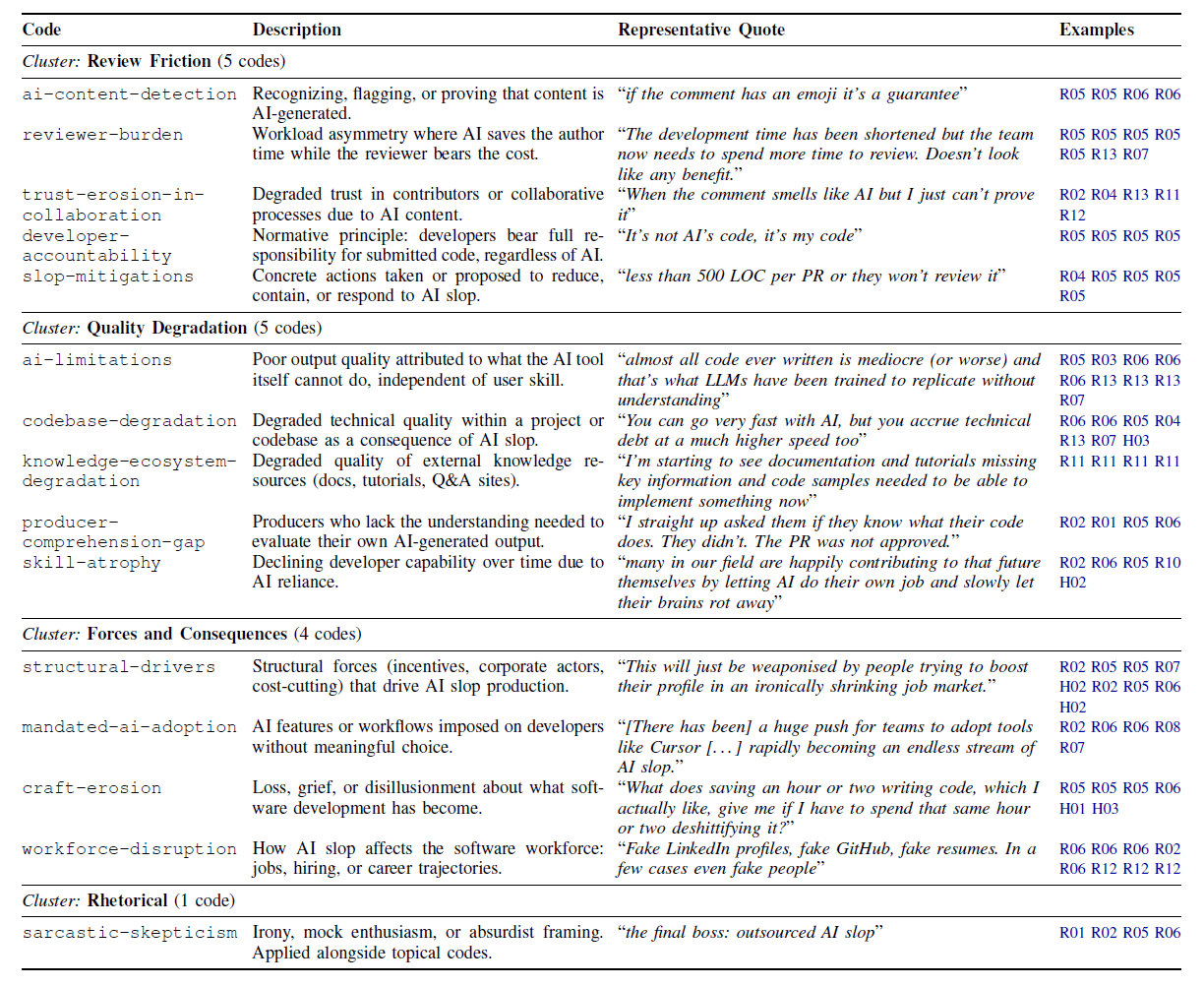
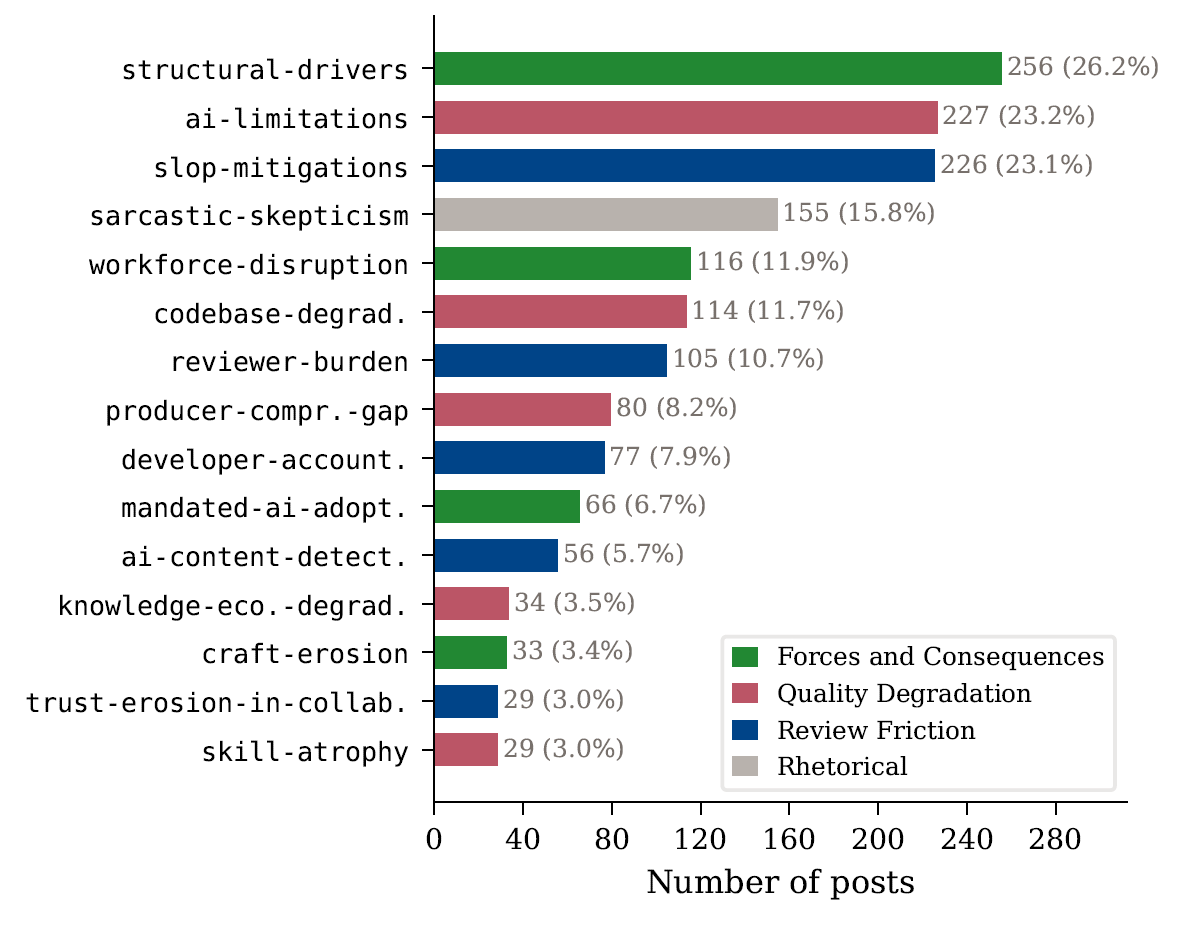
Aus den Daten entwickelten die Forscher ein Codebuch mit 15 Kategorien in drei thematischen Clustern: Review Friction (Reibungsverluste bei der Codeprüfung), Quality Degradation (Qualitätsverschlechterung) sowie Forces and Consequences (Treiber und Folgen).
Befürworter von KI-gestützter Entwicklung dürften dem Frust entgegenhalten, dass die aus menschlicher Perspektive wahrgenommene Codequalität an Bedeutung verlieren könnte. Ein OpenAI-Mitarbeitender etwa geht davon aus, dass KI-generierter Code bald nicht mehr manuell geprüft wird, dass daraus zwar negative Konsequenzen ("komplette Systemausfälle") entstehen, diese aber lösbar seien. Der bekannte KI-Entwickler Andrej Karpathy bezeichnete den Menschen bereits als Engpass in der Entwicklung.
Weitergedacht hieße das: Der Engpass Mensch verschärft sich mit zunehmender Leistungsfähigkeit der Modelle. Entscheidend wäre dann nicht mehr, ob Code menschlichen Qualitätsstandards genügt, sondern ob er funktioniert und von KI-Agenten gewartet, iteriert und optimiert werden kann. Der Mensch beaufsichtigt, ohne jede Zeile manuell prüfen zu müssen, so die Vision der Befürworter.
Individuelle Produktivitätsgewinne, kollektive Kosten
Der zentrale Befund der Studie jedoch lautet anders: Die kritischen Entwickler beschreiben AI Slop als eine Tragödie der Allmende. Einzelne Entwickler und Unternehmen profitieren von KI-generiertem Output, doch die kumulativen Kosten tragen Reviewer, Maintainer und die gesamte Gemeinschaft. Codebasen häufen technische Schulden an, Wissensressourcen werden verschmutzt, Reviewer-Kapazitäten erschöpft und das Vertrauen, auf dem kollaborative Entwicklung basiert, erodiert.
Besonders akut ist das Problem laut der Studie in der Open-Source-Welt, wo gemeinsame Ressourcen von Freiwilligen gepflegt werden. Konkrete Fälle illustrierten dies bereits: Das curl-Projekt stellte sein Bug-Bounty-Programm ein, nachdem KI-generierte Schwachstellenberichte Maintainer-Zeit verschlangen, ohne valide Ergebnisse zu liefern. Apache Log4j 2 und die Godot Game Engine berichteten von ähnlichen Problemen.
Entwickler berichteten auch davon, KI-Workflows vom Management aufgezwungen zu bekommen. In einem Fall kopierten C-Level-Führungskräfte KI-Ausgaben direkt als Antwort auf jedes technische Problem des Teams.
Reviewer als unbezahlte Prompt-Ingenieure
Ein dominantes Thema unter den kritischen Stimmen war die Belastung derjenigen, die KI-generierten Code prüfen müssen. "Die Entwicklungszeit wurde verkürzt, aber das Team muss jetzt mehr Zeit für Reviews aufwenden. Sieht nicht nach einem Vorteil aus", wird ein Entwickler zitiert. Ein Team berichtete von 30 Pull Requests pro Tag bei sechs Reviewern.
Reviewer beschrieben das Gefühl, "der erste Mensch zu sein, der diesen Code je zu Gesicht bekommt" und beklagten, zu unbezahlten Prompt-Ingenieuren degradiert zu werden: "Sie benutzen dich buchstäblich, um ihren Job zu machen, also den KI-Slop kritisch zu bewerten und den nächsten Prompt zu liefern."
Für die Erkennung von KI-generiertem Code entwickelten Reviewer eigene Heuristiken. Emojis in Code-Kommentaren gelten als nahezu sicheres Indiz. Weitere Marker sind schrittweise Kommentarmuster, ein aufgeblähter Stil und Unicode-Artefakte.
Das Vertrauen in kollaborative Prozesse leide erheblich, so die Studie. Ein Entwickler beschrieb den Pull-Request eines KI-Agenten: "Ich weiß nicht, wie man irgendetwas davon vertrauen könnte. Kein echtes Verständnis davon, was es tut, es rät nur."
Beunruhigend verhielten sich laut den Berichten auch KI-Agenten. Die Studie beschreibt "Todesschleifen" selbstbewusst-falscher Korrekturen und Fälle, in denen Agenten Tests änderten, damit fehlerhafter Code die Prüfung bestand, statt den Code zu reparieren. In einem Fall "halluzinierte ein KI-Agent externe Services, mockte dann die halluzinierten externen Services" und erzeugte so eine intern kohärente, aber vollständig fiktive Integration.
Jenseits der Codebasen beschrieben manche Entwickler eine Verschlechterung externer Wissensressourcen. "Ich sehe zunehmend Dokumentationen und Tutorials, denen wichtige Informationen und Code-Beispiele fehlen. Oder es ist einfach komplett falsch oder nutzt eine Klasse, die nicht existiert."
Die Studie identifizierte zudem eine Sorge vor kollektiver Skill-Atrophie. Ein Hacker-News-Kommentator beschrieb ein Catch-22: Wenn man ein erfahrener Ingenieur sein muss, um KI sinnvoll einzusetzen, man aber ohne KI erfahren werden musste, wie sollen dann neue erfahrene Ingenieure entstehen? Diese Überlegung betrifft weite Teile der Wissensarbeit.
Gegenmaßnahmen zwischen PR-Limits und Verantwortungsnormen
Die Studie dokumentiert konkrete Gegenstrategien, die Entwickler vorschlagen oder bereits umsetzen: Größenlimits für Pull-Requests bei KI-unterstütztem Code ("weniger als 500 Zeilen pro PR, sonst kein Review"), verpflichtende Selbst-Reviews vor dem Peer-Review, synchrone Code-Walkthroughs, doppelte Code-Reviews mit externen Teams und die Verankerung von Verantwortlichkeit in Leistungsbewertungen.
Die Forscher leiten aus ihren Ergebnissen Empfehlungen für drei Zielgruppen ab. Tool-Entwickler sollten den Fokus von der Codegenerierung auf Verifikation und Review verlagern, etwa durch Unsicherheitsindikatoren und Provenienz-Informationen. Zudem sollten Tools kleinere, inkrementelle Änderungen fördern und ihren Output so strukturieren, dass er leichter inspiziert werden kann.
Teamleiter sollten Bewertungskriterien überdenken, die Output-Volumen betonen, und stattdessen Downstream-Kosten wie Review-Aufwand und Fehlerraten berücksichtigen. Zugleich betont die Studie, dass Entwickler Entscheidungsspielraum darüber behalten sollten, wann und wie sie KI-Tools einsetzen. Teams sollten außerdem verlangen, dass Beitragende ihre Änderungen verstehen und erklären können, gestützt durch Praktiken wie PR-Größenlimits und Code-Walkthroughs.
Für Bildungseinrichtungen empfehlen die Forscher Prüfungsformate wie mündliche Prüfungen oder Live-Coding sowie die Einschränkung von KI-Tools in frühen Kursphasen, damit Studierende zunächst grundlegende Fähigkeiten aufbauen. Funktionierender Output allein sei kein hinreichender Kompetenznachweis.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.