US-Start-up Arcee AI fordert mit offenem 400B-Modell chinesische KI-Labore heraus

Das Start-up Arcee AI hat mit Trinity-Large-Thinking ein offenes Reasoning-Modell veröffentlicht, das bei Agenten-Aufgaben mit Claude Opus konkurrieren soll. Das Unternehmen steckte dafür rund die Hälfte seines gesamten Risikokapitals in das Projekt.
Der Open-Weight-Bereich bei großen Sprachmodellen wird derzeit von chinesischen Laboren wie Qwen, MiniMax und Zhipu AI dominiert. Das US-Start-up Arcee AI will dem mit Trinity-Large-Thinking etwas entgegensetzen, einem Apache-2.0-lizenzierten Reasoning-Modell mit rund 400 Milliarden Parametern, das speziell auf Agenten-Aufgaben zugeschnitten ist. Dank einer Mixture-of-Experts-Architektur sind pro Token nur etwa 13 Milliarden Parameter aktiv, was das Modell trotz seiner Größe effizient bei der Inferenz macht.
Laut Unternehmensangaben trainierte das Team das Basismodell in 33 Tagen auf 2.048 Nvidia-B300-GPUs. Die Kosten von rund 20 Millionen Dollar entsprechen demnach etwa der Hälfte des gesamten bisher eingeworbenen Risikokapitals. "In vielerlei Hinsicht ist es das leistungsstärkste offene Modell, das jemals außerhalb Chinas auf den Markt gebracht wurde", schreibt CTO Lucas Atkins im Blogpost zur Veröffentlichung.
Stark bei Agenten-Aufgaben, schwächer beim allgemeinen Reasoning
Trinity-Large-Thinking erzeugt vor jeder Antwort einen expliziten Denkprozess in speziellen Think-Blöcken. Das Modell ist auf Tool-Calling, mehrstufige Planung und autonome Workflows optimiert.
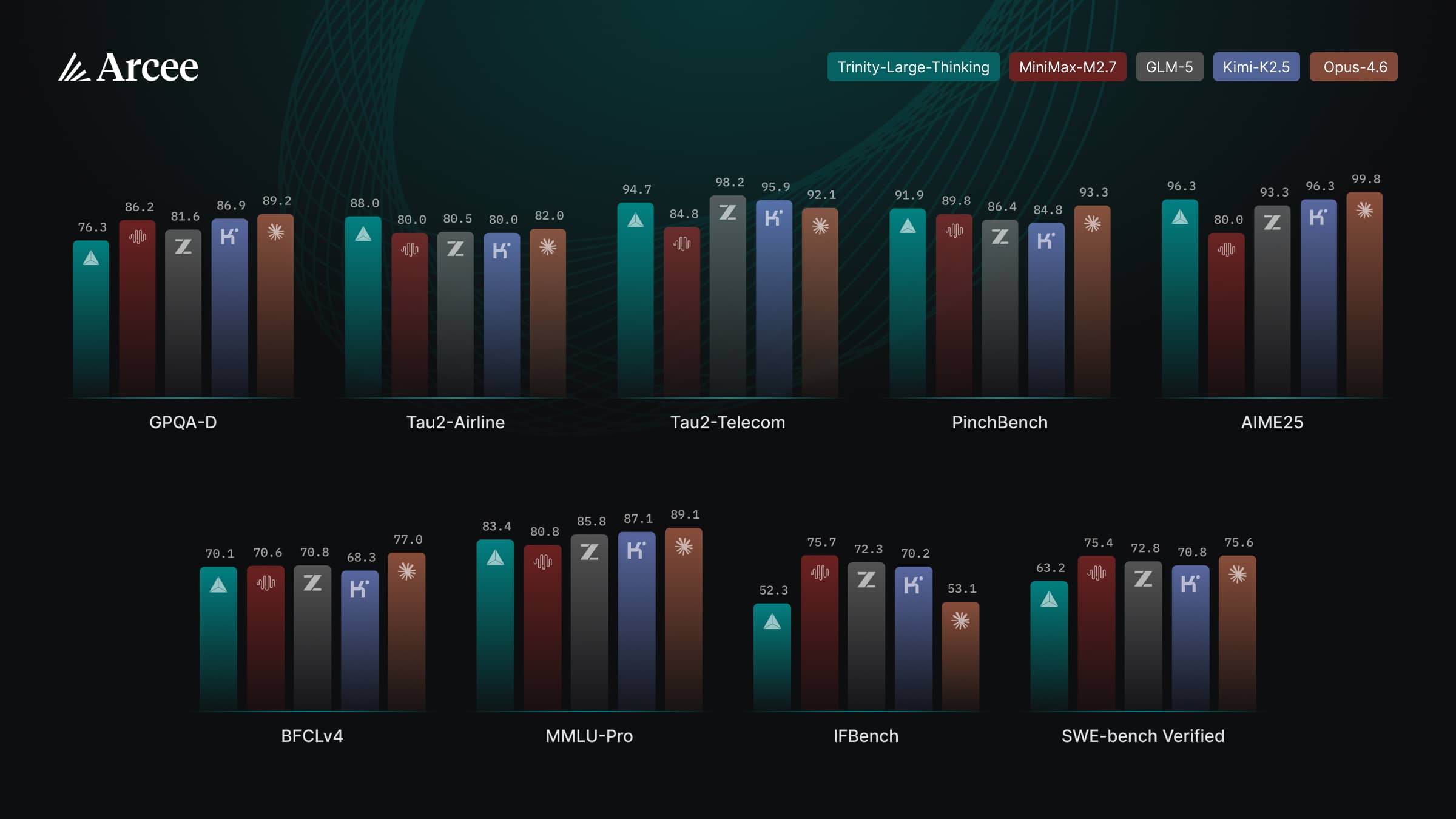
Bei Agenten-Benchmarks liefert es laut der Modellkarte auf Hugging Face starke Ergebnisse: 88 auf Tau2-Airline (Platz 1), 91,9 auf PinchBench (Platz 2, knapp hinter Claude Opus 4.6 mit 93,3) und 96,3 auf AIME25. Bei allgemeinen Reasoning-Benchmarks fällt das Modell allerdings zurück: GPQA-Diamond liegt bei 76,3, MMLU-Pro bei 83,4. Claude Opus 4.6 erreicht hier 89,2 beziehungsweise 89,1.
Nur 4 von 256 Experten pro Token aktiv
Das Modell nutzt eine Mixture-of-Experts-Architektur: Es enthält 256 spezialisierte Teilnetzwerke, von denen pro Token nur vier zum Einsatz kommen. So bleiben rund 13 Milliarden von 400 Milliarden Parametern pro Rechenschritt aktiv. Das spart Rechenleistung, ohne die Gesamtkapazität des Modells zu verringern. Laut dem technischen Report erreicht das Base-Modell damit Benchmark-Ergebnisse, die mit GLM 4.5 konkurrenzfähig sind, obwohl dieses Modell pro Token deutlich mehr Parameter aktiviert.
Für die Verarbeitung langer Texte kombiniert Trinity Large zwei Arten von Attention-Schichten: Lokale Schichten, die jeweils nur einen Ausschnitt des Textes betrachten, wechseln sich mit globalen Schichten ab, die den gesamten Kontext überblicken. Das soll lange Kontextfenster ermöglichen, ohne dass die Rechenkosten proportional steigen. In der Praxis erreicht das Modell ein nutzbares Kontextfenster von 512K Token, obwohl es nur bei 256K trainiert wurde. Auf dem Needle-in-a-Haystack-Test, der prüft, ob ein Modell gezielt platzierte Informationen in langen Texten wiederfindet, erzielte es bei 512K einen Score von 0,976.
Neue Methode löst Experten-Kollaps beim Training
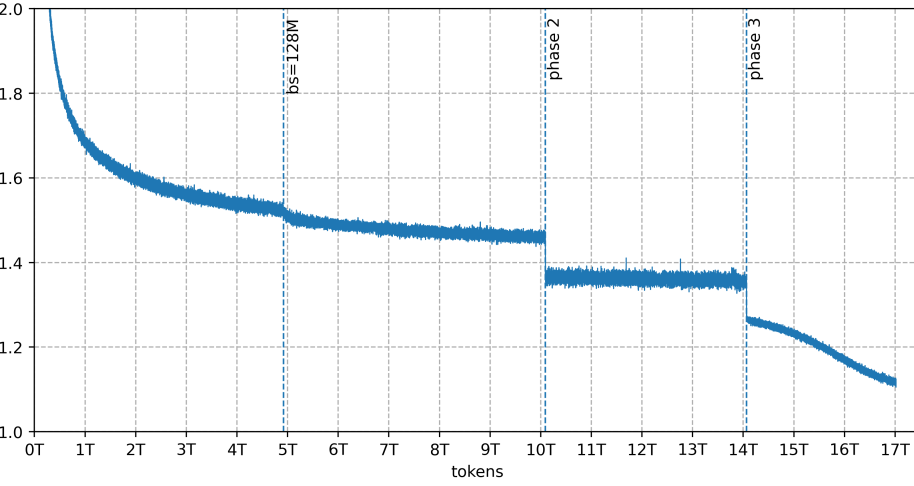
In frühen Trainingsläufen kam es zum Kollaps einzelner Experten. Die Verteilung der Token auf die Teilnetzwerke driftete, einige Experten wurden gar nicht mehr genutzt, und das Modell hörte auf, sich zu verbessern. Das Problem lag laut dem technischen Report an der bisherigen Methode zur Lastverteilung zwischen den Experten. Diese korrigierte Ungleichgewichte immer mit der gleichen festen Schrittgröße, egal ob ein Experte leicht oder massiv überlastet war. Bei 256 Experten führte das zu einem ständigen Hin- und Herpendeln, das sich nie auf einen stabilen Zustand einpendelte.
Das Team entwickelte daraufhin SMEBU (Soft-clamped Momentum Expert Bias Updates), eine neue Methode, die Korrekturen proportional zur tatsächlichen Abweichung vornimmt und sie über die Zeit glättet. Zusammen mit fünf weiteren Stabilisierungsmaßnahmen, die wegen des Zeitdrucks gleichzeitig eingeführt wurden, löste das die Probleme. Danach verlief das gesamte Training stabil, ohne dass der Trainingsverlust ein einziges Mal plötzlich in die Höhe schoss. Solche Ausreißer sind bei großen Modellen ein häufiges und gefürchtetes Problem, das im schlimmsten Fall den gesamten Trainingslauf ruinieren kann.
Mehr als 8 Billionen Token synthetische Trainingsdaten
Ein Großteil der Trainingsdaten ist synthetisch: Mehr als acht der insgesamt 17 Billionen Token wurden künstlich erzeugt, also von anderen KI-Modellen generiert, statt aus dem Internet gesammelt. Darunter sind 6,5 Billionen Token umgeschriebene Web-Texte, etwa 1 Billion Token mehrsprachige Daten und rund 800 Milliarden Token Code. Kuratiert hat die Daten der Partner DatologyAI. Laut dem technischen Report ist dies eine der größten dokumentierten synthetischen Datengenerierungen für das Pretraining.
Die GPU-Cluster stellte Prime Intellect bereit. Da die B300-Systeme zum Zeitpunkt des Trainings brandneu waren, traten wiederholt GPU-Fehler auf, die erst durch Firmware-Updates behoben werden konnten.
Zusätzlich entwickelte das Team ein neues Verfahren für die Aufbereitung der Trainingsdaten: den Random Sequential Document Buffer (RSDB). Normalerweise können besonders lange Dokumente mehrere aufeinanderfolgende Trainingsschritte dominieren und so die Datenverteilung verzerren. RSDB mischt die Dokumente stattdessen zufällig, was laut technischem Report die Schwankungen zwischen einzelnen Trainingsschritten deutlich verringerte.
Hohe Nutzung trotz begrenztem Post-Training
Nach dem eigentlichen Training wurde das Modell in einer zweiten Phase auf spezifische Fähigkeiten wie den Umgang mit Werkzeugen und mehrstufige Aufgaben feinabgestimmt. Diese Phase fiel laut dem technischen Report allerdings kürzer aus als geplant, weil die Rechenzeit auf dem GPU-Cluster begrenzt war. Arcee AI bezeichnet die aktuelle Version daher als vorläufig und plant eine umfangreichere Feinabstimmung für die nächste Iteration.
Die zuvor veröffentlichte Preview-Version wurde in den ersten zwei Monaten auf OpenRouter für 3,37 Billionen Token eingesetzt und war laut Arcee AI eines der meistgenutzten offenen Modelle in den USA auf der Plattform. Die Thinking-Variante ist ebenfalls auf OpenRouter verfügbar und kompatibel mit Agenten-Frameworks wie OpenClaw und Hermes Agent.
Kurz vor Arcee AIs Veröffentlichung stellte auch Google mit Gemma 4 eine neue Familie offener Modelle vor, ebenfalls unter Apache-2.0-Lizenz und teils mit Mixture-of-Experts-Architektur.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.