Zhipu AIs GLM-5.1 soll Linux-Desktop innerhalb von 8 Stunden gebaut haben
Kurz & Knapp
- Zhipu AI hat mit GLM-5.1 ein frei verfügbares Modell veröffentlicht, das auf komplexe, langwierige Programmieraufgaben spezialisiert ist und bei einem anspruchsvollen Software-Engineering-Benchmark knapp vor GPT-5.4 und Claude Opus 4.6 liegt.
- Das Modell soll sich von der Konkurrenz dadurch abheben, dass es bei schwierigen Aufgaben nicht in Sackgassen stecken bleibt, sondern seine eigene Lösungsstrategie wiederholt überprüft und grundlegend wechselt, wenn es nicht weiterkommt.
- Bei Reasoning und Wissensaufgaben fällt GLM-5.1 gegenüber Modellen von Google und OpenAI ab. Zhipu AI bezeichnet das Modell selbst als einen ersten Schritt und benennt offen, woran es noch arbeiten muss.
Zhipu AI hat sein neues Modell GLM-5.1 unter MIT-Lizenz veröffentlicht. Das Modell soll bei Coding-Aufgaben über Hunderte Iterationen hinweg seine eigene Strategie stetig optimieren können.
Zhipu AI hat mit GLM-5.1 ein neues Open-Weight-Modell vorgestellt, das laut dem Unternehmen auf langwierige, agentenbasierte Programmieraufgaben zugeschnitten ist. Die zentrale These: Bisherige Modelle, einschließlich des eigenen Vorgängers GLM-5, erschöpfen ihr Repertoire bei komplexen Aufgaben zu schnell. Sie wenden bekannte Lösungsstrategien an, erzielen anfangs Fortschritte und kommen dann nicht weiter. Mehr Rechenzeit ändere daran nichts.
GLM-5.1 soll laut Zhipu AI dieses Problem lösen, indem es seine eigene Strategie wiederholt überprüft, Sackgassen erkennt und neue Ansätze verfolgt. Das Unternehmen spricht von Optimierung über "Hunderte von Runden und Tausende von Tool-Aufrufen".
Zhipu AI demonstriert das anhand von drei Szenarien, die allerdings allesamt vom Hersteller selbst durchgeführt wurden. Unabhängige Evaluierungen gibt es bislang nicht.
Modell wechselt laut Zhipu AI seine eigene Strategie
Im ersten Szenario musste GLM-5.1 eine Vektordatenbank optimieren, also ein System, das große Datenmengen durchsucht und ähnliche Einträge findet. Die Aufgabe: möglichst viele Suchanfragen pro Sekunde beantworten, ohne an Genauigkeit zu verlieren. In einem standardmäßigen Testlauf mit 50 Durchgängen hatte Claude Opus 4.6 laut Zhipu AI bisher den Bestwert von 3.547 Anfragen pro Sekunde erzielt.
Zhipu AI gab GLM-5.1 stattdessen unbegrenzt viele Versuche. Das Modell entschied selbst, wann es eine neue Version einreichte und was es als Nächstes ausprobierte. Nach über 600 Iterationen und mehr als 6.000 Tool-Aufrufen erreichte es laut dem Unternehmen 21.500 Anfragen pro Sekunde, rund das Sechsfache des bisherigen Bestwerts.
Das Modell wechselte dabei laut Zhipu mehrfach grundlegend die Strategie. Um Iteration 90 etwa stellte es von einer vollständigen Durchsuchung aller Daten auf ein effizienteres Cluster-Verfahren um. Um Iteration 240 führte es eine zweistufige Pipeline ein, die grob vorsortiert und dann präzise nachfiltert. Sechs solcher strukturellen Umbrüche identifiziert das Unternehmen über den gesamten Lauf, jeweils vom Modell selbst eingeleitet.
GPU-Optimierung: Fortschritt, aber nicht an der Spitze
Im zweiten Szenario sollte das Modell bestehenden Machine-Learning-Code so umschreiben, dass er auf Grafikkarten schneller läuft. Hier erreicht GLM-5.1 laut Zhipu AI eine 3,6-fache Beschleunigung gegenüber der Standardimplementierung und macht auch in späten Phasen noch Fortschritte. GLM-5 hingegen stagniert deutlich früher.
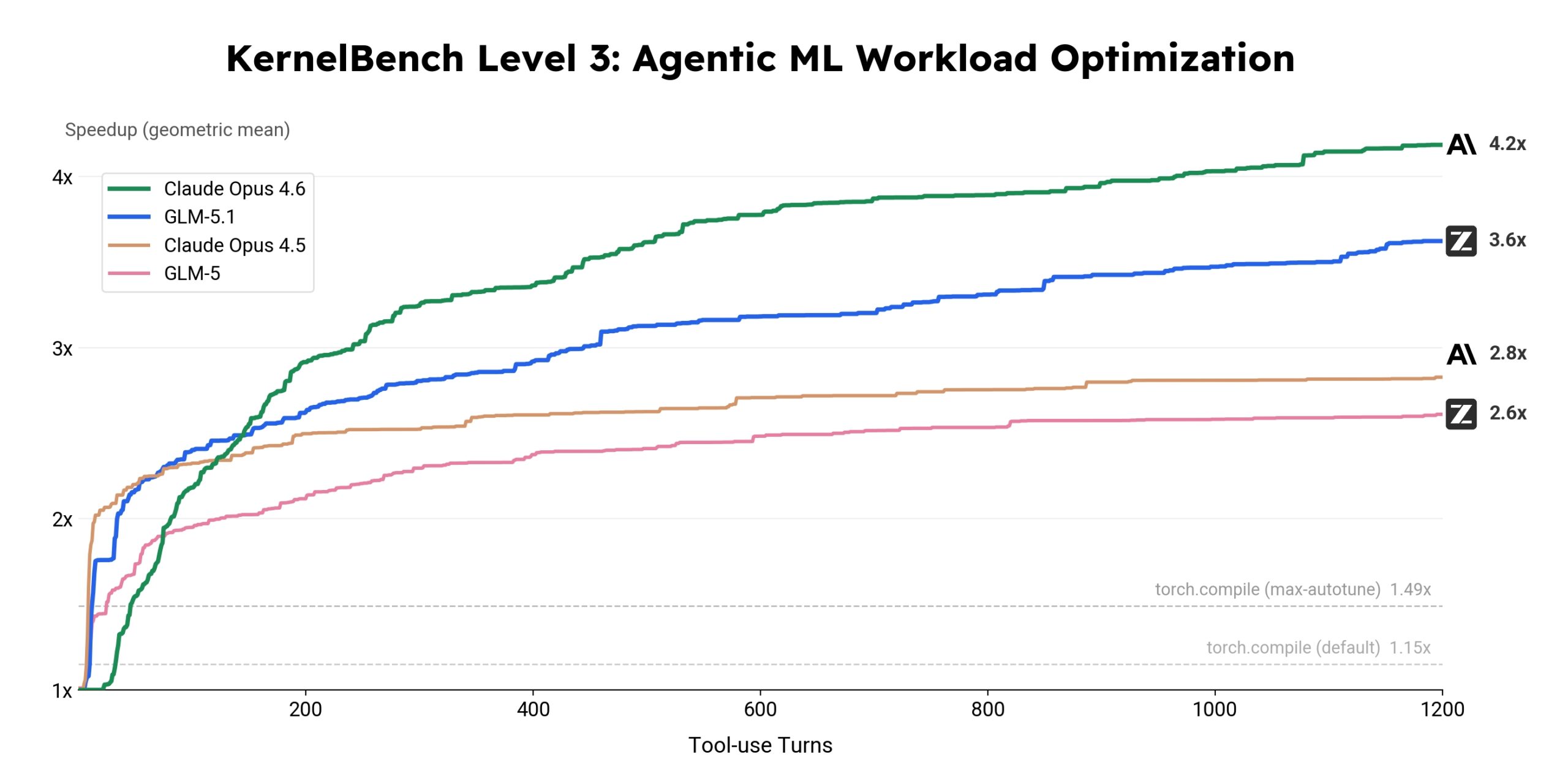
Claude Opus 4.6 bleibt in diesem Test allerdings mit 4,2-facher Beschleunigung klar vorn und zeigt am Ende noch Spielraum. GLM-5.1 erweitert den produktiven Horizont gegenüber seinem Vorgänger, schließt die Lücke zum stärksten Konkurrenten aber nicht.
Linux-Desktop aus einem Prompt
Das dritte Szenario ist das ungewöhnlichste. GLM-5.1 sollte eine vollständige Linux-Desktop-Umgebung als Webanwendung bauen, ohne Startercode oder Zwischenanweisungen. Die meisten Modelle liefern laut Zhipu AI ein Grundgerüst mit Taskleiste und ein paar Platzhalter-Fenstern und erklären die Aufgabe dann für erledigt.
GLM-5.1 wurde in eine Schleife gesetzt, in der es nach jeder Runde seine eigene Ausgabe begutachtete und selbst entschied, was noch fehlt oder verbessert werden muss. Nach acht Stunden entstand laut dem Unternehmen eine funktionsfähige Desktop-Umgebung mit Dateibrowser, Terminal, Texteditor, Systemmonitor, Rechner und Spielen.
Coding-Stärke, Reasoning-Schwäche
Abseits der drei Demonstrationen veröffentlicht Zhipu AI eine Benchmark-Tabelle, die ein differenzierteres Bild zeichnet. Beim Coding liegt GLM-5.1 in mehreren Tests vorn oder auf Augenhöhe mit der Konkurrenz. Auf SWE-Bench Pro, einem Software-Engineering-Test, erzielt es laut Zhipu AI mit 58,4 Prozent den höchsten Wert aller frei verfügbaren getesteten Modelle, knapp vor GPT-5.4 mit 57,7 Prozent und Claude Opus 4.6 mit 57,3 Prozent. Bei CyberGym, einem Cybersecurity-Benchmark, erzielt es mit 68,7 den höchsten Wert. Zhipu AI räumt allerdings ein, dass Gemini 3.1 Pro und GPT-5.4 bei einigen Aufgaben die Ausführung aus Sicherheitsgründen verweigerten, was deren Ergebnisse gedrückt haben dürfte.
Auf Humanity's Last Exam, einem Wissenstest, liegt das Modell mit 31 Prozent hinter Gemini 3.1 Pro mit 45 und GPT-5.4 mit 39,8. Auch bei wissenschaftlichen Fragen (GPQA-Diamond) liegt das Modell mit 86,2 hinter Gemini 3.1 Pro mit 94,3 und GPT-5.4 mit 92.
Bei agentenbasierten Aufgaben ist das Bild ebenfalls gemischt: Im Vending Bench 2, bei dem ein Modell ein simuliertes Automatengeschäft betreiben muss, erwirtschaftet GLM-5.1 einen Kontostand von 5.634 Dollar. Claude Opus 4.6 kommt auf 8.018 Dollar, also deutlich mehr. Bei der Repository-Generierung (NL2Repo) liegt Claude Opus 4.6 mit 49,8 ebenfalls klar vor GLM-5.1 mit 42,7.
Im Artificial Analysis Intelligence Index liegt das Modell aktuell knapp hinter Anthropics Claude 4.6 Sonnet.
Zhipu AI selbst benennt offene Herausforderungen: Das Modell müsse lernen, Sackgassen früher zu erkennen, die Kohärenz über Tausende von Tool-Aufrufen zu wahren und sich bei Aufgaben ohne klare Metriken zuverlässig selbst einzuschätzen. GLM-5.1 sei ein "erster Schritt" in diese Richtung.
Das Modell steht unter MIT-Lizenz auf Hugging Face und ModelScope zum Download bereit und ist über die API-Plattformen api.z.ai und BigModel.cn nutzbar. Es lässt sich in Coding-Agenten wie Claude Code und OpenClaw einbinden. Für lokales Deployment unterstützt Zhipu AI die Inferenz-Frameworks vLLM und SGLang. Anleitungen stehen im GitHub-Repository. Über die Chatoberfläche Z.ai soll GLM-5.1 in den kommenden Tagen verfügbar werden.
Zhipu AI baut Modellpalette schnell aus
Vor kurzem hatte Zhipu AI mit GLM-5V-Turbo ein multimodales Coding-Modell vorgestellt, das aus Bildern und Video direkt Code generiert. Davor veröffentlichte das Unternehmen im Februar GLM-5, ein Open-Weight-Modell mit 744 Milliarden Parametern, das bei Coding-Aufgaben mit führenden proprietären Modellen mithalten sollte. GLM-5.1 dürfte auf diesen beiden Modellen aufbauen und ergänzt die Modellfamilie um die Long-Horizon-Fähigkeiten, mit denen sich Zhipu AI von der chinesischen Konkurrenz absetzen will. Denn der Wettbewerb unter den chinesischen KI-Laboren bleibt intensiv: Neben Zhipu AI machen sich auch Moonshot AI mit Kimi K2.5 und Alibaba mit Qwen3.5 auf dem Markt für autonome Coding-Agenten breit.
Zhipu AI ist nicht das einzige Unternehmen, das auf ausdauernde KI-Agenten setzt. Anfang 2026 ließ Cursor Hunderte GPT-5.2-Agenten eine Woche lang einen Webbrowser bauen. Die über drei Millionen Zeilen Rust-Code erwiesen sich laut einer Analyse der Software Improvement Group allerdings als kaum wartbar und landeten in den unteren fünf Prozent aller bewerteten Softwaresysteme.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren