Nächste Studie verpasst Hype um "Agent Skills" einen Dämpfer

KI-Agenten sollen durch sogenannte Skills zusätzliches Fachwissen abrufen können. Eine Studie mit 34.000 realen Skills zeigt nun: Unter praxisnahen Bedingungen bringen die Erweiterungen kaum Vorteile. Schwächere Modelle werden sogar schlechter.
Erstmals eingeführt wurden Skills im Oktober 2025 von Anthropic als modulares System für Claude Code, bei dem der Agent selbstständig erkennt, welche spezialisierten Anleitungen für eine Aufgabe benötigt werden. Andere Plattformen wie OpenAIs Codex und zahlreiche Open-Source-Projekte adaptierten das Konzept schnell.
Skills sind strukturierte Textdateien, die domänenspezifisches Wissen wie Workflows, API-Nutzungsmuster und Best Practices kodieren. Agentische KI-Systeme können während der Aufgabenbearbeitung auf diese Dateien zugreifen und die darin beschriebenen Vorgehensweisen auf ihre aktuelle Aufgabe anwenden. Doch wie nützlich sind Skills tatsächlich, wenn Agenten sie selbst finden und anwenden müssen?
Bisherige Benchmarks zeichnen ein zu optimistisches Bild
Laut einer neuen Studie von Forschern der UC Santa Barbara, des MIT CSAIL und des MIT-IBM Watson AI Lab ist die Antwort ernüchternd: Die Vorteile von Skills sind "fragil" und schrumpfen drastisch, sobald die Testbedingungen realistischer werden. In den anspruchsvollsten Szenarien nähern sich die Ergebnisse der Baseline ohne jegliche Skills an.
Das Problem liegt laut den Forschern in der Art, wie Skills bisher getestet wurden. Der bestehende Benchmark SKILLSBENCH stellt Agenten handkuratierte, aufgabenspezifische Skills direkt zur Verfügung, die praktisch eine Schritt-für-Schritt-Anleitung für die jeweilige Aufgabe darstellen.
Ein Beispiel aus der Studie verdeutlicht das: Eine Aufgabe verlangt, Überschwemmungstage an USGS-Messstationen zu identifizieren. Die drei bereitgestellten Skills enthalten die exakte API zum Herunterladen von Wasserstandsdaten, die konkrete URL für Hochwasser-Schwellenwerte und fertige Code-Snippets zur Erkennung von Überschwemmungstagen. "Diese Skills buchstabieren im Grunde die exakte Lösungsanleitung für die Aufgabe", stellen die Forscher fest.

In der Praxis hat ein Agent jedoch weder vorgefertigte Skills noch eine Garantie, dass passende Skills überhaupt existieren. Er muss relevante Skills aus großen, verrauschten Sammlungen selbst finden und allgemeine Skills an spezifische Aufgaben anpassen.
34.000 reale Skills als Testgrundlage
Für ihre Studie stellten die Forscher eine Sammlung von 34.198 realen Skills aus Open-Source-Repositories zusammen, gefiltert nach permissiven Lizenzen (MIT und Apache 2.0) und dedupliziert. Die Skills stammen von den Aggregationsplattformen skillhub.club und skills.sh und decken Bereiche von Webentwicklung über Data Engineering bis hin zu wissenschaftlichem Rechnen ab.
Darauf aufbauend testeten die Forscher sechs progressiv realistischere Szenarien: von der direkten Bereitstellung kuratierter Skills über das Hinzufügen von Distraktoren bis hin zur vollständig eigenständigen Suche des Agenten in der gesamten Sammlung, sowohl mit als auch ohne die kuratierten Skills im Pool.
Getestet wurden drei Modelle: Claude Opus 4.6 mit Claude Code, Kimi K2.5 mit Terminus-2 und Qwen3.5-397B-A17B mit Qwen-Code. Jedes Modell durchlief die gesamte Pipeline eigenständig, einschließlich Skill-Retrieval und Aufgabenlösung.
Leistung bricht stufenweise ein
Die Ergebnisse zeigen einen konsistenten Verfall über alle Modelle hinweg. Claude Opus 4.6 erreichte mit erzwungenem Laden kuratierter Skills eine Pass-Rate von 55,4 Prozent. Sobald der Agent selbst entscheiden musste, welche Skills er lädt, fiel die Rate auf 51,2 Prozent. Mit Distraktoren sank sie auf 43,5 Prozent, bei eigenständiger Suche auf 40,1 Prozent und ohne kuratierte Skills im Pool auf 38,4 Prozent. Die Baseline ohne Skills lag bei 35,4 Prozent.
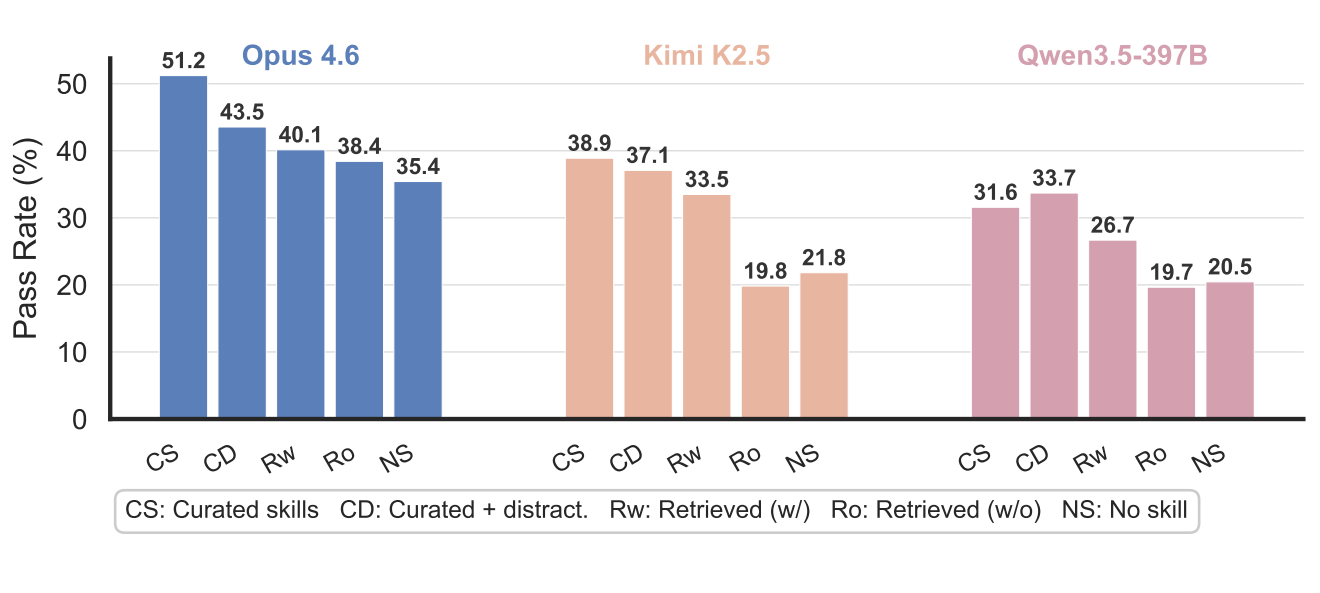
Bei schwächeren Modellen ist das Bild noch drastischer: Kimi K2.5 fiel im realistischsten Szenario auf 19,8 Prozent, also unter seine eigene No-Skill-Baseline von 21,8 Prozent. Qwen3.5-397B zeigte dasselbe Muster mit 19,7 Prozent gegenüber 20,5 Prozent ohne Skills. Irrelevante Skills können schwächere Modelle demnach aktiv in die Irre führen, indem sie Ressourcen auf das Laden und Befolgen nutzloser Anweisungen verschwenden.
Drei Engpässe: Auswahl, Suche, Anpassung
Die Forscher identifizieren drei zentrale Engpässe. Erstens versagen Agenten bereits bei der Auswahl: Selbst wenn kuratierte Skills direkt verfügbar sind, laden nur 49 Prozent der Claude-Durchläufe alle kuratierten Skills. Mit Distraktoren sinkt dieser Wert auf 31 Prozent.
Interessanterweise zeigt Kimi deutlich höhere Laderaten von 86 Prozent im kuratierten Setting, was die Forscher auf den Einfluss der jeweiligen Agentenumgebung zurückführen. Die höhere Laderate schlägt sich bei Kimi allerdings nicht in besserer Aufgabenleistung nieder.
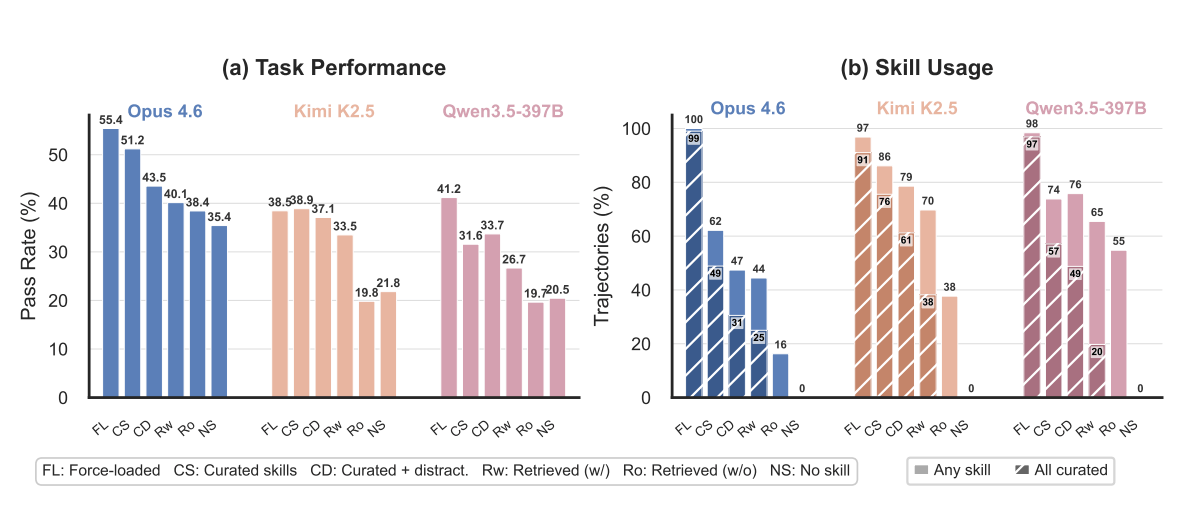
Zweitens verschlechtert die eigenständige Suche die Ergebnisse weiter, da selbst die beste Retrieval-Methode nur 65,5 Prozent Recall@5 erreicht. Drittens scheitern Agenten daran, allgemeine Skills an spezifische Aufgaben anzupassen, wenn keine maßgeschneiderten Skills existieren.
Für die Skill-Suche selbst verglichen die Forscher verschiedene Retrieval-Strategien. Die beste Methode war eine "Agentic Hybrid Search", bei der der Agent iterativ Suchanfragen formuliert, Kandidaten inspiziert und seine Strategie verfeinert. Diese übertraf eine einfache semantische Direktsuche um 18,7 Prozentpunkte bei Recall@3.
Verfeinerung hilft, aber nur, wenn die Grundlage stimmt
Um die Leistungslücke zu schließen, untersuchten die Forscher zwei Verfeinerungsstrategien. Bei der aufgabenspezifischen Verfeinerung exploriert der Agent die Aufgabe, versucht eine erste Lösung, reflektiert über die Nützlichkeit der gefundenen Skills und synthetisiert daraus neue, maßgeschneiderte Skills. Bei einer Tensor-Parallelismus-Aufgabe etwa kombinierte der Agent Konzepte aus zwei verschiedenen Skills zu einem neuen Skill, den keiner der ursprünglichen allein bot.
Die Ergebnisse sind deutlich: Claude stieg auf SKILLSBENCH von 40,1 auf 48,2 Prozent. Auf dem allgemeinen agentischen KI-Benchmark TERMINAL-BENCH 2.0 verbesserte die aufgabenspezifische Verfeinerung Claude von 61,4 auf 65,5 Prozent. Der Vergleich von 57,7 auf 65,5 Prozent beschreibt den kombinierten Effekt von Skill-Retrieval und Verfeinerung gegenüber der No-Skill-Baseline.
Die aufgabenunabhängige Verfeinerung, bei der Skills offline ohne Kenntnis der Zielaufgabe verbessert werden, lieferte dagegen nur inkonsistente Verbesserungen. Die Forscher schließen daraus, dass Verfeinerung eher als Multiplikator vorhandener Skill-Qualität wirkt als als Generator neuen Wissens: Sie hilft primär dann, wenn die zunächst gefundenen Skills bereits relevante Informationen enthalten.
Bereits frühere Tests zeigten Schwächen des Skill-Systems
Die neuen Ergebnisse decken sich mit einer früheren Untersuchung von Vercel, die ein grundlegendes Problem des Skill-Ansatzes offenlegte: In 56 Prozent der Testfälle rief der Agent den verfügbaren Skill schlicht nicht ab. Die Pass-Rate mit Skills entsprach dort exakt der Baseline ohne Dokumentation. Eine simple Markdown-Datei (AGENTS.md), die dem Agenten passiv als Kontext bereitgestellt wurde, erreichte dagegen eine perfekte Erfolgsrate von 100 Prozent, während das Skill-System bei maximal 79 Prozent stagnierte.
Die aktuelle Studie bestätigt dieses Kernproblem nun systematisch über mehrere Modelle hinweg und in größerem Maßstab: Agenten erkennen verfügbare Skills häufig nicht als relevant und laden sie nicht.
Das Forschungsteam fordert bessere Retrieval-Methoden, effektivere Offline-Verfeinerungsstrategien und Skill-Ökosysteme, die unterschiedliche Modellfähigkeiten berücksichtigen, um das Potenzial von Skills besser zu heben. Der Code der Studie ist auf GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.