MLPerf: Nvidia Hopper GPU räumt mit der Konkurrenz auf

Nvidias Hopper H100 GPU gibt ihr Debüt im MLPerf-Benchmark. Der KI-Beschleuniger lässt dabei die Konkurrenz weit hinter sich. Doch auch Qualcomm zeigt sich stark.
Im MLPerf-Benchmark treten Hardware-Hersteller und Dienstleister mit ihren KI-Systemen gegeneinander an. Der Test wird von MLCommons geleitet und zielt auf einen transparenten Vergleich verschiedener Chip-Architekturen und Systemvarianten.
MLPerf veröffentlicht jedes Jahr unterschiedliche Ergebnisse, einmal für das Training und einmal für die Inferenz von KI-Modellen. Nun sind die Ergebnisse des diesjährigen "MLPerfTM Inference v2.1"-Benchmark veröffentlicht worden.
Mit 21 Teilnehmenden, 5.300 Performance-Ergebnissen, 2.400 Energiemessungen, einer neuen Division, einem neuen Objekterkennungs-Modell (RetinaNet) und einer neuen Nvidia GPU stellt die jüngste Runde neue Bestwerte auf.
Nvidias Hopper GPU erreicht Rekordwerte
Im MLPerf-Benchmark nimmt Nvidia als einziger Hersteller an allen sechs Modelltests (ResNet-50, RetinaNet, RNN-T, BERT-Large 99 %, BERT-Large 99,9 %, DLRM) teil. In der Preview-Kategorie zeigt zum ersten Mal auch Nvidias Hopper-GPU H100, was sie kann. Sie soll Ende des Jahres verfügbar sein.
Nvidia stellte die neue Hopper-GPU H100 im März vor. Die für KI-Berechnungen gebaute GPU ist Nachfolger von Nvidias A100 und setzt auf TSMCs 4-nm-Prozess und HBM3-Speicher. Die H100-GPU kommt mit 80 Milliarden Transistoren, liefert 4,9 Terabyte Bandbreite pro Sekunde und setzt auf PCI-Express Gen5.
Nvidia verspricht deutlich schnellere Inferenz gegenüber der A100. Für FP32 liefert die H100-GPU 1.000 TeraFLOP Leistung, für FP16 2.000 TeraFLOP. Zusätzlich kommt die H100 mit einer neuen Transformer-Engine, in der die vierte Generation Tensor-Kerne mit spezialisierter Software dynamisch zwischen FP8- und FP16-Präzision wechseln. Damit sollten sich speziell große Sprachmodelle deutlich schneller trainieren lassen.
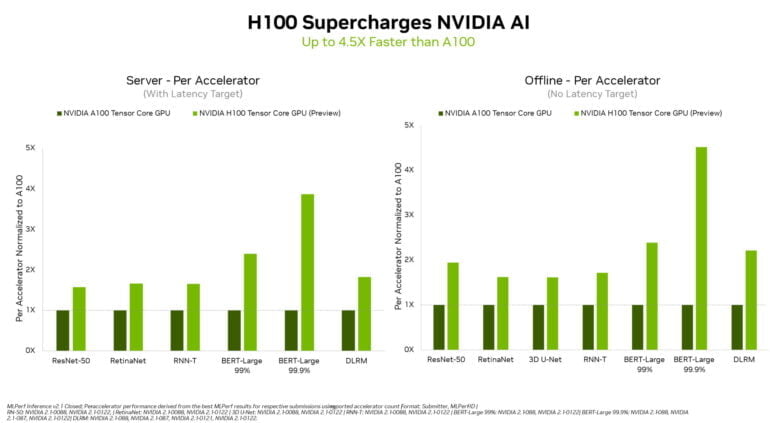
In den nun veröffentlichten Ergebnissen schiebt sich Nvidias neue GPU deutlich vor die A100 und alle anderen Teilnehmenden. Je nach Benchmark erreicht die H100 eine bis zu 4,5-fach höhere Geschwindigkeit als A100-basierte Systeme.
Dieser Sprung ist auch durch die Transformer Engine möglich, die die Genauigkeit etwa in der Inferenz von BERT-Large intelligent wechselt. Weitere Leistungssprünge der H100 in zukünftigen Benchmarks sind möglich: Nvidia hat durch Softwareverbesserungen die Leistung der A100 seit dem ersten Eintrag in MLPerf um das 6-fache erhöht.
Qualcomm holt auf, Intel gibt ersten Einblick
Die erfolgreiche A100 GPU hält derweil immer noch in nahezu allen Kategorien ihren Vorsprung vor den Produkten anderer Hersteller. Einzige Ausnahme ist Qualcomms CLOUD AI 100 Beschleuniger, der sich trotz geringen Stromverbrauchs in einzelnen Kategorien bei ResNet-50 und BERT-Large 99,9 % vor Nvidias A100 schieben konnte.
Abseits der A100 ging Nvidia jedoch auch mit Orin ins Rennen, ebenfalls ein SoC mit geringem Stromverbrauch. Anders als Qualcomms Chip trat Orin in allen Benchmarks für Edge-Computing an und gewann so insgesamt die meisten Benchmarks bei einer im Vergleich zum Debüt im April 50 Prozent höheren Energieeffizienz.
Neben Nvidia und Qualcomm zeigte Intel einen ersten Einblick in Sapphire Rapids, Intels erstes Chiplet-Design für Server-CPUs. Zudem nahmen die KI-Startups Biren, Moffet AI, Neural Magic und Sapeon am Benchmark teil.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.