AudioGen: Meta-KI erzeugt Audio aus Text

AudioGen ist das nächste Text-zu-X-Projekt: Das KI-System erzeugt zu Texteingaben passende Klänge.
Forschende von Meta AI und der hebräischen Universität Jerusalem stellen AudioGen vor: ein Transformer-basiertes generatives KI-Modell, das Audio von Grund auf neu passend zu Texteingaben generiert oder bestehende Audio-Eingaben verlängern kann.
Das Pfeifen im Walde - während Vögel singen und Hunde bellen
Das KI-Modell löst laut der Forschenden dabei komplexe Probleme der Audiogenerierung. Es kann unter anderem verschiedene Objekte unterscheiden und akustisch voneinander trennen, wenn zum Beispiel mehrere Personen gleichzeitig sprechen. Zudem kann es Hintergrundgeräusche wie Hall nachstellen.
Um dem Modell diese Fähigkeiten anzutrainieren, verwendeten die Forschenden in der Lernphase eine Augmentationstechnik, die verschiedene Audiosamples mischt. Das Modell lernte so, mehrere Quellen zu trennen. Insgesamt stellten die Forschenden zehn Datensätze mit Audio und passenden Textannotationen zusammen.
In der Folge kann AudioGen anhand von Textbeschreibungen neue Audiokompositionen erstellen, die in dieser Zusammenstellung nicht Teil des Trainingsmaterials waren, also etwa eine Person, die pfeifend durch den Wald spaziert, während im Hintergrund Vögel zwitschern.
Video: Kreuk et al.
Das System kann laut des Erstautors Felix Kreuk auch Musik generieren und sogar singen, ist dafür aber nicht ausgelegt und bietet derzeit wenig Kontrolloptionen.
Modell-Veröffentlichung in Planung
Das Forschungsteam ließ die Ergebnisse von AudioGen über Amazons Mechanical-Turk-Plattform von Menschen evaluieren. Sie bewerteten die Audioqualität ebenso wie das Zusammenpassen von Text und Audio, also die Relevanz. Mehr als 85 Prozent der 100 zufällig ausgewählten Audiobeispiele enthielten dabei mindestens zwei Konzepte, also beispielsweise "Ein Hund bellt, während ein Vogel singt".
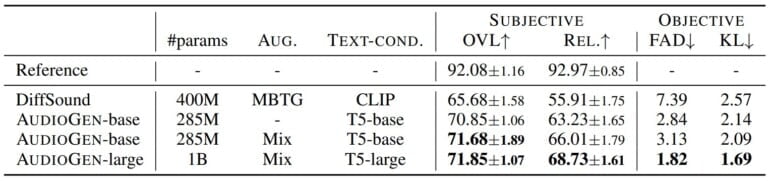
Die Tester:innen bewerteten die Audiobeispiele auf einer Skala von 1 bis 100. Insgesamt ließ das Forschungsteam vier Modelle bewerten, darunter das CLIP-basierte DiffSound mit 400 Millionen Parametern und drei T5-basierte AudioGen mit 285 Millionen bis eine Milliarde Parameter.
Das größte AudioGen-Modell erzielte dabei bei Qualität (rd. 72 Punkte) und Relevanz (rd. 68 Punkte) die höchsten Bewertungen mit einem deutlichen Abstand zu Diffsound (rd. 66 / 55 Punkte).
AudioGen versteht das Forschungsteam als ersten Aufschlag für bessere Text-Audio-Modelle in der Zukunft. Die Technologie könne zudem semantische Audiobearbeitung ermöglichen oder die Trennung von Audioquellen aus diskreten Einheiten unterstützen. Eine Veröffentlichung des Modells ist laut Kreuk in Planung.
Mitte September stellte Google AudioLM vor, das ebenfalls die Techniken großer Sprachmodelle verwendet, um etwa gesprochene Sätze zu vollenden und vollständig neues Audio zu generieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.