Datensatz-Suchmaschine soll Transparenz großer Sprachmodelle fördern

Bei der Analyse der Trainingstexte des Open-Source-Sprachmodells Bloom sind sensible Daten und rassistische Beleidigungen aufgetaucht. Ein Datensatz-Such-Tool soll die Transparenz zukünftiger Modelle verbessern.
"Warum sagen LMs (Language Models, also: Sprachmodelle), was sie sagen? Wir wissen es oft nicht - aber vielleicht bekommen wir jetzt eine bessere Vorstellung davon." Mit diesen Worten kündigt NLP-Forscherin Aleksandra "Ola" Piktus ihr jüngstes Projekt auf Twitter an.
In Zusammenarbeit mit Hugging Face hat die Wissenschaftlerin die Suchmaske "Roots" für das Open-Source-Modell Bloom veröffentlicht, mit dem sich die zugrundeliegende Datenbank mit 176 Milliarden Parametern in 59 Sprachen durchsuchen lässt.
Bloom ist im Juli 2022 gestartet und eine mögliche Open-Source-Alternative zu GPT-3 von OpenAI, insbesondere wegen des frei zugänglichen und mehrsprachigen Charakters.
Why do LMs say what they say? We often don't know - but now we might get a better idea.
My first project with @huggingface, the ROOTS search tool goes live today🤗🌸It allows anyone to browse through the 1.6TB of the corpus behind @BigScience’s BLOOM https://t.co/gMW3BvNisp🚀🧵 pic.twitter.com/4AqYflC5gP
— Ola Piktus (@olapiktus) October 28, 2022
Tool soll Messlatte "für die nächste Generation" Sprachmodell höher setzen
Die Möglichkeit, Trainingsmaterial ohne Coding-Kenntnisse zu durchsuchen, sei notwendig, um ein gemeinsames Verständnis häufiger Probleme aufzubauen und die Messlatte für die nächste Generation Sprachmodelle höher zu legen, so Piktus.
Mithilfe der Roots-Suchmaschine seien bereits sensible Daten von Privatpersonen, Sprachkontamination und Fake News gefunden worden. Eine Frau fand mit einer ähnlichen Suchmaschine für KI-Trainingsbilder zuvor Fotos aus ihrer Krankenakte im Datensatz.
Roots durchsucht 1,6 TB an Textdaten in 46 natürlichen und 13 Programmiersprachen. Die Analyse von Piktus zeigt: Die einzelnen Datenpunkte unterscheiden sich drastisch in ihrer Länge. Um sie aber vergleichen und einordnen zu können, hat sie diese in gleich große Passagen von 128 Wörtern aufgeteilt und jedem eine eindeutige ID zugewiesen.
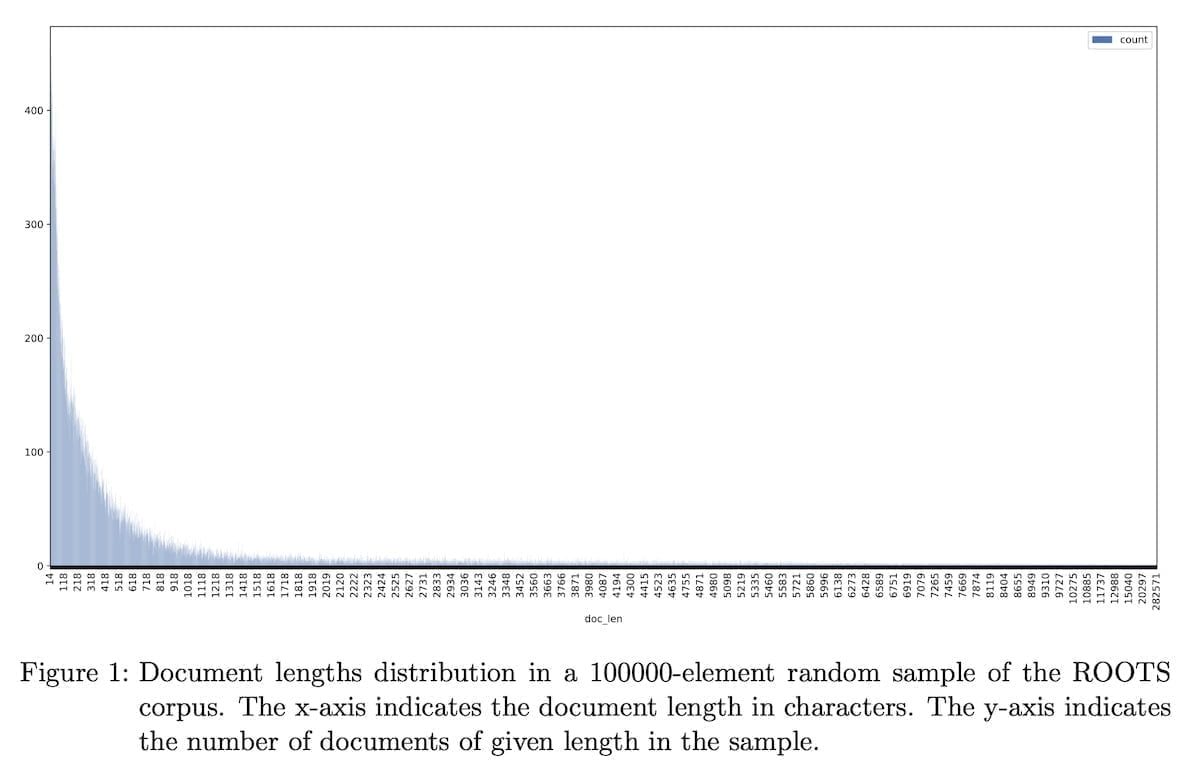
Sensible Daten sind geschwärzt statt entfernt
Der Datensatz OSCAR ist Piktus als Quelle besonders vieler persönlicher Daten aufgefallen. Damit diese nicht durch die Suchmaschine an die Öffentlichkeit gelangen, wird ein Skript angewandt, die die Ergebnisse schwärzt.
"Auf diese Weise kann man die Daten einsehen und das Problem beobachten, aber persönliche Informationen werden überwiegend entfernt", heißt es im begleitenden Papier.

Rassismus und Hassrede kommt unter anderem aus Filmuntertiteln
Die beteiligten Wissenschaftler:innen hätten zudem Anzeichen für "minderwertige Texte" beobachtet, etwa rassistische Beleidigungen, sexuell eindeutige Sprache oder Hassreden, die häufig aus Datensätzen mit Filmuntertiteln stammen würden.
Während Menschen diese Form der Sprache, die meistens bewusst eingesetzt werde, im Kontext einordnen könnten, übernehme sie ein Sprachmodell ohne Einordnung, so die Forscherin.
Die aktuelle Version des Tools sei stark von der Benutzerführung populärer Suchmaschinen beeinflusst. Für die Zukunft sei geplant, mehr quantitative Informationen wie die Häufigkeit bestimmter Begriffe, die Anzahl der Treffer oder Co-Occurrence-Statistiken anzuzeigen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.